局部敏感哈希-Locality Sensitivity Hashing
一. 近邻搜索
从这里开始我将会对LSH进行一番长篇大论。因为这只是一篇博文,并不是论文。我觉得一篇好的博文是尽可能让人看懂,它对语言的要求并没有像论文那么严格,因此它可以有更强的表现力。
局部敏感哈希,英文locality-sensetive hashing,常简称为LSH。局部敏感哈希在部分中文文献中也会被称做位置敏感哈希。LSH是一种哈希算法,最早在1998年由Indyk在[1]上提出。不同于我们在数据结构教材中对哈希算法的认识,哈希最开始是为了减少冲突方便快速增删改查,在这里LSH恰恰相反,它利用的正式哈希冲突加速检索,并且效果极其明显。LSH主要运用到高维海量数据的快速近似查找。近似查找便是比较数据点之间的距离或者是相似度。因此,很明显,LSH是向量空间模型下的东西。一切数据都是以点或者说以向量的形式表现出来的。在细说LSH之前必须先提一下K最近邻查找 (kNN,k-Nearest Neighbor)与c最近邻查找 (cNN,c-Nearest Neighbor )。
kNN问题就不多说了,这个大家应该都清楚,在一个点集中寻找距离目标点最近的K个点。我们主要提一下cNN问题。首先给出最近邻查找(NN,Nearest Neighbor)的定义。
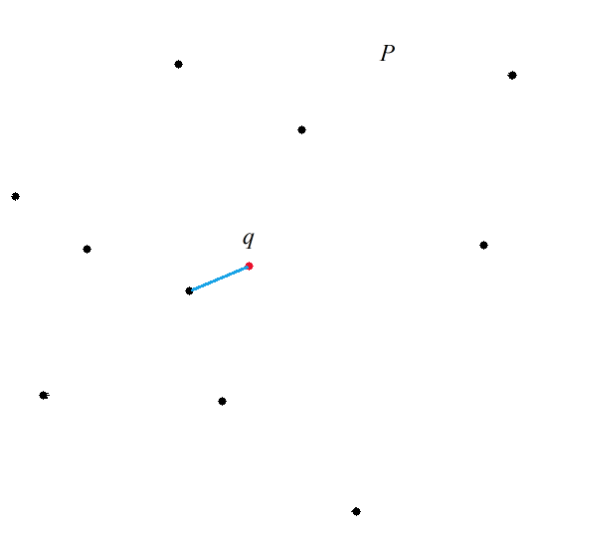
定义 1: 给定一拥有nn个点的点集PP,在此集合中寻找距离qq 点最近的一个点。
这个定义很容易被理解,需要说明的是这个距离是个广义的概念,并没有说一定是欧式距离。随着需求的不同可以是不同的距离度量手段。那么接下来给出cNN问题的定义。
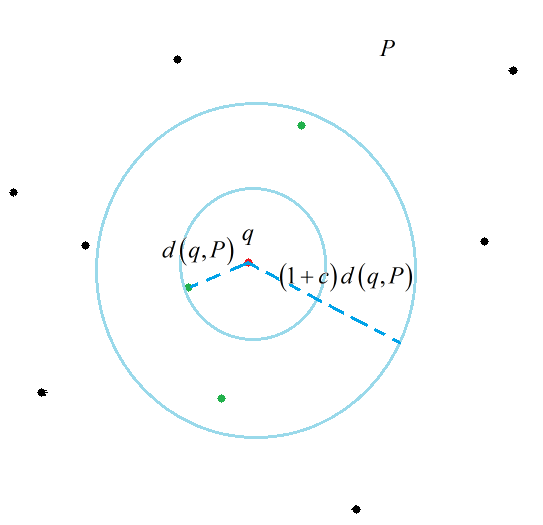

cNN不同于kNN,cNN和距离的联系更加紧密。LSH本身设计出来是专门针对解决cNN问题,而不是kNN问题,但是很多时候kNN与cNN有着相似的解集。因此LSH也可以运用在kNN问题上。这些问题若使用一一匹配的暴力搜索方式会消耗大量的时间,即使这个时间复杂度是线性的。也许一次两次遍历整个数据集不会消耗很多时间,但是如果是以用户检索访问的形式表现出来可以发现查询的用户多了,每个用户都需要消耗掉一些资源,服务器往往会承受巨大负荷。那么即使是线性的复杂度也是不可以忍受的。早期为了解决这类问题涌现出了许多基于树形结构的搜索方案,如KD树,SR树。但是这些方法只适用于低维数据。自从LSH的出现,高维数据的近似查找便得到了一定的解决。
二. LSH的定义
LSH不像树形结构的方法可以得到精确的结果,LSH所得到的是一个近似的结果,因为在很多领域中并不需非常高的精确度。即使是近似解,但有时候这个近似程度几乎和精准解一致。
LSH的主要思想是,高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希值计算,使得他们哈希值有很大的概率是一样的。同时若两点之间的距离较远,他们哈希值相同的概率会很小。给出LSH的定义如下:



三. 曼哈顿距离转换成汉明距离
从理论讲解的逻辑顺序上来说,现在还没到非要讲具体哈希函数的时候,但是为了方便理解,必须要举一个实例来讲解会好一些。那么就以曼哈顿距离下(其实用的是汉明距离的特性)的LSH哈希函数族作为一个参考的例子讲解。
曼哈顿距离又称L1L1范数距离。其具体定义如下:

其实曼哈顿距离我们应该并不陌生。他与欧式距离(L2范数距离)的差别就像直角三角形两边之和与斜边的差别。文[2]介绍了具体如何构造曼哈顿距离LSH哈希函数的过程。其实在这篇论文发表的时候欧式距离的哈希函数还没有被探究出来,原本LSH的设计其实是想解决欧式距离度量下的近似搜索。所以当时这个事情搞得就很尴尬,然后我们的大牛Indyk等人就强行解释,大致意思是:不要在意这些细节,曼哈顿和欧式距离差不多。他在文[2]中提出了两个关键的问题。
1.使用L1范数距离进行度量。
2.所有坐标全部被正整数化。
对于第一条他解释说L1范数距离与L2范数距离在进行近似查找时得到的结果非常相似。对于第二条,整数化是为了方便进行01编码。

四. 汉明距离下的LSH哈希函数


五. LSH的重要参数


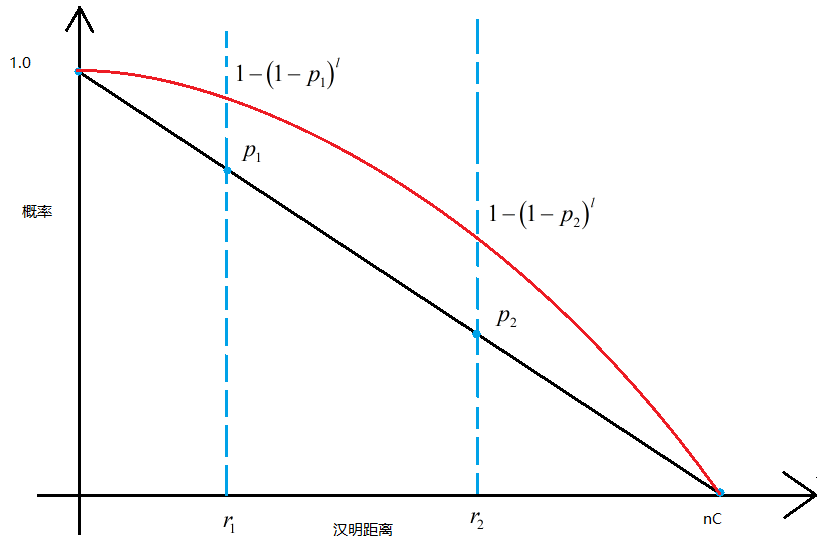
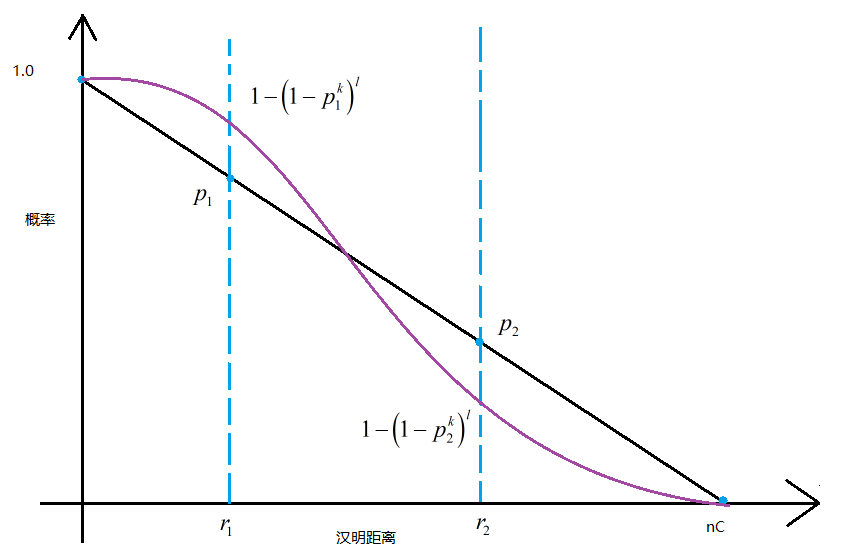






六、局部敏感哈希规整
说到Hash,大家都很熟悉,是一种典型的Key-Value结构,最常见的算法莫过于MD5。其设计思想是使Key集合中的任意关键字能够尽可能均匀的变换到Value空间中,不同的Key对应不同的Value,即使Key值只有轻微变化,Value值也会发生很大地变化。这样特性可以作为文件的唯一标识,在做下载校验时我们就使用了这个特性。但是有没有这样一种Hash呢?他能够使相似Key值计算出的Value值相同或在某种度量下相近呢?甚至得到的Value值能够保留原始文件的信息,这样相同或相近的文件能够以Hash的方式被快速检索出来,或用作快速的相似性比对。位置敏感哈希(Local Sensitive Hashing, LSH)正好满足了这种需求,在大规模数据处理中应用非常广泛,例如已下场景[1]:
1. 近似检测(Near-duplicate detection):通常运用在网页去重方面。在搜索中往往会遇到内容相似的重复页面,它们中大多是由于网站之间转载造成的。可以对页面计算LSH,通过查找相等或相近的LSH值找到Near-duplicate。
2. 图像、音频检索:通常图像、音频文件都比较大,并且比较起来相对麻烦,我们可以事先对其计算LSH,用作信息指纹,这样可以给定一个文件的LSH值,快速找到与其相等或相近的图像和文件。
3. 聚类:将LSH值作为样本特征,将相同或相近的LSH值的样本合并在一起作为一个类别。
LSH(Location Sensitive Hash),即位置敏感哈希函数。与一般哈希函数不同的是位置敏感性,也就是散列前的相似点经过哈希之后,也能够在一定程度上相似,并且具有一定的概率保证[3]。
LSH的形式化定义可参见前面部分。
如下图,空间上的点经位置敏感哈希函数散列之后,对于q,其rNN有可能散列到同一个桶(如第一个桶),即散列到第一个桶的概率较大,会大于某一个概率阈值p1;而其(1+emxilong)rNN之外的对象则不太可能散列到第一个桶,即散列到第一个桶的概率很小,会小于某个阈值p2.
LSH的作用:
◆高维下近似查询
相似性检索在各种领域特别是在视频、音频、图像、文本等含有丰富特征信息领域中的应用变得越来越重要。丰富的特征信息一般用高维向量表示,由此相似性检索一般通过K近邻或近似近邻查询来实现。一个理想的相似性检索一般需要满足以下四个条件[4]:
1. 高准确性。即返回的结果和线性查找的结果接近。
2. 空间复杂度低。即占用内存空间少。理想状态下,空间复杂度随数据集呈线性增长,但不会远大于数据集的大小。
3. 时间复杂度低。检索的时间复杂度最好为O(1)或O(logN)。
4. 支持高维度。能够较灵活地支持高维数据的检索。
此外, 检索模式应能快速地构造索引数据结构, 并且可以完成插入、删除等操作。
传统主要方法是基于空间划分的算法——tree类似算法,如R-tree,Kd-tree,SR-tree。这种算法返回的结果是精确的,但是这种算法在高维数据集上的时间效率并不高。实验[5]指出维度高于10之后,基于空间划分的算法时间复杂度反而不如线性查找。LSH方法能够在保证一定程度上的准确性的前提下,时间和空间复杂度得到降低,并且能够很好地支持高维数据的检索。
现有的很多检索算法并不能同时满足以上的所有性质。
以前主要采用基于空间划分的算法–tree 算法, 例如: R-tree[6], Kd-tree[7],SR-tree。这些算法返回的结果都是精确的, 然而它们在高维数据集上时间效率并不高。文献[5]的试验指出在维度高于10之后, 基于空间划分的算法的时间复杂度反而不如线性查找。
1998年, P.Indy和R.Motwani提出了LSH算法的理论基础。1999 年Gionis A,P.Indy和R.Motwani使用哈希的办法解决高维数据的快速检索问题, 这也是Basic LSH算法的雏形。2004 年, P.Indy 提出了LSH 算法在欧几里德空间(2-范数)下的具体解决办法。同年, 在自然语言处理领域中, Deepak Ravichandran使用二进制向量和快速检索算法改进了Basic LSH 算法[8] , 并将其应用到大规模的名词聚类中, 但改进后的算法时间效率并不理想。2005 年, Mayank Bawa, Tyson Condie 和Prasanna Ganesan 提出了LSH Forest算法[9], 该算法使用树形结构代替哈希表, 具有自我校正参
数的能力。2006 年, R. Panigrahy[10]用产生近邻查询点的方法提高LSH 空间效率, 但却降低了算法的空间效率。2007年,William Josephson 和Zhe Wang使用多重探测的方法改进了欧几里德空间(2-范数)下的LSH 算法, 同时提高了算法的时间效率和空间效率。
◆分类和聚类
根据LSH的特性,即可将相近(相似)的对象散列到同一个桶之中,则可以对图像、音视频、文本等丰富的高维数据进行分类或聚类。
◆数据压缩。如广泛地应用于信号处理及数据压缩等领域的Vector Quantization量子化技术。
总而言之,哪儿需要近似kNN查询,哪儿都能用上LSH.
维基百科对LSH的解释给出了几种不同的定义形式。不过还是大牛Moses Charikar的定义相对简单明了:对于两个物体(可以理解为两个文件、两个向量等),LSH生成的value值的每一bit位相等的概率等于这两个物体的相似度, 这里不需要明确是什么度量方式(由此引申出了各种各样的LSH算法), 只要满足上式的就叫做LSH. 显然这种定义天生就使LSH在hash后能够保留原始样本差异程度的信息,相近的物体的汉明距离就相近。介绍LSH,先从起源开始,我们先拿最初为LSH做出贡献的三个大牛开始说起。

【1】. 1998年Piotr Indyk在Stanford读PHD时与导师Rajeev Motwani提出一种hash方法: Locality Sensitive Hashing [Indyk-Motwani'98]. Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality 被引用1627次, 作者Piotr Indyk2000年从Stanford毕业后就职于MIT, 现在是MIT的教授, 主页中有关于LSH的相关代码及研究介绍。LSH的相关代码工作主要由他的学生Alexandr Andoni编写并维护.
[文章总结]: 首先NN问题应用于很多场合,常常是设计相似搜索,例如:data compression; databases and data mining; information retrieval; image and video database; machine learning; pattern recognition; and, statistics and data analysis. 因为之前过去KNN总是通过一种brute-force algorithm对所有样本点进行逐一匹配. 所以人们开始探索一种approximate nearest neighbors problem. 这篇文章的目的主要是为了Removing the Curse of Dimensionality而提出的一种Approximate Nearest Neighbors Algorithms,并命名为locality-sensitive hashing. 应用场景: information retrieval, pattern recognition, dynamic closest-pairs, and fast clustering algorithms. LSH的key idea is to use hash functions such that the probability of collision is much higher for objects that are close to each other than for those that are far apart. and they prove that existence of such functions for any domain. 并且给出了两种functions, one for a Hamming space and the other for a family of subsets of a set under the resemblance measure used by Broder et al. tocluster web documents.
1. P. Indyk and R. Motwani. Approximate nearest neighbors: towards removing the curse of dimensionality[A]. In STOC ’98: Proceedings of the thirtieth annual ACM symposium on Theory of computing, New York, USA: ACM Press, 1998:604–613.

【2】. 1999年Piotr Indyk的同门师弟Aristides Gionis对之前的LSH雏形算法进行完善发表了Similarity Search in High Dimensions via Hashing这篇文章目前也被引用了1250次, 而且在Alexandr Andoni维护的LSH主页上也说明最初的Original LSH algorithm (1999)指向的是这篇文章. 作者Aristides Gionis现在在芬兰Aalto University任教.
[文章总结]:This paper presents locality-sensitive hashing(LSH). This technique was originally introduced by Indyk and Motwani for the purposes of devising main memory algorithms for the -NNS problem. Here this paper gives an improved version of their algorithm. The new algorithm is in many respects more natural than the earlier one: it does not require the hash buckets to store only one point; it has better running time guarantees; and, the analysis is generalized to the case of secondary memory.
2.Gionis A, Indyk P, Motwani R. Similarity search in high dimension s via hashing [C] Proceedings of the 25th International Conference on Very Large Data Bases (VLDB). 1999

【3】. 现在回到Alexandr Andoni维护的LSH主页中来了解LSH的发展近况. 早期时候, 2005年, Alexandr Andoni给出一篇Ann(Approximate Nearest Neighbor) Introduction for LSH, 算是一篇普及型文章, 可翻来读读.作者是Greg Shakhnarovich, 之前在MIT读的PHD, 现在在Toyota Technological Institute at Chicago任教.
[文章总结]:A naive algorithm for this problem is as follows: given a query q, compute the distance from q to each point in P, and report the point with the minimum distance. This linear scan approach has query time of Θ(dn). This is tolerable for small data sets, but is too inefficient for large ones. The “holy grail” of the research in the area is to design an algorithm for this problem that achieves sublinear (or even logarithmic) query time.The nearest-neighbor problem has been extensively investigated in the field of computational geometry. Unfortunately, as the dimension grows, the algorithms become less and less efficient. The lack of success in removing the exponential dependence on the dimension led many researchers to conjecture that no efficient solutions exist for this problem when the dimension is sufficiently large. At the same time, it raised the question: Is it possible to remove the exponential dependence on d, if we allow the answers to be approximate? The approximate nearest neighbor search problem is defined as follows: Given a set P of points in a d-dimensional space d, construct a data structure which given any query point q, reports any point within distance at most c times the distance from q to p, where p is the point in P closest to q.
[插曲:]介绍KNN的时候会顺带介绍一些KD-Tree相关的工作,关于KD-Tree相关知识可看一下这篇博文:从K近邻算法、距离度量谈到KD树、SIFT+BBF算法。
进入LSH实现部分,将按LSH的发展顺序介绍几种应用广泛的LSH算法。
1, 基于Stable Distribution投影方法
2, 基于随机超平面投影的方法;
3, SimHash;
4, Kernel LSH
1, 基于Stable Distribution投影方法
2008年IEEE Signal Process上有一篇文章Locality-Sensitive Hashing for Finding Nearest Neighbors是一篇较为容易理解的基于Stable Dsitrubution的投影方法的Tutorial, 有兴趣的可以看一下. 其思想在于高维空间中相近的物体,投影(降维)后也相近。基于Stable Distribution的投影LSH,就是产生满足Stable Distribution的分布进行投影,最后将量化后的投影值作为value输出. 更详细的介绍在Alexandr Andoni维护的LSH主页中,理论看起来比较复杂,不过这就是LSH方法的鼻祖啦,缺点显而易见:你需要同时选择两个参数,并且量化后的哈希值是一个整数而不是bit形式的0和1,你还需要再变换一次。如果要应用到实际中,简直让你抓狂。
2, 基于随机超平面投影的方法
大神Charikar改进了上种方法的缺点,提出了一种随机超平面投影LSH.
这种方法的最大优点在于:
1),不需要参数设定
2),是两个向量间的cosine距离,非常适合于文本度量
3),计算后的value值是比特形式的1和0,免去了前面算法的再次变化
3, SimHash
前面介绍的LSH算法,都需要首先将样本特征映射为特征向量的形式,使得我们需要额外存储一个映射字典,难免麻烦,大神Charikar又提出了大名鼎鼎的SimHash算法,在满足随机超平面投影LSH特性的同时避免了额外的映射开销,非常适合于token形式的特征。
首先来看SimHash的计算过程[2]:
a,将一个f维的向量V初始化为0;f位的二进制数S初始化为0;
b,对每一个特征:用传统的hash算法(究竟是哪种算法并不重要,只要均匀就可以)对该特征产生一个f位的签名b。对i=1到f:
如果b的第i位为1,则V的第i个元素加上该特征的权重;
否则,V的第i个元素减去该特征的权重。
c,如果V的第i个元素大于0,则S的第i位为1,否则为0;
d,输出S作为签名。
大家引用SimHash的文章通常都标为2002年这篇Similarity Estimation Techniques from Rounding Algorithms, 而这篇文章里实际是讨论了两种metric的hash. 参考[1]的作者猜测, SimHash应该是随机超平面投影LSH,而不是后来的token形式的SimHash. 其实只是概念的归属问题, 已经无关紧要了, 我想很多人引用上篇文章也有部分原因是因为07年Google研究院的Gurmeet Singh Manku在WWW上的这篇paper: Detecting Near-Duplicates for Web Crawling, 文中给出了simhash在网络爬虫去重工作的应用,并利用编码的重排列方式解决快速Hamming距离搜索问题.
这里插曲抱怨一下网络爬虫去重的一些抱怨,例如文献[1],标题显示是一篇转发的文章,而且内容中很多图片已经无法显示,转发作者却没有给出原文出处。
4, Kernel LSH
前面讲了三种LSH算法,基本可以解决一般情况下的问题,不过对于某些特定情况还是不行:比如输入的key值不是均匀分布在整个空间中,可能只是集中在某个小区域内,需要在这个区域内放大距离尺度。又比如我们采用直方图作为特征,往往会dense一些,向量只分布在大于0的区域中,不适合采用cosine距离,而stable Distribution投影方法参数太过敏感,实际设计起来较为困难和易错,不免让我们联想,是否有RBF kernel这样的东西能够方便的缩放距离尺度呢?或是我们想得到别的相似度表示方式。这里就需要更加fancy的kernel LSH了。
我们观察前面的几种LSH,发现其形式都可以表示成内积的形式,提到内积自然会想到kernel方法,是不是LSH也能使用kernel呢?
Kernel LSH的工作可参看下面这三篇文章:
1). 2009年ICCV上的 Kernelized Locality-Sensitive Hashing for Scalable Image Search
2). 2009年NIPS上的Locality-Sensitive Binary Codes From Shift-Invariant Kernels[PPT]
3). 2007年NIPS上的Random Features for Large-Scale Kernel Machines
下面是文献[1]作者的总结: 这里介绍了四种LSH方法,最原始的Sable Distribution的投影LSH,满足cosine距离的随机超平面投影LSH,以及他的文本特征改进SimHash,最后介绍了RBF kernel下的LSH,基本可以满足我们的需要。当然kernel LSH还会随着kernel map技术的发展而发展,现在有了不错的显示映射方法,比如 Efficient Additive Kernels via Explicit Feature Maps,提供了一种有限维有损的显示映射方法,但是值域并不是均匀分布的,需要额外小心。另外一些方法就是有监督的或半监督的,随着应用场景不同而改变,这两年CVPR里有很多此类LSH方法的文章,看来还是比较受欢迎的。Spectral Hash用过一下,感觉效果不好,估计是因为距离度量不适合使用的样本。其实LSH问题的关键是根据数据集和需要度量的相似度,选择合适的manifold进行投影,也算是manifold learning的一个思想吧。
这十年时间内,大家在Hash上做了很多工作来完善Hash算法,恰巧在写这份总结的时候(13年07月23日)上海交通大学Wu-Jun Li实验室share了一份Learning to Hash的PPT. 这是2013年1月份的一个talk. 不过Wu-Jun Li关于Hash的工作还是值得参考的. 而且share了很多matlab代码和data, 很赞.
Hash函数学习的两个阶段:
1). Projection Stage(Dimension Reduction)映射阶段(降维)
Projected with real-valued projection function;
Given a point , each projected dimension will be associated with a real-value projection function(e.g. ).
2). Quantization Stage量化阶段
Turn real into binary.
根据是否依赖于数据集又可分为两类:
Data-Independent Methods
The hashing function family is defined independently of the training dataset:
Locality-sensitive hashing (LSH): (Gionis et al., 1999; Andoni and Indyk, 2008) and its extensions (Datar et al., 2004; Kulis and Grauman, 2009; Kulis et al., 2009).
SIKH: Shift invariant kernel hashing (SIKH) (Raginsky and Lazebnik, 2009).
Hashing function: random projections.
Data-Dependent Methods
Hashing functions are learned from a given training dataset.
Relatively short codes
依赖于数据的Hash方法又分为two categories:
a). Supervised methods
or 0
b). Unsupervised methods
Unsupervised Methods有以下几种:
No labels to denote the similarity (neighborhood) between points.
PCAH: principal component analysis.
ITQ: (Gong and Lazebnik, 2011) orthogonal rotation matrix to refine the initial projection matrix learned by PCA.
Supervised(semi-supervised)Methods有以下几种:
Training dataset contains additional supervised information, (e.g. class labels or pairwise constraints).
SH: Spectral Hashing (SH) (Weiss et al., 2008) adopts the eigenfunctions computed from the data similarity graph.
SSH: Semi-Supervised Hashing (SSH) (Wang et al., 2010a,b) exploits both labeled data and unlabeled data for hash function learning.
MLH: Minimal loss hashing (MLH) (Norouzi and Fleet, 2011) based on the latent structural SVM framework.
AGH: Graph-based hashing (Liu et al., 2011).
现在大数据互联网应用中,如何能把Hash应用到Web相似性搜索中(最近语义搜索和知识图谱已经成为各大搜索公司必争之地).这篇博士论文《2011 基于LSH的Web数据相似性查询研究》可以参考一下.
Web数据的特点:
a).海量性;
b).异构性, 种类繁多
Web数据的异构性和多样化的应用使得Web上的数据种类也呈现多样化的特征。Web数据可分为3中1).非结构化数据(Unstructured Data); 2).结构化数据(Structured Data); 3). 多媒体数据(Multimedia Data). 例如, 非结构化的数据比如Web页面数据, 字符串数据(String Data)等。带结构的数据包括半结构化数据和结构化数据, 其中Web上广泛使用的XML是半结构化的. 而结构化数据包括图数据(Graph)和关系数据(Relational Data). 例如, 整个Web的结构可以看作一张图, 社会网络结构也可以使用图进行建模. 多媒体数据包括图像数据(Image), 视频数据(Video)和音频数据(Audio).
c).带有噪音
由于人们输入的错误,误差,简写,OCR识别以及多个数据源格式不一致等情况,导致了Web数据带有大量的噪音,这给Web数据的查询,数据集成等带来了困难和挑战.
参考资料:
[1]: http://blog.csdn.net/zhou191954/article/details/8494438
[2]: http://gemantic.iteye.com/blog/1701101
[3]: http://www.jiahenglu.net/NSFC/LSH.html
[4]:基于LSH的中文文本快速检索 2009.
[5]:Weber R, Schek H, Blott S. A quantitative analysis and performance study for similarity search methods in high dimensional spaces Proc.of the 24th Intl.Conf.on Very Large Data Bases (VLDB).1998:194-205
[6] Guttman A. R-trees: A dynamic index structure for spatial searching[C] Proc. of ACM Conf. on Management of Data
(SIGMOD). 1984: 47-57
[7] Bentley J L. K-D trees for semi-dynamic point sets[C] Proc. of the 6th ACM Symposium on Computational Geometry (SCG). 1990: 187-197
[8] Ravichandran D, Pantel P, Hovy E. Randomized Algorithms and NLP: Using Locality Sensitive Hash Function for High S peed Noun Clustering[M]. Information Sciences Institute University of Southern California, 2004
[9] Bawa M, Condie T, Ganesan P. LSH Forest: SelfTuning[C] Indexes for Similarity Search International World Wide Web
Conference Proceedings of the 14th International Conference on World Wide Web. 2005
[10] “Entropy based Nearest Neighbor Search in High Dimensions”. SODA 2006
局部敏感哈希-Locality Sensitivity Hashing的更多相关文章
- 局部敏感哈希-Locality Sensitive Hashing
局部敏感哈希 转载请注明http://blog.csdn.net/stdcoutzyx/article/details/44456679 在检索技术中,索引一直须要研究的核心技术.当下,索引技术主要分 ...
- 局部敏感哈希Locality Sensitive Hashing(LSH)之随机投影法
1. 概述 LSH是由文献[1]提出的一种用于高效求解最近邻搜索问题的Hash算法.LSH算法的基本思想是利用一个hash函数把集合中的元素映射成hash值,使得相似度越高的元素hash值相等的概率也 ...
- 用单分子测序(single-molecule sequencing)和局部敏感哈希(locality-sensitive hashing)来组装大型基因组
Assembling large genomes with single-molecule sequencing and locality-sensitive hashing 好好读读,算法系列的好文 ...
- 局部敏感哈希 Kernelized Locality-Sensitive Hashing Page
Kernelized Locality-Sensitive Hashing Page Brian Kulis (1) and Kristen Grauman (2)(1) UC Berkeley ...
- [Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)
局部敏感哈希(Locality Sensitive Hashing,LSH)算法是我在前一段时间找工作时接触到的一种衡量文本相似度的算法.局部敏感哈希是近似最近邻搜索算法中最流行的一种,它有坚实的理论 ...
- 局部敏感哈希算法(Locality Sensitive Hashing)
from:https://www.cnblogs.com/maybe2030/p/4953039.html 阅读目录 1. 基本思想 2. 局部敏感哈希LSH 3. 文档相似度计算 局部敏感哈希(Lo ...
- 海量数据挖掘MMDS week2: 局部敏感哈希Locality-Sensitive Hashing, LSH
http://blog.csdn.net/pipisorry/article/details/48858661 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [机器学习] 在茫茫人海中发现相似的你:实现局部敏感哈希(LSH)并应用于文档检索
简介 局部敏感哈希(Locality Sensitive Hasing)是一种近邻搜索模型,由斯坦福大学的Mose Charikar提出.我们用一种随机投影(Random Projection)的方式 ...
- 海量数据挖掘MMDS week7: 局部敏感哈希LSH(进阶)
http://blog.csdn.net/pipisorry/article/details/49686913 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
随机推荐
- com.mysql.cj.exceptions.InvalidConnectionAttributeException: The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone. 问题解决方法
一.问题 今天用mybatis连接数据库时出现了如下错误: com.mysql.cj.exceptions.InvalidConnectionAttributeException: The serve ...
- cache、session与cookie
cache.session.cookie的区别 session把数据保存在服务器端,每一个用户都有属于自己的Session,与别人的不冲突 就是说,你登陆系统后,你的信息(如账号.密码等)就会被保存在 ...
- 【java编程】java对象copy
实现java对象Copy的三种方式 一.克隆 implements Cloneable 二.序列化 implements Serializable 三.利用反射机制copy apache的BeanUt ...
- dgraph 基本查询语法 一
dgraph 的查询语法是在graphql 上的扩展,添加了新的支持,同时官方提供了一个 学习的网站 https://tour.dgraph.io/ 基本环境(cluster 模式的) 参考 gith ...
- 转 Apache Kafka:下一代分布式消息系统
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- Microsoft OWIN
About OWIN defines a standard interface between .NET web servers and web applications. The goal of t ...
- GridColumn (Column Layout and Auto Width)
Namespace:DevExpress.XtraGrid.Columns Assembly:DevExpress.XtraGrid.v16.2.dll https://documentation.d ...
- enjoy dollar vs cash dollar
當 enJoy 卡 客 戶 憑 enJoy 卡 於 enJoy 卡 「 特 約 商 戶 」 簽 賬 消 費 , 累 積 之 enJoy Dollars 及 Cash Dollars 可 在 同 一 交 ...
- jmeter自动生成报告
从JMeter 3.0开始已支持自动生成动态报告,我们可以更容易根据生成的报告来完成我们的性能测试报告. 如何生成html测试报告 如果未生成结果文件(.jtl),可运行如下命令生成报告: jmete ...
- Jsp Cookie
cookie它是用户访问Web服务器时,服务器在用户硬盘上存放的信息. 1.使用Servlet实现cookie @WebServlet("/CookieServlet") publ ...