生存分析(survival analysis)
一、生存分析(survival analysis)的定义
生存分析:对一个或多个非负随机变量进行统计推断,研究生存现象和响应时间数据及其统计规律的一门学科。
生存分析:既考虑结果又考虑生存时间的一种统计方法,并可充分利用截尾数据所提供的不完全信息,对生存时间的分布特征进行描述,对影响生存时间的主要因素进行分析。
生存分析不同于其它多因素分析的主要区别点:生存分析考虑了每个观测出现某一结局的时间长短。
应用场景
什么是生存?生存的意义很广泛,它可以指人或动物的存活(相对于死亡),可以是患者的病情正处于缓解状态(相对于再次复发或恶化),还可以是某个系统或产品正常工作(相对于失效或故障),甚至可是是客户的流失与否等。
在生存分析中,研究的主要对象是寿命超过某一时间的概率。还可以描述其他一些事情发生的概率,例如产品的失效、出狱犯人第一次犯罪、失业人员第一次找到工作等等。
在某些领域的分析中,常常用追踪的方式来研究事物的发展规律,比如研究某种药物的疗效,手术后的存活时间,某件机器的使用寿命等。
在医学研究中,常常用追踪的方式来研究事物发展的规律。如,了解某药物的疗效,了解手术的存活时间,了解某医疗仪器设备使用寿命等等。对生存资料的分析称为生存分析。所谓生存资料就是描述寿命或者一个发生时间的数据。更详细的说一个人的生存时间的长短与许多因素有联系的,研究因素与生存时间的联系有无及程度大小,称为生存分析。
例如研究病人感染了病毒后,多长时间会死亡;工作的机器多长时间会发生崩溃等。 这里“个体的存活”可以推广抽象成某些关注的事件。 所以SA就成了研究某一事件与它的发生时间的联系的方法。这个方法广泛的用在医学、生物学等学科上,近年来也越来越多人用在互联网数据挖掘中,例如用survival analysis去预测信息在社交网络的传播程度,或者去预测用户流失的概率。
生存分析研究的内容
1.描述生存过程
研究生存时间的分布特点,估计生存率及平均存活时间,绘制生存曲线等,根据生存时间的长短,可以估算出各个时点的生存率,并根据生存率来估计中位生存时间,也可以根据生存曲线分析其生存特点,一般使用Kaplan-Meier法和寿命表法。
2.比较生存过程
可通过生存率及其标准误对各样本的生存率进行比较,以探讨各组间的生存过程是否存在差异,一般使用Log-rank检验和Breslow检验。
3.分析危险因素
是通过生存分析模型来探讨影响生存时间和终点事件的保护因素和不利因素,因素作用的大小及方向,相对危险度的大小,基本使用Cox回归模型。
4.建立数学模型
建立最终的数学模型,也是通过Cox回归模型完成。
生存分析对资料的基本要求
1.样本由随机抽样方法获得,要有一定的数量,死亡例数和比例不能太少
2.完整数据所占的比例不能太少,即截尾值不宜太多
3.截尾值出现的原因无偏性,为防止偏性常常对被截尾的研究对象的年龄、职业、地区、病情轻重等情况进行分析
4.生存时间尽可能精确
5.缺项要尽量补齐
生存资料的共同特点
1.蕴含有结局和时间两个方面的信息
2.结局为两分类往斥事件
3一般是通过随访收集得到,随访观察往往是从某统一时间点(如入院或实施手术等某种处理措施后)开始,观察到某规定时间点截止。
4.常因失访等原因造成研究对象的生存时间数据不完整,分布类型复杂,不能简中地套用以前的方法
二、生存分析的基本概念
起始事件(initial event):反应生存时间起始特征的事件,如疾病确诊、某种疾病治疗开始等。
失效事件(failure event):在生存分析随访研究过程中,一部分研究对象可观察到死亡,可以得到准确的生存时间,它提供的信息是完全的,这种事件称为失效事件,也称之为死亡事件、终点事件。
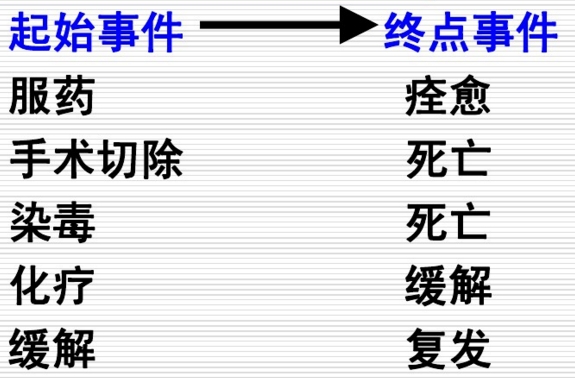
终点事件和起始事件是相对而言的,它们都由研究目的决定,须在设计时明确规定,并在研究期间严格遵守,不能随意改变。
生存时间:广义上指某个起点事件开始到某个终点事件发生所经历的时间,度量单位可以是年、月、日、小时等,常用符号t所示。这个时间也未必是通常意义上的时间,也可以是和时间相关的变量。比如距离等,具体要根据研究目的而定义。
1)分布类型不易确定。一般不服从正态分布,多数情况下不服从任何规则的分布类型。
2)影响因素多而复杂且不易控制。
3)根据研究对象的结局,生存时间数据可分为两种类型:
完全数据(Completed Data):从观察起点到发生死亡事件所经历的时间。
不完全数据(Incomplete Data):生存时间观察过程的截止不是由于死亡事件,而是由其他原因引起的
不完全数据分为:删失数据(censored Data),截断数据(truncated Data)
不完全主要原因:
失访:指失去联系;
退出:死于非研究因素或非处理因素而退出研究;
终止:设计时规定的时间已到而终止观察,但研究对象仍然存活。
删失的表现形式
右删失(Right Censoring):只知道实际寿命大于某数;
左删失(Left Censoring):只知道实际寿命小于某数;
区间删失(Interval Censoring):只知道实际寿命在一个时间区间内。
条件死亡概率:表示某时段开始存活的个体,在该时段内死亡的可能性,如年死亡概率q=某年内死亡人数/某年年初人口数,如果年内存在删失数据,需要对分母进行校正,校正人口数=年初人口数-删失例数/2
条件生存概率(conditional probability of survival):某时段开始时存活的个体,到该时段结束时让然存活的可能性p=某年存活满一年的人数/某年年初人口数=1-q,如果年内存在删失数据,需要对分母进行校正,校正人口数=年初人口数-删失例数/2
生存函数

若含有删失数据,须分时段计算生存概率。假定观察对象在各个时段的生存时间独立,应用概率乘法定理将分时段的概率相乘得到生存率。
生存率与条件生存概率不同。条件生存概率是单个时段的结果,而生存率实质上是累积条件生存概率(cumulative probability of survival ),是多个时段的累积结果。例如,3 年生存率是第1 年存活,第2 年也存活,第3 年还存活的可能性。
生存率s(t)的估计方法有参数法和非参数法。常用非参数法,非参数法主要有二个,即,乘积极限法与寿命表法,乘积极限法主要用于观察例数较少而未分组的生存资料,寿命表法适用于观察例数较多而分组的资料,不同的分组寿命表法的计算结果亦会不同,当分组资料中每一个分组区间中最多只有1个观察值时,寿命表法的计算结果与乘积极限法完全相同。
生存曲线(survival curve):以观察(随访)时间为横轴,以生存率为纵轴,将各个时间点所对应的生存率连接在一起的曲线图。
生存曲线是一条下降的曲线,分析时应注意曲线的高度和下降的坡度。平缓的生存曲线表示高生存率或较长生存期,陡峭的生存曲线表示低生存率或较短生存期。
中位生存期(median survival time):又称半数生存期,表示恰好有50 %的个体尚存活的时间。中位生存期越长,表示疾病的预后越好;中位生存期越短,预后越差。估计中位生存期常用图解法或线性内插法。
概率密度函数f(t)


生存函数S(t)

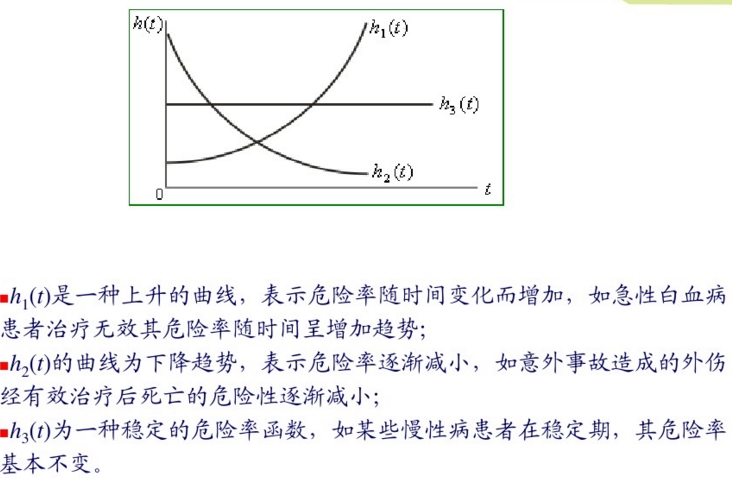
危险函数h(t)

累计危险函数H(t)
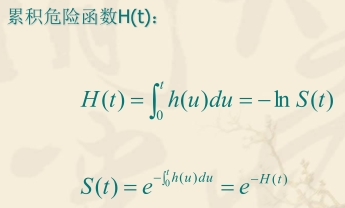

三、生存分析目的
估计 :根据样本生存资料估计总体生存率及其它有关指标 ( 如中位生存期等 ) , 如根据脑瘤患者治疗后的生存时间资料 , 估计不同时间的生存率 、生存曲线以及中位生存期等 。
比较 :对不同处理组生存率进行比较,如比较不同疗法治疗脑瘤的生存率,以了解哪种治疗方案较优。
影响因素分析 :目的是为了探索和了解影响生存时间长短的因素 , 或平衡某些因素影响后 , 研究某个或某些因素对生存率的影响 。 如为改善脑瘤病人的预后 , 应了解影响病人预后的主要因素 , 包括病人的年龄 、 性别 、 病程 、 肿瘤分期 、 治疗方案等 。
预测 :具有不同因素水平的个体生存预测 ,如根据脑瘤病人的年龄 、 性别 、 病程 、 肿瘤分期 、 治疗方案等预测该病人t 年 ( 月 )生存率 。
四、生存分析的具体方法
生存分析方法可以分为描述法、参数法、半参数法和非参数法
1.描述法
根据样本观测值提供的信息,直接用公式计算出每一个时间点或每一个时间区间上的生存函数、死亡函数、风险函数等,并采用列表或绘图的形式显示生存时间的分布规律。
优点:方法简单且对数据分布无要求
缺点:不能比较两组或多组生存时间分布函数的区别,不能分析危险因素,不能建立生存时间与危险因素之间的关系模型。
2.非参数法
估计生存函数时对生存时间的分布没有要求,并且检验危险因素对生存时间的影响时采用的是非参数检验方法。
常用方法:乘积极限法、寿命表法
优点:可以估计生存函数,可以比较两组或多组生存分布函数。可以分析危险因素对生存时间的影响,对生存时间的分布没有要求。
缺点:不能建立生存时间与危险因素之间的关系模型。
3.参数法
根据样本观测值来估计假定的分布模型中的参数,获得生存时间的概率分布模型。
生存时间经常服从的分布有:指数分布、Weibull分布、对数正态分布、对数Logistic分布、Gamma分布。
优点:可以估计生存函数,可以比较两组或多组生存分布函数。可以分析危险因素对生存时间的影响,可以建立生存时间与危险因素之间的关系模型。
缺点:需要事先知道生存时间的分布
4.半参数法
不需要对生存时间的分布做出假定,但是却可以通过一个模型来分析生存时间的分布规律,以及危险因素对生存时间的影响,最著名的就是COX回归。
优点:可以估计生存函数,可以比较两组或多组生存分布函数。可以分析危险因素对生存时间的影响,可以建立生存时间与危险因素之间的关系模型,不需要事先知道生存时间的分布。
Cox 比例风险回归模型(Cox’s proportional hazards regression model) , 简称Cox 回归模型
如果Cox PH Model中的变量会随时间变化,那么就成了extended Cox model,此时HR不再是一个常量。很简单的例子,如果病人的居住地也是一个变量,病人有可能会搬家,例如在北京吸霾了5年,再跑去厦门生活,那么他旧病复发的概率肯定会降低。所以住所这个变量是和时间相关的。一种简单的做法是,按照变量改变的时刻,把时间切割成区间,使得每个区间内的变量没有变化。然后再套用Cox PH模型。
生存分析(survival analysis)的更多相关文章
- Spark2 生存分析Survival regression
在spark.ml中,实现了加速失效时间(AFT)模型,这是一个用于检查数据的参数生存回归模型. 它描述了生存时间对数的模型,因此它通常被称为生存分析的对数线性模型. 不同于为相同目的设计的比例风险模 ...
- 生存模型(Survival Model)介绍
https://www.cnblogs.com/BinbinChen/p/3416972.html 生存分析,维基上的解释是: 生存分析(Survival analysis)是指根据试验或调查得到的数 ...
- survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载. 生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系.例如研究病人感染了病毒后,多长时间会死亡:工作的机器多长时间会发生崩溃等. ...
- BMDP为常规的统计分析提供了大量的完备的函数系统,如:方差分析(ANOVA)、回归分析(Regression)、非参数分析(Nonparametric Analysis)、时间序列(Times Series)等等。此外,BMDP特别擅于进行出色的生存分析(Survival Analysis )。许多年来,一大批世界范围内顶级的统计学家都曾今参与过BMDP的开发工作。这不仅使得BMDP的权威性得到
BMDP是Bio Medical Data Processing的缩写,是世界级的统计工具软件,至今已经有40多年的历史.目前在国际上与SAS.SPSS被并称为三大统计软件包.BMDP是一个大 ...
- 生存分析与R--转载
生存分析与R 生存分析是将事件的结果和出现这一结果所经历的时间结合起来分析的一类统计分析方法.不仅考虑事件是否出现,而且还考虑事件出现的时间长短,因此这类方法也被称为事件时间分析(time-to-ev ...
- 生存分析与R
生存分析与R 2018年05月19日 19:55:06 走在码农路上的医学狗 阅读数:4399更多 个人分类: R语言 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- WOE:信用评分卡模型中的变量离散化方法(生存分析)
WOE:信用评分卡模型中的变量离散化方法 2016-03-21 生存分析 在做回归模型时,因临床需要常常需要对连续性的变量离散化,诸如年龄,分为老.中.青三组,一般的做法是ROC或者X-tile等等. ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
- Cox回归模型【生存分析】
参考:<复杂数据统计方法--基于R的应用> 吴喜之 在生存分析中,研究的主要对象是寿命超过某一时间的概率.还可以描述其他一些事情发生的概率,例如产品的失效.出狱犯人第一次犯罪.失业人员第一 ...
随机推荐
- Windows 7 完美安装 Visual C++ 6.0
http://wenku.baidu.com/link?url=UiwoH2l4H_IWK6y8JkVNg4slp8gkM_9qudihP0XD4MdMCwm-j1-vINWEjQE1aBCeP121 ...
- BarTender软件中GS1-128条码如何制作?
GS1-128条码是UCC/EAN-128条码的新名字,它只是Code 128的一个特殊子集.GS1-128条码是EAN·UCC系统中唯一可用于表示附加信息的条码,可广泛用于非零售贸易项目.物流单元. ...
- windows 7 64位出现Oracle中文乱码
提示oracle客户端无法连接指定字符 安装好客户端之后,如图 将数据库dbhome_1中的network文件夹全部复制到客户端,如图 然后在设置环境变量:F:\app\Administrator\p ...
- java图片裁剪和java生成缩略图
一.缩略图 在浏览相冊的时候.可能须要生成相应的缩略图. 直接上代码: public class ImageUtil { private Logger log = LoggerFactory.getL ...
- Okhttp封装、网络层扩展
一.概述 首先在这里本片文章是以网络通信封装为主,而app开发首先重要就是网络通信,而如今主流的async.volley.okhttp等,阿么这么网络库怎样能做到更好封装.更好的切换,从而不影响业务层 ...
- 5 -- Hibernate的基本用法 --4 1 创建Configuration对象
org.hibernate.cfg.Configuration实例代表了应用程序到SQL数据库的配置信息,Configuration对象提供了一个buildSessionFactory()方法,该方法 ...
- mybatis generator配置,Mybatis自动生成文件配置,Mybatis自动生成实体Bean配置
mybatis generator配置,Mybatis自动生成文件配置,Mybatis自动生成实体Bean配置 ============================== 蕃薯耀 2018年3月14 ...
- Java Cookie工具类,Java CookieUtils 工具类,Java如何增加Cookie
Java Cookie工具类,Java CookieUtils 工具类,Java如何增加Cookie >>>>>>>>>>>>& ...
- 客户端远程连接linux下mysql数据库授权
mysql默认状态是只支持localhost连接,这样远程服务器都输入IP地址去连接你的服务器是不可以的,下面我来介绍怎么让mysql允许远程连接配置方法,有需要的朋友可参考. 方法一,直接利用p ...
- springmvc接收前台(可以是ajax)传来的数组list,map,set等集合,复杂对象集合等图文详解
参考帖子: http://blog.csdn.net/wabiaozia/article/details/50803581 方法参考: { "token":"" ...