crawlspider爬虫:定义url规则
spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候)
crawlspider爬虫,适合不用meta传参的爬虫
scrapy genspider -t crawl it it.com
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from Sun.items import SunItem class DongguanSpider(CrawlSpider):
name = 'dongguan'
# 修改允许的域
allowed_domains = ['sun0769.com']
# 修改起始的url
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4'] rules = (
# 构建列表url的提取规则
Rule(LinkExtractor(allow=r'questionType'), follow=True),
# 构建详情页面url提取规则
# 'html/question/201711/352271.shtml'
Rule(LinkExtractor(allow=r'html/question/\d+/\d+.shtml'), callback='parse_item'),
) def parse_item(self, response):
# print (response.url,'--------') # 构建item实例
item = SunItem() # 抽取数据,将数据存放到item中
item['number'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].strip()
item['title'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].split(' ')[0]
item['link'] = response.url
data = ''.join(response.xpath('//div[@class="c1 text14_2"]/text()|//div[@class="contentext"]/text()').extract())
item['content'] = data.replace('\xa0','')
# print(item)
# 返回数据
yield item

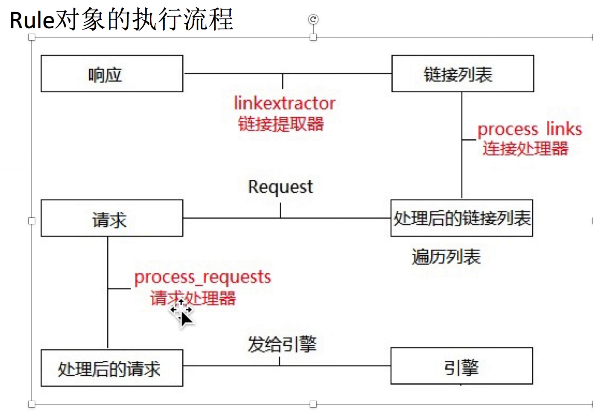
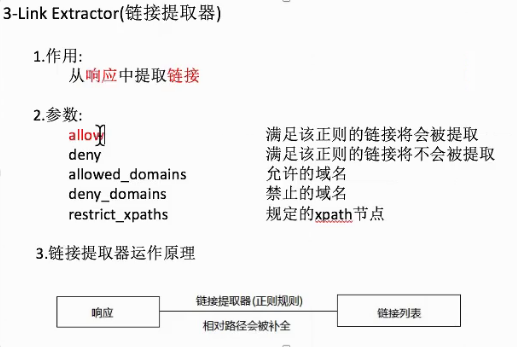
链接提取器的使用
scrapy shell http://hr.tencent.com/position.php
>>> from scrapy.linkextractors import LinkExtractor
>>> le = LinkExtractor(allow=('position_detail.php\?id=\d+&keywords=&tid=0&lid=0'))
或者直接 le = LinkExtractor(allow=('position_detail.php')) 也可以
>>> links=le.extract_links(response)
>>> for link in links:
... print(link)
...
>>> for link in links:
... print(link.url)
...


crawlspider爬虫:定义url规则的更多相关文章
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Django学习(四) Django提供的后台管理系统以及如何定义URL路由
一旦你建立了模型Models,那么Django就可以为你创建一个专业的,可以提供给生成用的后台管理站点.这个站点可以提供给有权限的人进行已有模型Models数据的增删改查. 将新建的模型Models是 ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- 《玩转Django2.0》读书笔记-编写URL规则
<玩转Django2.0>读书笔记-编写URL规则 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. URL(Uniform Resource Locator,统一资源定位 ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 创建CrawlSpider爬虫简要步骤
创建CrawlSpider爬虫简要步骤: 1. 创建项目文件: e.g: scrapy startproject douyu (douyu为项目名自定义) 2. 进入项目文件: e.g: cd dou ...
- dt框架自定义url规则
destoon的列表的地址规则是定义在/api/url.inc.php,然后又是在include/global.func.php中进行的listpages这个函数调用实现 if($page < ...
- PHPCMS V9静态化HTML生成设置及URL规则优化
先讲讲Phpcms V9在后台怎么设置生成静态化HTML,之后再讲解怎么自定义URL规则,进行URL地址优化.在这一篇中,伪静态就不涉及了,大家可以移步到Phpcms V9全站伪静态设置方法. 一.静 ...
随机推荐
- 第二篇:Hadoop 在Ubuntu Kylin系统上的搭建[图解]
前言 本文介绍如何在Ubuntu Kylin操作系统上搭建Hadoop平台. 配置 1. 操作系统: Ubuntu Kylin 14.04 2. 编程语言: JDK 1.8 3. 通信协议: SSH ...
- mysql错误:got error 28 from storage engine
今天碰到数据库出错 Got error 28 from storage engine 查了一下,数据库文件所在的盘应该没事,应该是数据库用的临时目录空间不够 引用 磁盘临时空间不够导致.解决办法:清空 ...
- Mac下Intellij IDea发布JavaWeb项目 详解三 (为所有Module配置Tomcat Deployment 并测试web 网页 配置Servlet)
step4 为所有项目配置Deployment 4.1 如图 4.2 [+][Artifact] 4.3 将这里列出的所有内容选中后,点[OK] 4.4 选完是这样,表示,这三个java ee 项目会 ...
- liunx trac 安装记录
1,下载地址 http://trac.edgewall.org/ 2.安装 apache,python, mysql 3,安装trac (我的是0.12) tar -zxvf 你下载的安装包 ...
- python基础---->python的使用(一)
这里面记录一些python的一些基础知识,数据类型和变量.幸而下雨,雨在街上泼,却泼不进屋内.人靠在一块玻璃窗旁,便会觉得幸福.这个家还是像个家的. python的一些基础使用 一.python中的数 ...
- Toast 自定义
转:http://www.cnblogs.com/salam/archive/2010/11/10/1873654.html 1.默认效果 代码 Toast.makeText(getApplicati ...
- Android density、dpi、dp、px
Density DPI Example Device Scale Pixels ldpi 120 Galaxy Y 0.75x 1dp = 0.75px mdpi 160 Galaxy Tab 1.0 ...
- LeetCode 33 Search in Rotated Sorted Array(循环有序数组中进行查找操作)
题目链接 :https://leetcode.com/problems/search-in-rotated-sorted-array/?tab=Description Problem :当前的数组 ...
- [原]RHEL7/Centos 7将网卡名称改为eth0
======问题===== rhel的网卡为enoxxxxxxxxx =====原因====== 从CentOS/RHEL7起,可预见的命名规则变成了默认.这一规则,接口名称被自动基于固件,拓扑结构和 ...
- 打开指定目录路径的CMD命令行窗口
1.打开目录文件夹, Shift + 右键 2.会直接打开CMD所在的目录路径