Hadoop 电话通信清单
一、实例要求
现有一批电话通信清单,记录了用户A拨打某些特殊号码(如120,10086,13800138000等)的记录。需要做一个统计结果,记录拨打给用户B的所有用户A。
二、测试样例
样例输入:
file.txt:
13599999999 10086
13899999999 120
13944444444 1380013800
13722222222 1380013800
18800000000 120
13722222222 10086
18944444444 10086
样例输出:
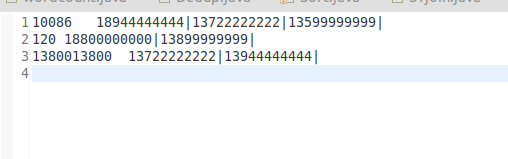
三、算法思路
源文件——》Mapper(分隔原始数据,以被叫作为key,以主叫作为value)——》Reducer(把拥有相同被叫的主叫号码用|分隔汇总)——》输出到HDFS
四、程序代码
程序代码如下:
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class Tel { public static class Map extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
String line = value.toString();
Text word = new Text();
String [] lineSplite = line.split(" ");
String anum = lineSplite[0];
String bnum = lineSplite[1];
context.write(new Text(bnum), new Text(anum));
}
} public static class Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
String valueString;
String out ="";
for(Text value: values){
valueString=value.toString();
out += valueString+"|";
}
context.write(key, new Text(out));
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"Tel");
job.setJarByClass(Tel.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
} }
Hadoop 电话通信清单的更多相关文章
- 想从事分布式系统,计算,hadoop等方面,需要哪些基础,推荐哪些书籍?--转自知乎
作者:廖君链接:https://www.zhihu.com/question/19868791/answer/88873783来源:知乎 分布式系统(Distributed System)资料 < ...
- 从事分布式系统,计算,hadoop
作者:廖君链接:https://www.zhihu.com/question/19868791/answer/88873783来源:知乎 分布式系统(Distributed System)资料 < ...
- mapreduce编程练习(二)倒排索引 Combiner的使用以及练习
问题一:请使用利用Combiner的方式:根据图示内容编写maprdeuce程序 示例程序 package com.greate.learn; import java.io.IOException; ...
- 分布式系统(Distributed System)资料
这个资料关于分布式系统资料,作者写的太好了.拿过来以备用 网址:https://github.com/ty4z2008/Qix/blob/master/ds.md 希望转载的朋友,你可以不用联系我.但 ...
- [Hadoop in Action] 第7章 细则手册
向任务传递定制参数 获取任务待定的信息 生成多个输出 与关系数据库交互 让输出做全局排序 1.向任务传递作业定制的参数 在编写Mapper和Reducer时,通常会想让一些地方可以配 ...
- [Hadoop in Action] 第6章 编程实践
Hadoop程序开发的独门绝技 在本地,伪分布和全分布模式下调试程序 程序输出的完整性检查和回归测试 日志和监控 性能调优 1.开发MapReduce程序 [本地模式] 本地模式 ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- [hadoop in Action] 第3章 Hadoop组件
管理HDFS中的文件 分析MapReduce框架中的组件 读写输入输出数据 1.HDFS文件操作 [命令行方式] Hadoop的文件命令采取的形式为: hadoop fs -cmd < ...
随机推荐
- WMI参数介绍
Win32_DiskDrive 硬盘 参数说明 vailability --设备的状态.BytesPerSector --在每个扇区的物理磁盘驱动器的字节数.Capabilities --媒体访 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- C#编码问题以及C#往Mysql插数据编码问题
C#将字符转换成utf8编码 GB321编码转换 public static string get_uft8(string unicodeString) { UTF8Encoding utf8 = ...
- layui与echarts
https://pan.baidu.com/s/1qM5ybqD-wAQNnWubdegBiA 在此感谢Layui给我这种不懂前端的人很大的帮助
- linux内存黑洞
1.问题 k8s集群中node节点的内存使用率居高不下,使用率达到90%多.通过以下命令可以发现此虚拟机分配的内存为15g,但是用户进程使用的内存总共为7个多g,并且slab和pageTables使用 ...
- Oracle通过SCN做增量备份修复DG
DG由于网络原因或者bug原因经常不同步,有时隔得时间久了,就会丢失归档日志,或者长时间的归档恢复较慢,有一种可以基于scn的方式来恢复DG库,使用基于scn的增量备份来恢复standby库可以节省大 ...
- Pytorch之训练器设置
Pytorch之训练器设置 引言 深度学习训练的时候有很多技巧, 但是实际用起来效果如何, 还是得亲自尝试. 这里记录了一些个人尝试不同技巧的代码. tensorboardX 说起tensorflow ...
- 非WifI环境处理
//1.创建网络状态监测管理者 AFNetworkReachabilityManager *mangerStatus = [AFNetworkReachabilityManager sharedMan ...
- AX2009 批处理作业中使用多线程---顶级采摘
顶级采摘 是前两种模式的一种混合,使用使用实体表存储单任务模式那样的每个工单,任务每次都取顶行做操作.单任务数不想单任务模式,一个工单一个任务.而是类似批量捆绑那样设置任务数.表:demoTopPic ...
- spring+struts+hibernate整合
spring整合: 1:添加配置文件和相应的spring jar包(记得一定要加上commons-logging的jar包,有坑****) 2:创建date对象,如果成功则spring的环境ok