一起学Hadoop——使用自定义Partition实现hadoop部分排序
public class PartSortMap extends Mapper<LongWritable,Text,Text,Text> {
public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
String line = value.toString();//读取一行数据,数据格式为“Apple 201701 30”
String str[] = line.split(" ");//
//年月当做key值,因为要根据key值设置分区,而Apple+“_”+销量当做value
context.write(new Text(str[1]),new Text(str[0] + "_" + str[2]));
}
}
public class PartParttition extends Partitioner<Text, Text> {
public int getPartition(Text arg0, Text arg1, int arg2) {
String key = arg0.toString();
int month = Integer.parseInt(key.substring(4, key.length()));
if (month == 1) {
return 1 % arg2;
} else if (month == 2) {
return 2 % arg2;
} else if (month == 3) {
return 3 % arg2;
}else if (month == 4) {
return 4 % arg2;
}else if (month == 5) {
return 5 % arg2;
}else if (month == 6) {
return 6 % arg2;
}else if (month == 7) {
return 7 % arg2;
}else if (month == 8) {
return 8 % arg2;
}else if (month == 9) {
return 9 % arg2;
}else if (month == 10) {
return 10 % arg2;
}else if (month == 11) {
return 11 % arg2;
}else if (month == 12) {
return 12 % arg2;
}
return 0;
}
}
public class PartSortReduce extends Reducer<Text,Text,Text,Text> {
class FruitSales implements Comparable<FruitSales>{
private String name;//水果名字
private double sales;//水果销量
public void setName(String name){
this.name = name;
}
public String getName(){
return this.name;
}
public void setSales(double sales){
this.sales = sales;
}
public double getSales() {
return this.sales;
}
@Override
public int compareTo(FruitSales o) {
if(this.getSales() > o.getSales()){
return -1;
}else if(this.getSales() == o.getSales()){
return 0;
}else {
return 1;
}
}
}
public void reduce(Text key, Iterable<Text> values,Context context)throws IOException,InterruptedException{
List<FruitSales> fruitList = new ArrayList<FruitSales>();
for(Text value: values) {
String[] str = value.toString().split("_");
FruitSales f = new FruitSales();
f.setName(str[0]);
f.setSales(Double.parseDouble(str[1]));
fruitList.add(f);
}
Collections.sort(fruitList);
for(FruitSales f : fruitList){
context.write(new Text(f.getName()),new Text(String.valueOf(f.getSales())));
}
}
}
public class PartSortMain {
public static void main(String[] args)throws Exception{
Configuration conf = new Configuration();
//获取运行时输入的参数,一般是通过shell脚本文件传进来。
String [] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.err.println("必须输入读取文件路径和输出路径");
System.exit(2);
}
Job job = new Job();
job.setJarByClass(PartSortMain.class);
job.setJobName("PartSort app");
//设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setPartitionerClass(PartParttition.class);//设置自定义partition类
job.setNumReduceTasks(12);//设置为partiton数量
//设置实现了map函数的类
job.setMapperClass(PartSortMap.class);
//设置实现了reduce函数的类
job.setReducerClass(PartSortReduce.class);
//设置reduce函数的key值
job.setOutputKeyClass(Text.class);
//设置reduce函数的value值
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 :1);
}
}

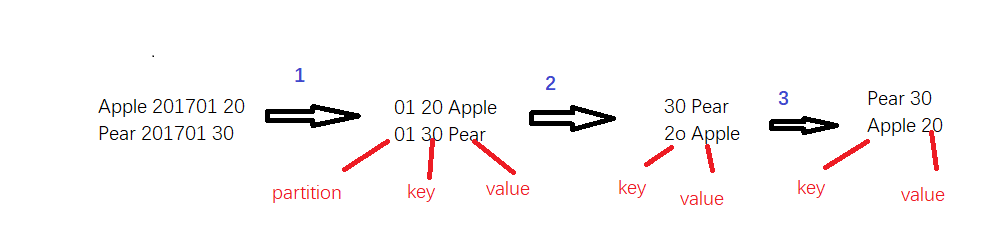
#!/usr/bin/python
import sys
base_numer = 99999
for line in sys.stdin:
ss = line.strip().split(' ')
fruit = ss[0]
yearmm = ss[1]
sales = ss[2]
new_key = base_number - int(sales)
mm = yearmm[4:6]
print "%s\t%s\t%s" % (int(mm), int(new_key), fruit)
#!/usr/bin/python
import sys
base_number = 99999
for line in sys.stdin:
idx_id, sales, fruit = line.strip().split('\t')
new_key = base_number - int(sales)
print '\t'.join([val, str(new_key)])
set -e -x
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH_A="/data/fruit.txt"
OUTPUT_SORT_PATH="/output_sort"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python reduce_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py \
-jobconf mapred.reduce.tasks= \
-jobconf stream.num.map.output.key.fields= \
-jobconf num.key.fields.for.partition= \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
一起学Hadoop——使用自定义Partition实现hadoop部分排序的更多相关文章
- 2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢? 达到下面这种效果, 默认是根据key来排, 我想根据value里的某个排, 解决思路:将value里的某个,放到key里去,然后来排 下面,开始w ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- commoncrawl 源码库是用于 Hadoop 的自定义 InputFormat 配送实现
commoncrawl 源码库是用于 Hadoop 的自定义 InputFormat 配送实现. Common Crawl 提供一个示例程序 BasicArcFileReaderSample.java ...
- Hadoop mapreduce自定义分组RawComparator
本文发表于本人博客. 今天接着上次[Hadoop mapreduce自定义排序WritableComparable]文章写,按照顺序那么这次应该是讲解自定义分组如何实现,关于操作顺序在这里不多说了,需 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 《Hadoop》对于高级编程Hadoop实现构建企业级安全解决方案
本章小结 ● 理解企业级应用的安全顾虑 ● 理解Hadoop尚未为企业级应用提供的安全机制 ● 考察用于构建企业级安全解决方式的方法 第10章讨论了Hadoop安全性以及Hadoop ...
- [BigData - Hadoop - YARN] YARN:下一代 Hadoop 计算平台
Apache Hadoop 是最流行的大数据处理工具之一.它多年来被许多公司成功部署在生产中.尽管 Hadoop 被视为可靠的.可扩展的.富有成本效益的解决方案,但大型开发人员社区仍在不断改进它.最终 ...
- hadoop分布式存储(2)-hadoop的安装(毕业设计)
总共分三步:1.准备linux环境 租用"云主机",阿里云,unitedStack等,云主机不受本机性能影响(或者直接安转linux操作系统或者虚拟机也行): PuTTy Conf ...
随机推荐
- RT-thread嵌入式操作系统相关的问题
面试中问到 RT-thread嵌入式操作系统相关的问题 RT-thread操作系统调度器的实现细节 RT-Thread中提供的线程调度器是基于优先级的全抢占式调度: 在系统中除了中断处理函数.调度器上 ...
- FFmpeg Scaler Options
算法 帧率 图像主观感受 SWS_FAST_BILINEAR 228 图像无明显失真,感觉效果很不错. SWS_BILINEAR 95 感觉也很不错,比上一个算法边缘平滑一些. SWS_BICUBIC ...
- 【Tomcat】tomcat内存配置登记册
20141202: 环境:windows2003 tomcat6.x jdk1.6 启动方式:windows服务方式启动 启动异常:java.lang.OutOfMemoryError: PermGe ...
- Ubuntu升级GCC到gcc4.8
http://www.qtcn.org/bbs/apps.php?q=diary&a=detail&did=1456&uid=139371Ubuntu最新gcc版本在ppa:u ...
- Spring通过SchedulerFactoryBean实现调度任务的配置(定时器)
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- Android 各种路径详细说明
存储分类: 内部存储路径, 内部缓存存储路径, 外部存储路径, 外部缓存存储路径 在有些手机上内部划出一个内部的sdcard路径和内部存储路径,当有sdcard时候,就有了六个路径 内部存储空间中的应 ...
- Java二叉树的实现与特点
二叉树是一种非常重要的数据结构,它同时具有数组和链表各自的特点:它可以像数组一样快速查找,也可以像链表一样快速添加.但是他也有自己的缺点:删除操作复杂. 我们先介绍一些关于二叉树的概念名词. 二叉树: ...
- swift 实践- 11 -- UISlider
import UIKit class ViewController: UIViewController { override func viewDidLoad() { super.viewDidLoa ...
- 《深入理解Oracle 12c数据库管理(第二版)》PDF
一:下载获取位置: 二:本书图样: 三:本书目录: 图书目录: 第1章 安装Oracle 1.1 了解OFA 1.1.1 Oracle清单目录 1.1.2 Oracle基础目录 1.1.3 Oracl ...
- HTML5-长按事件
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title> ...