01_Spark基础
1.1、Spark Ecosystem

BlinkDB: 允许用户定义一个错误范围,BlinkDB将在用户给定的错误范围内,尽可能快的提供查询结果
1.2、Spark愿景
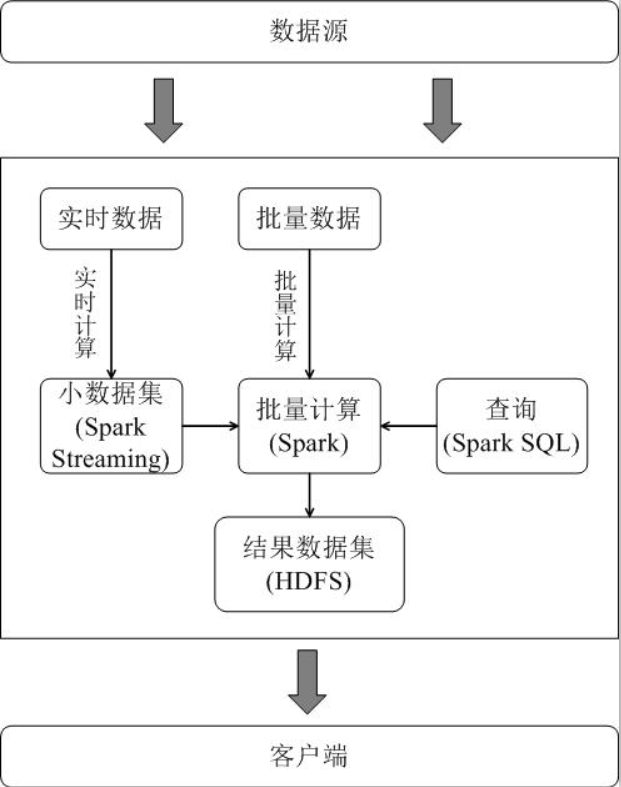
1.3、Spark简介
1)加州大学伯克利分校AMP实验室(Algorithms, Machines, and People lab), 内存并行计算框架(computing system)
2)2013年6月,Apache孵化项目
3)8个月后,Apache顶级项目
4)围绕着Spark,推出了Spark Streaming, Spark SQL, MLLib,GraphX等组件(BDAS 伯克利数据分析栈)
5)基于Scala实现,能够像操作本地数据一样操作分布式数据集(RDD/Dataset)
特点:
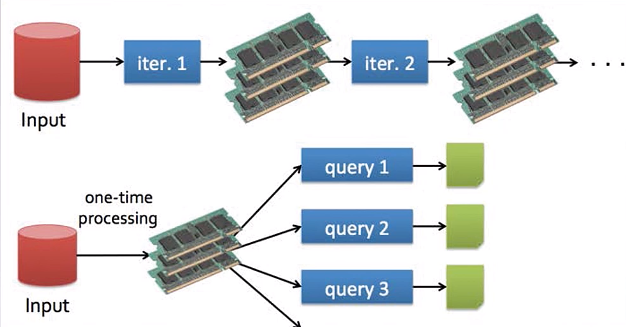
1)快,主要是两个因素:DAG将计算并行,在内存中进行数据的迭代计算(官方数据:如果原始数据从磁盘读取,处理速度是MapReduce的10倍以上)
2)易用:Scala本身简洁,同时支持Java,Python等其他语言
3)通用性强:Spark生态圈(BDAS)包括了:Spark Core, Spark Streaming, Spark SQL, GraphX, MLLib等组件,分别提供内存计算框架,实时数据处理,即刻查询,图处理,机器学习,并且能无缝集成
4)随处运行:
存储层面:Spark能够从HDFS,Cassandra,HBASE,S3等持久层读写原生数据
Job调用层面:自带的Standalone,yarn,Mesos作为资源管理器来进行Job调度
厂家支持情况:
1)30+公司100+开发者在提交代码
2)Hadoop最大的发行厂商Cloudera宣称增大Spark框架的投入
3)Hortonworks
4) Haddop厂商MapR投入Spark阵营
5)Apache Mahout(机器学习)放弃MapReduce, 将使用Spark作为其后续的计算平台
1.4、Spark和Hadoop的差异
1)中间数据在内存
2)DAG图的方式来组织计算过程,将可能的task并行执行
3)RDD(Resilent Distributed Dataset)的变换,和基于RDD的action数据计算,是Spark的核心抽象
RDD的起源:https://cs.stanford.edu/~matei/papers/2012/nsdi_spark.pdf
4)RDD,一组数据元素构成的集合,具有不可变性和分布性;数据进入Spark会转换为RDD,之后的所有数据转换及计算都基于RDD进行,概括的来看Spark计算,就是一系列的RDD转换和对RDD中的数据进行计算
Spark会根据一定的规则,将RDD分布的存储在集群内存中,并且提供了一定的机制将RDD进行重建(某个RDD所在的节点突然down机)
5)RDD计算时可以通过CheckPoint实现容错,两种方式:CheckPoint Data, Logging The updates, 用户可以自由控制
6)需要多说的是,当前Spark更推荐使用datasets来替代RDD,从效率上来看datasets的执行速度更快
7)Spark相比MapReduce提供了更多的RDD操作:
Transformation: 由1个RDD生成另一个RDD,并且延迟执行,map/filter/flatmap/Sample/GroupBykey/ReduceByKey/Union/join等等
Actions: 基于RDD进行计算并得到结果,Collect/Reduce/Lookup/Save
1.6 Spark术语
Spark运行模式
Spark运行模式,主要指的是Application提交时指定, 而部署上并没有区分
Local 本地模式 常用于本地开发测试,细分为local单线程,local-cluster多线程
Standalone 集群模式 集群模式(Master/Slave), 通过自带的资源调度器来完成作业、资源调度,支持zookeeper来实现Master HA
on yarn 集群模式 使用yarn作为资源调度,spark负责作业调度和计算
on mesos 集群模式 使用mesos作为资源调度,spark负责作业调度和计算
on cloud 集群模式 AWS EC2,可以方便的使用Amazon的S3存储
Spark应用程序
Application Spark的应用程序,包含1个Driver programme和若干executor
Driver Programme 运行Application的main()函数,并创建SparkContext
SparkContext 由Driver Programme创建, 协调各个worker Node上的Executor进程,调度计算资源
Executor Application运行在Worker Node上的1个进程,负责运行task, 以及存储数据(内存或磁盘)
ClusterManager 负责在集群上获取资源(standalone, yarn, mesos都是Cluster Manager)
worker node 集群中可以运行Application代码的物理节点,1个worker node上可以运行多个executor
Task 运行在executor进程内的工作单元,1个Executor进程内可以运行多个Task
Job SparkContext提交的具体Action,常和Action对应
Stage Job会被拆分为很多组task,每组task = Stage = Taskset
RDD Spark内的数据都用RDD来描述,根据一定的规则(partition),分布在cluster memory
两种生成方式:1)从外部存储HDFS/S3输入 2)从父RDD转换得到新RDD
DAG Scheduler 根据Job(Action) -> Stages(taskset) -> Stage间的依赖关系图(DAG),并提交Stage(1个stage中包含1组task)给task scheduler
Task Scheduler 将Stage(taskset)提交给Worker Node集群运行,并返回结果(启动、监控、汇报task)
Transformation Spark Core(内存计算)提供的RDD操作,基于1个RDD生成另外1个RDD,Transformation并不立即执行
Action Spark Core(内存计算)提供的RDD操作,基于RDD返回scala集合(结果),Action会触发transformation的执行
总结:1个Application含有1个或多个Action, 每个Action对应1个Job; 1个Job将会拆分为不同的Stage,每个Stage是1个Taskset,内部含有多个Task

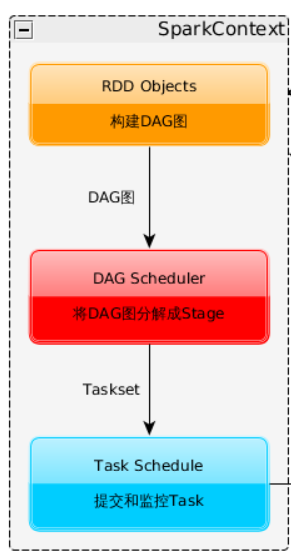
2、Spark Application的运行过程
通用过程
1、构建Spark Application的运行环境(启动SparkContext)
2、SparkContext向资源管理器(可以是Standalone、Mesos、Yarn)申请Executor资源,并在worker node上启动ExecutorBackend,Executo启动后向SparkContext注册并申请Task。
3、SparkContext先将应用程序代码发给executor
4、SparkContext构建DAG图、将DAG图分解成Stage、将Taskset发送给Task Scheduler、最后由Task Scheduler将Task发放给Executor运行
5、Task在Executor上运行,运行完毕释放所有资源
StandAlone(client模式)下的Spark Application运行过程
1、DriverProgramm运行在Client所在机器,创建SparkContext
2、SparkContext连接到Master(standalone资源调度),注册并申请资源(CPU core/Memory)
3、Master(standalone资源调度)根据worker周期性心跳决定在哪些worker上运行executor
4、Master(standalone资源调度)在worker上分配资源,启动StandaloneExecutorBackend
5、Worker Node上的StandaloneExecutorBackend,向SparkContext注册(此时SparkContext才知道哪些Worker Node可用)
6、SparkContext将Spark Application代码发送给ExecutorBackend
7、SparkContext解析Spark Application代码,构建DAG图,并提交给DAG Schduler将其分解为多个Stage,然后将Stage(1个taskset)提交给Task Scheduler
8、TaskScheduler将Task分配给不同的worker
9、worker上的backendExecutor执行task
10、backendExecutor会创建executor池,开始执行task,并向SparkContext汇报task状态
11、所有task执行完成后,SparkContext向Master(Standalone资源调入)注销,释放申请的资源

Spark on Yarn(cluster模式)运行过程
注意:Spark on Yarn有client/cluster两种模式,区别在于:
Client模式,AM(DriverProgramme)运行在提交Spark Application的节点;
Cluster模式,AM(DriverProgramme) 由Yarn进行调度,在某一个HDFS Datanode上运行
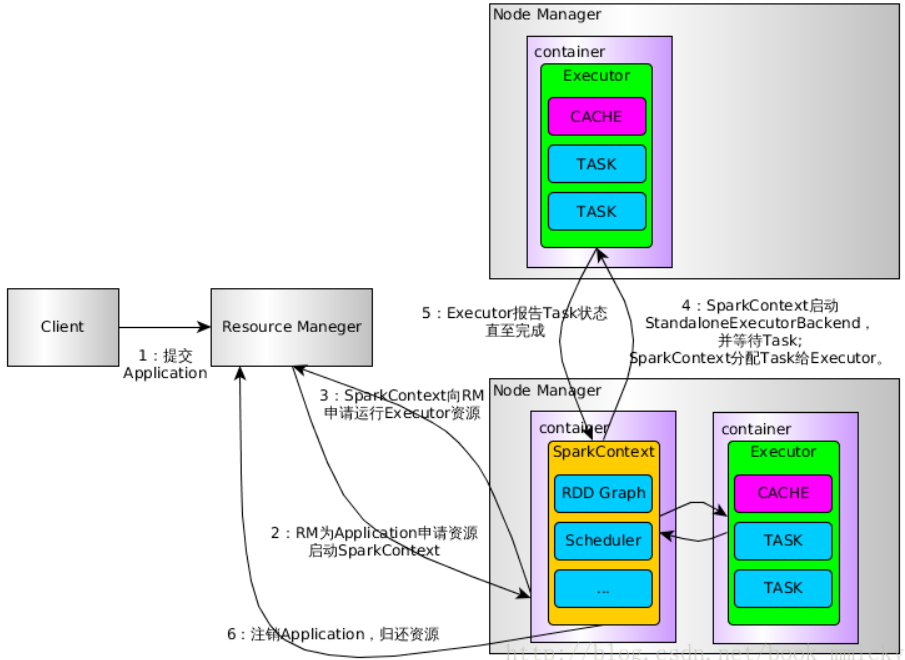
1、用户通过bin/spark-submit 向YARN提交Application
2、RM为Application分配第一个container,并在指定节点的container上启动SparkContext。
3、SparkContext向RM申请资源以运行Executor
4、RM分配Container给SparkContext,SparkContext和相关的NM通讯,在获得的Container上启动StandaloneExecutorBackend,StandaloneExecutorBackend启动后,开始向 SparkContext注册并申请Task
5、SparkContext经过DAG图构建->拆分Stage(taskset)->TaskScheduler, 将Task分配给各个NM上的StandaloneExecutorBackend执行
6、StandaloneExecutorBackend执行Task并向SparkContext汇报运行状况
7、所有Task运行完毕,SparkContext归还资源给NM,并注销退出
3、提交Spark Application
Spark集群模式包括:standalone,on yarn, on mesos; 任一种集群模式,都是通过spark-submit命令来提交Spark Application,提交Spark Application时,才指定了Spark的运行模式
官方的Application提交文档:http://spark.apache.org/docs/latest/submitting-applications.html
通过bin/spark-submit提交Spark Application:
1)通用格式及参数说明
./bin/spark-submit \
--class <main-class> \ # Java/Scala程序的入口,主类(含有main方法)
--master <master-url> \ # 通过master-url,来指定local, standalone, yarn集群模式
--deploy-mode <deploy-mode> \ # 集群模式下,根据DriverProgramme的位置(集群内,集群外)又细分为client,cluster模式
--conf <key>=<value> \ # Application的相关资源调整:内存,CPU,不同内存的占比
... # other options # 基于python构建的SparkApplication
<application-jar> \ # Java/Scala程序打包得到的jar文件,hdfs://, file:/
[application-arguments] # java,scala,python编写的程序运行时,需要从命令行读入的输入参数
<master-url>
Master URL 含义
local 本地运行SparkApplication,单线程
local[k] 本地运行SparkApplication,多线程k, K=机器的CPU核
local[k,F] 本地运行SparkApplication,多线程k, 最多F次失败(spark.task.maxFailures参数)
local[*] 本地运行SparkApplicaton,线程数尽可能多(机器的最大逻辑CPU核数)
local[*,F] 本地运行SparkApplicaton,线程数尽可能多,每个task最多允许F次失败
spark://HOST:PORT Host为Master,节点上运行自带的集群资源管理器,Port默认7077
spark://192.168.229.200:7077
spark://HOST1:PORT1, Standalone模式配置zookeeper时,将有Master的备选节点;HOST1,HOST2为所有可能的Master
HOST2:PORT2
yarn DriverProgramme将连接yarn集群的RM,yarn集群的位置通过Spark-env.sh中的HADOOP_CONF_DIR或者YARN_CONF_DIR来自动确定
2)Spark Application运行时的配置优先级
Spark Applicaiton内的conf对象中的配置,最高优先级
Spark-submit中的指定的配置,次高优先级
conf/spark-defaluts.conf默认配置文件中的配置,最低优先级
3)例子
# Run a Python application on a Spark standalone cluster
# ./bin/spark-submit \
--master spark://192.168.229.200:7077 \
examples/src/main/python/pi.py \
1000
4、RDD基本概念
1、RDD概念
Spark的计算都是围绕RDD进行,可以理解为:所有的数据要进入Spark进行处理,都要先转换为RDD,之后都围绕RDD进行转换、计算,最终得到结果
一个RDD: 由多个partition组成,每个partition包含一部分数据集片段;1个RDD的不同partition将被保存到集群中不同节点不同节点上基于partition进行并行计算
一个RDD:只读数据,如果需要修改数据就必须从父RDD转换到子RDD,同时Spark会记录RDD父子依赖(血缘),通过重新计算得到丢失的分区来完成容错
中间结果:默认是持久化到内存,通过内存完成数据共享,避免了不必要的磁盘读写开销
存放形式:存储的数据可以直接是java对象,避免了不必要的序列化和反序列化开销
2、RDD间的依赖关系(宽依赖,窄依赖)
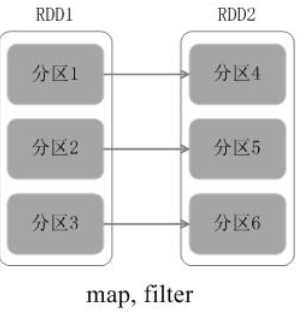
窄依赖:1个子RDD的partition, 对应1个父RDD的partition
1个子RDD的partition, 对应多个父RDD的有限个partition(而不是全部)

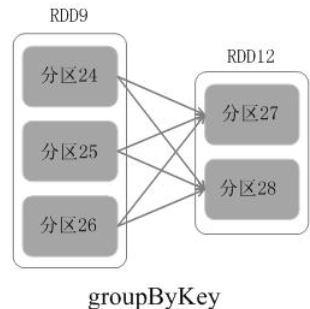
宽依赖:父RDD的1个partition,对应子RDD的多个partition
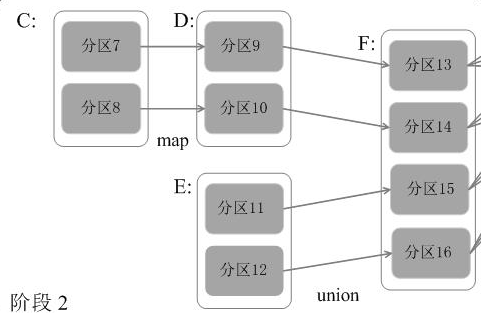
流水线
分区7-分区9-分区13, 可以持续进行而不需要等待分区8-分区10完成后才进行
总结:父RDD的一个partiton只被子RDD的一个partiton所使用就是窄依赖,否则就是宽依赖
3、Spark Application的运行和RDD

01_Spark基础的更多相关文章
- java基础集合经典训练题
第一题:要求产生10个随机的字符串,每一个字符串互相不重复,每一个字符串中组成的字符(a-zA-Z0-9)也不相同,每个字符串长度为10; 分析:*1.看到这个题目,或许你脑海中会想到很多方法,比如判 ...
- node-webkit 环境搭建与基础demo
首先去github上面下载(地址),具体更具自己的系统,我的是windows,这里只给出windows的做法 下载windows x64版本 下载之后解压,得到以下东西 为了方便,我们直接在这个目录中 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Golang, 以17个简短代码片段,切底弄懂 channel 基础
(原创出处为本博客:http://www.cnblogs.com/linguanh/) 前序: 因为打算自己搞个基于Golang的IM服务器,所以复习了下之前一直没怎么使用的协程.管道等高并发编程知识 ...
- [C#] C# 基础回顾 - 匿名方法
C# 基础回顾 - 匿名方法 目录 简介 匿名方法的参数使用范围 委托示例 简介 在 C# 2.0 之前的版本中,我们创建委托的唯一形式 -- 命名方法. 而 C# 2.0 -- 引进了匿名方法,在 ...
- HTTPS 互联网世界的安全基础
近一年公司在努力推进全站的 HTTPS 化,作为负责应用系统的我们,在配合这个趋势的过程中,顺便也就想去搞清楚 HTTP 后面的这个 S 到底是个什么含义?有什么作用?带来了哪些影响?毕竟以前也就只是 ...
- Swift与C#的基础语法比较
背景: 这两天不小心看了一下Swift的基础语法,感觉既然看了,还是写一下笔记,留个痕迹~ 总体而言,感觉Swift是一种前后端多种语言混合的产物~~~ 做为一名.NET阵营人士,少少多多总喜欢通过对 ...
- .NetCore MVC中的路由(1)路由配置基础
.NetCore MVC中的路由(1)路由配置基础 0x00 路由在MVC中起到的作用 前段时间一直忙于别的事情,终于搞定了继续学习.NetCore.这次学习的主题是MVC中的路由.路由是所有MVC框 ...
- .NET基础拾遗(5)多线程开发基础
Index : (1)类型语法.内存管理和垃圾回收基础 (2)面向对象的实现和异常的处理基础 (3)字符串.集合与流 (4)委托.事件.反射与特性 (5)多线程开发基础 (6)ADO.NET与数据库开 ...
随机推荐
- MySQL管理之道:性能调优、高可用与监控》迷你书
MySQL管理之道:性能调优.高可用与监控>迷你书 MYSQL5.5.X主要改进 1.默认使用innodb存储引擎2.充分利用CPU多核处理能力3.提高刷写脏页数量和合并插入数量,改善I/O4. ...
- 函数及while实例
输入1,输出:if 输入2,输出:elif 输入其他数值,输出:else 输入非数字,输出:except def greeting3(name3, lang3=1): if lang3 == 1: r ...
- 集成学习ensemble
集成学习里面在不知道g的情况下边学习边融合有两大派:Bagging和Boosting,每一派都有其代表性算法,这里给出一个大纲. 先来说下Bagging和Boosting之间的相同点:都是不知道g,和 ...
- 浅谈EM算法的两个理解角度
http://blog.csdn.net/xmu_jupiter/article/details/50936177 最近在写毕业论文,由于EM算法在我的研究方向中经常用到,所以把相关的资料又拿出来看了 ...
- EF Code First学习笔记 初识Code First(转)
Code First是Entity Framework提供的一种新的编程模型.通过Code First我们可以在还没有建立数据库的情况下就开始编码,然后通过代码来生成数据库. 下面通过一个简单的示例来 ...
- Hive 常用语句(持续更新中)
1)按包含关键字在指定库中查找表名:show tables in dw '*_fab_*'; 2)查看和删除自己hdfs系统所用的空间和文件(与shell命令合用):hive命令行下: --查看仓 ...
- linux常用命令:grep 命令
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达 ...
- python服务器端、客户端的模型,客服端发送请求,服务端进行响应(web.py)
服务器端.客户端的模型,客服端发送的请求,服务端的响应 相当于启动了一个web server install web.py 接口框架用到的包 http://webpy.org/tutorial3.zh ...
- Linux基础命令---diffstat
diffstat 这个程序读取diff的输出,并显示每个文件的插入.删除和修改的直方图.Diffstat是一个用于检查大型复杂修补程序文件的程序.它从包含diff输出的一个或多个输入文件中读取,生成针 ...
- Linux服务器---关闭selinux
关闭selinux 1.通过命令“getenforce”获取selinux状态, [root@localhost ~]# getenforce Enforcing //enforcein ...