memcached学习笔记——存储命令源码分析上篇
原创文章,转载请标明,谢谢。
上一篇分析过memcached的连接模型,了解memcached是如何高效处理客户端连接,这一篇分析memcached源码中的process_update_command函数,探究memcached客户端的set命令,解读memcached是如何解析客户端文本命令,剖析memcached的内存管理,LRU算法是如何工作等等。
解析客户端文本命令
客户端向memcached server发出set操作,memcached server读取客户端的命令,客户端的连接状态由 conn_read > conn_parse_cmd 转换,这时候,memcached server开始解析命令。memcached server调用try_read_command函数解析命令,memcached接收两种格式的命令,一种是二进制格式,另一种是文本格式(本文只讲文本格式的命令)。
static int try_read_command(conn *c) {
// ..........
if (c->protocol == binary_prot) {
// 二进制格式
// ....
} else {
char *el, *cont;
// 没有接收到客户端的命令,返回进入conn_waiting状态,等待更多的客户端数据
if (c->rbytes == )
return ;
el = memchr(c->rcurr, '\n', c->rbytes);
if (!el) {
if (c->rbytes > ) {
/*
* We didn't have a '\n' in the first k. This _has_ to be a
* large multiget, if not we should just nuke the connection.
*/
char *ptr = c->rcurr;
while (*ptr == ' ') { /* ignore leading whitespaces */
++ptr;
}
if (ptr - c->rcurr > ||
(strncmp(ptr, "get ", ) && strncmp(ptr, "gets ", ))) {
conn_set_state(c, conn_closing);
return ;
}
}
return ;
}
// 客户端报文以'\r\n'结尾
cont = el + ;
if ((el - c->rcurr) > && *(el - ) == '\r') {
el--;
}
*el = '\0';
assert(cont <= (c->rcurr + c->rbytes));
// 真正解析命令的地方
process_command(c, c->rcurr);
c->rbytes -= (cont - c->rcurr);
c->rcurr = cont;
assert(c->rcurr <= (c->rbuf + c->rsize));
}
return ;
}
在分析process_command函数前,我们先看看memcached的命令格式:
<command name> <key> <flags> <exptime> <bytes> [noreply]\r\n
cas <key> <flags> <exptime> <bytes> <cas unique> [noreply]\r\n
// 例如 set 命令 :
set key
STORED
// 空格对应着空格
set => <command name>
key => <key>
=> <flags>
=> <exptime>
=> <bytes>
memcached在process_command中调用tokenize_command函数根据上面的命令格式处理命令,把相应位置的字段保存在 token_t *tokens 的相应位置。
// 参数1:命令的字符串
// 参数2:解析命令后,存放命令各个字段的结构体数组
// 参数3:命令字段的最大数量
/*
* tokens[0] => <command name> 的信息
* tokens[1] => <key> 的信息
* tokens[2] => <flags> 的信息
*/
static size_t tokenize_command(char *command, token_t *tokens, const size_t max_tokens) {
char *s, *e;
size_t ntokens = ;
size_t len = strlen(command);
unsigned int i = ; assert(command != NULL && tokens != NULL && max_tokens > ); s = e = command;
for (i = ; i < len; i++) {
if (*e == ' ') {
if (s != e) {
tokens[ntokens].value = s; // value存放各个字段的字符串值,例如:'set'
tokens[ntokens].length = e - s; // length表示各个字段相应的长度,例如:'set'的长度为3
ntokens++;
*e = '\0';
if (ntokens == max_tokens - ) {
e++;
s = e; /* so we don't add an extra token */
break;
}
}
s = e + ;
}
e++;
} if (s != e) {
tokens[ntokens].value = s;
tokens[ntokens].length = e - s;
ntokens++;
} /*
* If we scanned the whole string, the terminal value pointer is null,
* otherwise it is the first unprocessed character.
*/
tokens[ntokens].value = *e == '\0' ? NULL : e;
tokens[ntokens].length = ;
ntokens++; return ntokens;
}
解析完文本命令后,回到process_command函数中,我们可以看到很熟悉的命令,是的,接下来,在一个if-else的多分支判断中,memcached根据tokens[COMMAND_TOKEN].value决定调用那一个函数处理相应的命令:
static void process_command(conn *c, char *command) {
// ....
ntokens = tokenize_command(command, tokens, MAX_TOKENS);
if (ntokens >= &&
((strcmp(tokens[COMMAND_TOKEN].value, "get") == ) ||
(strcmp(tokens[COMMAND_TOKEN].value, "bget") == ))) {
// 这里就是执行get命令的分支
process_get_command(c, tokens, ntokens, false);
} else if ((ntokens == || ntokens == ) &&
((strcmp(tokens[COMMAND_TOKEN].value, "add") == && (comm = NREAD_ADD)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "set") == && (comm = NREAD_SET)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "replace") == && (comm = NREAD_REPLACE)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "prepend") == && (comm = NREAD_PREPEND)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "append") == && (comm = NREAD_APPEND)) )) {
// 这里就是执行set、add、replace等命令的分支
process_update_command(c, tokens, ntokens, comm, false);
} else if ((ntokens == || ntokens == ) && (strcmp(tokens[COMMAND_TOKEN].value, "cas") == && (comm = NREAD_CAS))) {
// 这里也执行process_update_command函数,也是对相应的key执行写操作,与上面一个分支不同的是最后一个参数是true,意思是写的过程使用CAS协议,这里不侧重讲,
// CAS目的是保证在并发写的时候保证一致性
process_update_command(c, tokens, ntokens, comm, true);
} else if .............
memcached存储命令分析
memcached把内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合),每个chunk集合被称为slab。Memcached的内存分配以Page为单位,Page默认值为1M,可以在启动时通过-I参数来指定。Slab是由多个Page组成的,Page按照指定大小切割成多个chunk。
每一对[key,value]的数据被封装到item的结构体里,每种类型的slab用一个item链表来维护它的所有item。例如,一个item项的数据大小加上item的头部信息(为了方便描述,下面把这两项的和统称[key,value]大小吧)是90KB,slab[i]的chunk块大小是136KB,slab[i-1]的chunk块大小是88KB,那么item会被分配slab[i]的一个chunk块(并保存到slab[i]维护的一个item链表),这样做的目的是为了尽量减少内存碎片。更多关于Slab Allocation的原理可以查找其他的资料。这里不详解
memcached的存储命令:add、set、replace、append、prepend等,上面简单地说了memcached slab机制,知道memcached是根据相应的[key,value]大小找到相应的slab,那么,我们再次调用set命令某个已存在的key的value的时候,memcached是怎么工作的呢?
起初,我的直觉思维是,找到key相应的item,修改item的value就好了。那么,问题来了,假如先前[key,value]大小是90KB,被分配到slab[i]的,现在我们修改了key对应的value,[key,value]大小也改变了,变成了80KB,应该分配到slab[i-1]的,如果只是修改原来item的数据,那么就不符合Slab Allocation的原理,会造成很大的内存碎片浪费。
memcached对存储命令:add、set、replace、append、prepend处理方法大体都相似的,从上面的源码可以看出,都是通过执行process_update_command函数来处理。
memcached的处理存储命令思路是这样的:例如,客户端的一个set命令,memcached都会重新根据[key,value]大小找到合适slab,并把相应的数据封装到新的item里面【源码的注1】(不会直接修改旧的item项),如果对应的slab没有内存空间不足,就调用LRU算法把该slab的一个最近最少使用项的空间分配给新的item【源码的注2,出现在do_item_alloc函数】(如果关闭LRU移除项的功能,那么就会报“SERVER_ERROR out of memory storing object”错误,是set命令的话,还会把key对应的旧的item项移除【源码的注3】,即我们这时候不能通过get key来获取到旧的数据了),分配空间成功,那就是对add、set、replace、append、prepend这几个存储命令做差异化处理。
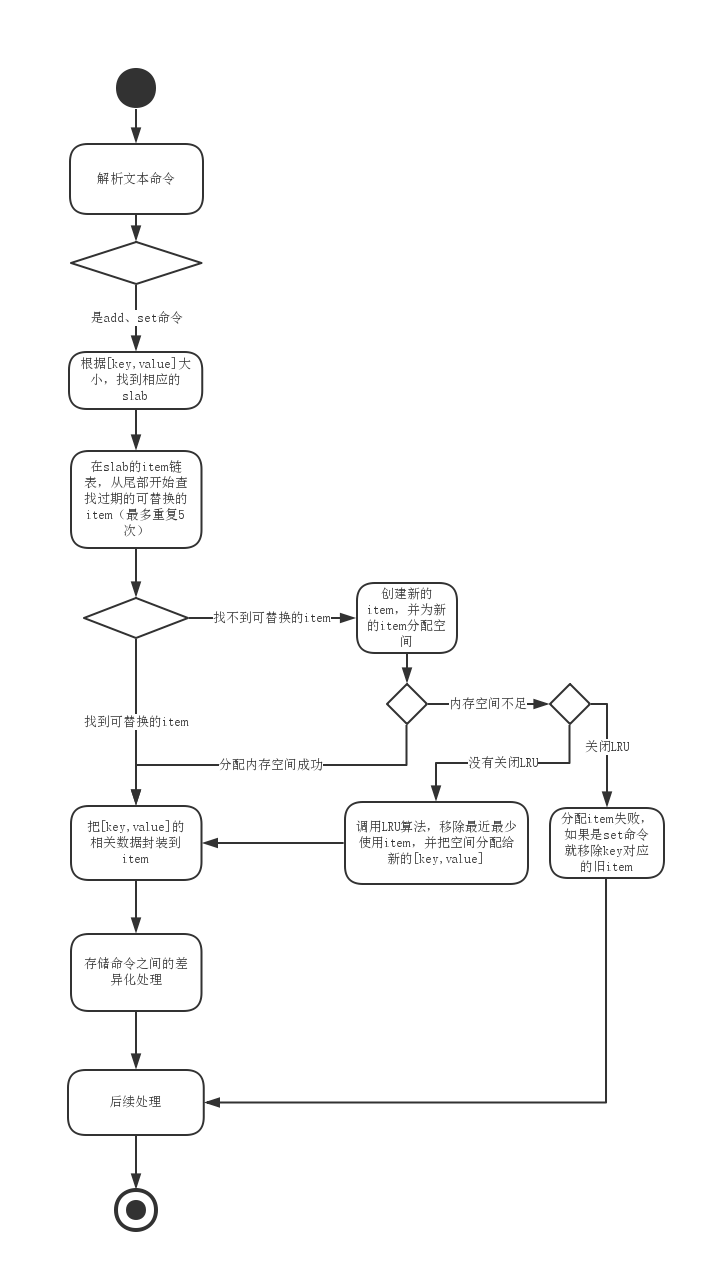
static void process_update_command(conn *c, token_t *tokens, const size_t ntokens, int comm, bool handle_cas) {
// ....
set_noreply_maybe(c, tokens, ntokens); // 设置命令可选字段的[noreply]
if (tokens[KEY_TOKEN].length > KEY_MAX_LENGTH) {
out_string(c, "CLIENT_ERROR bad command line format");
return;
}
key = tokens[KEY_TOKEN].value;
nkey = tokens[KEY_TOKEN].length;
// 把命令相应字段的字符串安全转换成整数
if (! (safe_strtoul(tokens[].value, (uint32_t *)&flags)
&& safe_strtol(tokens[].value, &exptime_int)
&& safe_strtol(tokens[].value, (int32_t *)&vlen))) {
out_string(c, "CLIENT_ERROR bad command line format");
return;
}
exptime = exptime_int;
// #define REALTIME_MAXDELTA 60*60*24*30
if (exptime < )
exptime = REALTIME_MAXDELTA + ;
// CAS协议,防止并发写不一致
if (handle_cas) {
if (!safe_strtoull(tokens[].value, &req_cas_id)) {
out_string(c, "CLIENT_ERROR bad command line format");
return;
}
}
// ........
// 注1:无论是add、set或者是replace命令,都会从新分配一个新的item
it = item_alloc(key, nkey, flags, realtime(exptime), vlen);
// 如果新的item分配失败
if (it == ) {
if (! item_size_ok(nkey, flags, vlen))
out_string(c, "SERVER_ERROR object too large for cache"); // 一种错误情况:数据太大,没有合适slab,不能缓存数据
else
out_string(c, "SERVER_ERROR out of memory storing object"); // 另一种是:没有了内存空间缓存数据,通常这种事在关闭LRU功能的情况下出现
/* swallow the data line */
c->write_and_go = conn_swallow;
c->sbytes = vlen;
// 注3:新的item分配失败,如果是set命令,并且key对应着存在旧的item,那么就把旧的item删除
if (comm == NREAD_SET) {
it = item_get(key, nkey);
if (it) {
item_unlink(it);
item_remove(it);
}
}
return;
}
ITEM_set_cas(it, req_cas_id);
c->item = it;
c->ritem = ITEM_data(it);
c->rlbytes = it->nbytes;
c->cmd = comm;
// 会在这一步进行add、set、replace等存储命令的差异化处理
conn_set_state(c, conn_nread);
}
do_item_alloc函数:
item *do_item_alloc(char *key, const size_t nkey, const int flags,
const rel_time_t exptime, const int nbytes,
const uint32_t cur_hv) {
uint8_t nsuffix;
item *it = NULL;
char suffix[];
size_t ntotal = item_make_header(nkey + , flags, nbytes, suffix, &nsuffix); //接收到的item数据长度+item头部长度
if (settings.use_cas) {
ntotal += sizeof(uint64_t);
} unsigned int id = slabs_clsid(ntotal);
if (id == )
return ; mutex_lock(&cache_lock);
/* do a quick check if we have any expired items in the tail.. */
int tries = ;
int tried_alloc = ;
item *search;
void *hold_lock = NULL;
rel_time_t oldest_live = settings.oldest_live; search = tails[id]; // tries = 5 ,循环查找过期的item,最多循环5次
for (; tries > && search != NULL; tries--, search=search->prev) {
uint32_t hv = hash(ITEM_key(search), search->nkey, ); // 如果当前item被上锁,那么就跳过
if (hv != cur_hv && (hold_lock = item_trylock(hv)) == NULL)
continue;
/* Now see if the item is refcount locked */
if (refcount_incr(&search->refcount) != ) {
refcount_decr(&search->refcount);
/* Old rare bug could cause a refcount leak. We haven't seen
* it in years, but we leave this code in to prevent failures
* just in case */
if (search->time + TAIL_REPAIR_TIME < current_time) {
itemstats[id].tailrepairs++;
search->refcount = ;
do_item_unlink_nolock(search, hv);
}
if (hold_lock)
item_trylock_unlock(hold_lock);
continue;
} // item过期,如果没有设置过期时间,那么就使用系统设置的默认过期时间
if ((search->exptime != && search->exptime < current_time)
|| (search->time <= oldest_live && oldest_live <= current_time)) {
itemstats[id].reclaimed++;
if ((search->it_flags & ITEM_FETCHED) == ) {
itemstats[id].expired_unfetched++;
}
it = search;
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal); // 当前搜索的item过期,重新计算slab已经分配的字节
do_item_unlink_nolock(it, hv); // 把当前搜索的item从链表中移除
/* Initialize the item block: */
it->slabs_clsid = ;
} else if ((it = slabs_alloc(ntotal, id)) == NULL) { // 没有找到过期的item,新分配一个item,分配失败就执行else if里面的代码
tried_alloc = ;
if (settings.evict_to_free == ) { // 注2:内存耗尽,如果evict_to_free = 1(默认)LRU算法启动,移除最近最少使用的item
itemstats[id].outofmemory++;
} else {
itemstats[id].evicted++;
itemstats[id].evicted_time = current_time - search->time;
if (search->exptime != )
itemstats[id].evicted_nonzero++;
if ((search->it_flags & ITEM_FETCHED) == ) {
itemstats[id].evicted_unfetched++;
}
it = search;
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal); // 当前搜索的item过期,重新计算slab已经分配的字节
do_item_unlink_nolock(it, hv); // 把当前需要移除的item从链表中移除
/* Initialize the item block: */
it->slabs_clsid = ; if (settings.slab_automove == )
slabs_reassign(-, id);
}
} refcount_decr(&search->refcount);
/* If hash values were equal, we don't grab a second lock */
if (hold_lock)
item_trylock_unlock(hold_lock);
break;
} if (!tried_alloc && (tries == || search == NULL))
it = slabs_alloc(ntotal, id); if (it == NULL) {
itemstats[id].outofmemory++;
mutex_unlock(&cache_lock);
return NULL;
} assert(it->slabs_clsid == );
assert(it != heads[id]); it->refcount = ;
mutex_unlock(&cache_lock);
it->next = it->prev = it->h_next = ;
it->slabs_clsid = id; DEBUG_REFCNT(it, '*');
it->it_flags = settings.use_cas ? ITEM_CAS : ;
it->nkey = nkey;
it->nbytes = nbytes;
memcpy(ITEM_key(it), key, nkey);
it->exptime = exptime;
memcpy(ITEM_suffix(it), suffix, (size_t)nsuffix);
it->nsuffix = nsuffix;
return it;
}
以上memcached只是为[key,value]找到了新的slab,分配了新的item,并把命令相关的头部信息保存到,但是,还有一个重要的步奏没有说的,那就是[key,value]中的value怎么和item关联起来的,add和set的区别又是怎样区分的,由于还有很长的一段代码,所以我还是分篇记录,预告一下,下一篇《memcached学习笔记——存储命令源码分析下》会讲遗留的这两个问题。
未完,待续。
更多阅读查看:JC&hcoding
memcached学习笔记——存储命令源码分析上篇的更多相关文章
- memcached学习笔记——存储命令源码分析下篇
上一篇回顾:<memcached学习笔记——存储命令源码分析上篇>通过分析memcached的存储命令源码的过程,了解了memcached如何解析文本命令和mencached的内存管理机制 ...
- tornado 学习笔记6 Application 源码分析
Application 是Tornado重要的模块之一,主要是配置访问路由表及其他应用参数的设置. 源代码位于虚拟运行环境文件夹下(我的是env),具体位置为env > lib>sit-p ...
- [Golang学习笔记] 02 命令源码文件
源码文件的三种类型: 命令源文件:可以直接运行的程序,可以不编译而使用命令“go run”启动.执行. 库源码文件 测试源码文件 面试题:命令源码文件的用途是什么,怎样编写它? 典型回答: 命令源码文 ...
- OA学习笔记-010-Struts部分源码分析、Intercepter、ModelDriver、OGNL、EL
一.分析 二. 1.OGNL 在访问action前,要经过各种intercepter,其中ParameterFilterInterceptor会把各咱参数放到ValueStack里,从而使OGNL可以 ...
- Laravel学习笔记之Session源码解析(上)
说明:本文主要通过学习Laravel的session源码学习Laravel是如何设计session的,将自己的学习心得分享出来,希望对别人有所帮助.Laravel在web middleware中定义了 ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- debug:am、cmd命令源码分析
debug:am.cmd命令源码分析 目录 debug:am.cmd命令源码分析 am命令的实现 手机里的am am.jar cmd命令的实现 手机里的cmd cmd activity cmd.cpp ...
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- TiDB show processlist命令源码分析
背景 因为丰巢自去年年底开始在推送平台上尝试了TiDB,最近又要将承接丰巢所有交易的支付平台切到TiDB上.我本人一直没有抽出时间对TiDB的源码进行学习,最近准备开始一系列的学习和分享.由于我本人没 ...
随机推荐
- ubuntu安装aircrack-ng/reaver/minidwep-gtk用来跑pin
按照下面安装方法,可以在Ubuntu 13.04中启动 minidwep.Tested with Ubuntu 13.04 1. Dependencies Code: sudo apt-g ...
- 转:perror和strerror的区别
概述: perror和strerror都是C语言提供的库函数,用于获取与erno相关的错误信息,区别不大,用法也简单.最大的区别在于perror向stderr输出结果,而 strerror向stdou ...
- C51汇编语言完整源码
单片机最小系统,两位LED数码管由串口输出接两个164驱动,Lout,Rout为左右声道输出,SET, ALT0, ALT1为三个按键,也可自己在开始的I/O定义改成你想用的I/O口:12M晶振,若 ...
- VS2008 运行VC\Bin下的link.exe, cl.exe, lib.exe提示找不到mspdb80.dll的解决方法
天在用link.EXE的LIB命令生成用于连接(LINK)使用的lib文件时提示:找不到mspdb80.dll. 原因:Microsoft Visual Studio\VC\Bin\下没有 “msob ...
- 最全的TV视频应用合集,包含50多款客户端,有丰富直播点播
这是我目前找到的 最好的视频应用合集,与坛友分享下.有50多款视频客户端,基本覆盖目前市面上口碑比较好的视频应用了. 里面有丰富的直播客户端,像 龙龙直播.泰捷直播.果子 Tv.More Tv等,还有 ...
- 【HDOJ】4541 Ten Googol
打表的大水题. /* 4541 */ #include <cstdio> #include <cstdlib> #include <cstring> , , , } ...
- COJ 0999 WZJ的数据结构(负一)
WZJ的数据结构(负一) 难度级别:D: 运行时间限制:1000ms: 运行空间限制:262144KB: 代码长度限制:2000000B 试题描述 输入N个模板串Pi和文本串T,输出每个模板串Pi在T ...
- MFC单文档自定义扩展名及添加图标报Assertion错误
忽然无聊的想给自己写的程序保存的文件使用自己的名字简写作为后缀,于是有了下文. IDR_MAINFRAME格式介绍 IDR_MAINFRAME字符串资源中包含7个子串,分别以/n结束,即如下格式: & ...
- 超酷创意HTML5动画演示及代码
HTML5是未来的网页开发神器,今天分享的这些HTML5动画大部分利用了CSS3的动画属性来实现,废话不多说,直接上演示和代码. HTML5/CSS3实现大风车旋转动画 这次我们要来分享一款很酷的HT ...
- velocity序列动画
结合上次提到的velocity的UI Pack存在一下问题: 动画名称过长,语意性差 使用UI Pack的动画,loop属性会失效 无法监听动画完成时机 我这里想到了一种解决 ...