LeNet训练MNIST
jupyter notebook: https://github.com/Penn000/NN/blob/master/notebook/LeNet/LeNet.ipynb
LeNet训练MNIST
import warnings
warnings.filterwarnings('ignore') # 不打印 warning
import tensorflow as tf
import numpy as np
import os
加载MNIST数据集
分别加载MNIST训练集、测试集、验证集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
X_train, y_train = mnist.train.images, mnist.train.labels
X_test, y_test = mnist.test.images, mnist.test.labels
X_validation, y_validation = mnist.validation.images, mnist.validation.labels
Extracting MNIST_data/train-images-idx3-ubyte.gz Extracting MNIST_data/train-labels-idx1-ubyte.gz Extracting MNIST_data/t10k-images-idx3-ubyte.gz Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
print("Image Shape: {}".format(X_train.shape))
print("label Shape: {}".format(y_train.shape))
print()
print("Training Set: {} samples".format(len(X_train)))
print("Validation Set: {} samples".format(len(X_validation)))
print("Test Set: {} samples".format(len(X_test)))
Image Shape: (55000, 784) label Shape: (55000, 10) Training Set: 55000 samples Validation Set: 5000 samples Test Set: 10000 samples
数据处理
由于LeNet的输入为32x32xC(C为图像通道数),而MNIST每张图像的尺寸为28x28,所以需要对图像四周进行填充,并添加一维,使得每幅图像的形状为32x32x1。
# 使用0对图像四周进行填充
X_train = np.array([np.pad(X_train[i].reshape((28, 28)), (2, 2), 'constant')[:, :, np.newaxis] for i in range(len(X_train))])
X_validation = np.array([np.pad(X_validation[i].reshape((28, 28)), (2, 2), 'constant')[:, :, np.newaxis] for i in range(len(X_validation))])
X_test = np.array([np.pad(X_test[i].reshape((28, 28)), (2, 2), 'constant')[:, :, np.newaxis] for i in range(len(X_test))])
print("Updated Image Shape: {}".format(X_train.shape))
Updated Image Shape: (55000, 32, 32, 1)
MNIST数据展示
import random import numpy as np import matplotlib.pyplot as plt %matplotlib inline index = random.randint(0, len(X_train)) image = X_train[index].squeeze().reshape((32, 32)) plt.figure(figsize=(2,2)) plt.imshow(image, cmap="gray") print(y_train[index])
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]

LeNet网络结构

Input
The LeNet architecture accepts a 32x32xC image as input, where C is the number of color channels. Since MNIST images are grayscale, C is 1 in this case. LeNet的输入为32x32xC的图像,C为图像的通道数。在MNIST中,图像为灰度图,因此C等于1。
Architecture
Layer 1: Convolutional. 输出为28x28x6的张量。
Activation. 激活函数。
Pooling. 输出为14x14x6的张量。
Layer 2: Convolutional. 输出为10x10x16的张量。
Activation. 激活函数。
Pooling. 输出为5x5x16的张量。
Flatten. 将张量展平为一维向量,使用tf.contrib.layers.flatten可以实现。
Layer 3: Fully Connected. 输出为120长度的向量。
Activation. 激活函数。
Layer 4: Fully Connected. 输出为84长度的向量。
Activation. 激活函数。
Layer 5: Fully Connected (Logits). 输出为10长度的向量。
# 卷积层
def conv_layer(x, filter_shape, stride, name):
with tf.variable_scope(name):
W = tf.get_variable('weights', shape=filter_shape, initializer=tf.truncated_normal_initializer())
b = tf.get_variable('biases', shape=filter_shape[-1], initializer=tf.zeros_initializer())
return tf.nn.conv2d(x, W, strides=stride, padding='VALID', name=name) + b
# 全连接层
def fc_layer(x, in_size, out_size, name):
with tf.variable_scope(name):
W = tf.get_variable('weights', shape=(in_size, out_size), initializer=tf.truncated_normal_initializer())
b = tf.get_variable('biases', shape=(out_size), initializer=tf.zeros_initializer())
return tf.nn.xw_plus_b(x, W, b, name=name)
def relu_layer(x, name):
return tf.nn.relu(x, name=name)
from tensorflow.contrib.layers import flatten
def LeNet(x):
conv1 = conv_layer(x, filter_shape=(5, 5, 1, 6), stride=[1, 1, 1, 1], name='conv1')
relu1 = relu_layer(conv1, 'relu1')
max_pool1 = max_pool_layer(relu1, kernel_size=[1, 2, 2, 1], stride=[1, 2, 2, 1], name='max_pool1')
conv2 = conv_layer(max_pool1, filter_shape=(5, 5, 6, 16), stride=[1, 1, 1, 1], name='conv2')
relu2 = relu_layer(conv2, 'relu2')
max_pool2 = max_pool_layer(relu2, kernel_size=[1, 2, 2, 1], stride=[1, 2, 2, 1], name='max_pool1')
flat = flatten(max_pool2)
fc3 = fc_layer(flat, 400, 120, name='fc3')
relu3 = relu_layer(fc3, 'relu3')
fc4 = fc_layer(relu3, 120, 84, name='fc4')
relu4 = relu_layer(fc4, 'relu4')
logits = fc_layer(relu4, 84, 10, name='fc5')
return logits
TensorFlow设置
EPOCHS = 10 BATCH_SIZE = 128 log_dir = './log/' x = tf.placeholder(tf.float32, (None, 32, 32, 1)) y = tf.placeholder(tf.int32, (None, 10)) # 定义损失函数 logits = LeNet(x) cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(cross_entropy) train = tf.train.AdamOptimizer(learning_rate=0.01).minimize(loss)
训练
from sklearn.utils import shuffle
import shutil
log_dir = './logs/'
if os.path.exists(log_dir):
shutil.rmtree(log_dir)
os.makedirs(log_dir)
train_writer = tf.summary.FileWriter(log_dir+'train/')
valid_writer = tf.summary.FileWriter(log_dir+'valid/')
ckpt_path = './ckpt/'
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
n_samples = len(X_train)
step = 0
for i in range(EPOCHS):
X_train, y_train = shuffle(X_train, y_train) # 打乱数据
# 使用mini-batch训练
for offset in range(0, n_samples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
sess.run(train, feed_dict={x: batch_x, y: batch_y})
train_loss = sess.run(loss, feed_dict={x: batch_x, y: batch_y})
train_summary = tf.Summary(value=[
tf.Summary.Value(tag="loss", simple_value=train_loss)
])
train_writer.add_summary(train_summary, step)
train_writer.flush()
step += 1
# 每个epoch使用验证集对网络进行验证
valid_loss = sess.run(loss, feed_dict={x: X_validation, y: y_validation})
valid_summary = tf.Summary(value=[
tf.Summary.Value(tag="loss", simple_value=valid_loss)
])
valid_writer.add_summary(valid_summary, step)
valid_writer.flush()
print('epoch', i, '>>> loss:', valid_loss)
# 保存模型
saver.save(sess, ckpt_path + 'model.ckpt')
print("Model saved")
epoch 0 >>> validation loss: 39.530758 epoch 1 >>> validation loss: 19.649899 epoch 2 >>> validation loss: 11.780323 epoch 3 >>> validation loss: 8.7316675 epoch 4 >>> validation loss: 6.396747 epoch 5 >>> validation loss: 5.4544454 epoch 6 >>> validation loss: 4.5326686 epoch 7 >>> validation loss: 3.5578024 epoch 8 >>> validation loss: 3.2353864 epoch 9 >>> validation loss: 3.5096574 Model saved
训练和验证的loss曲线
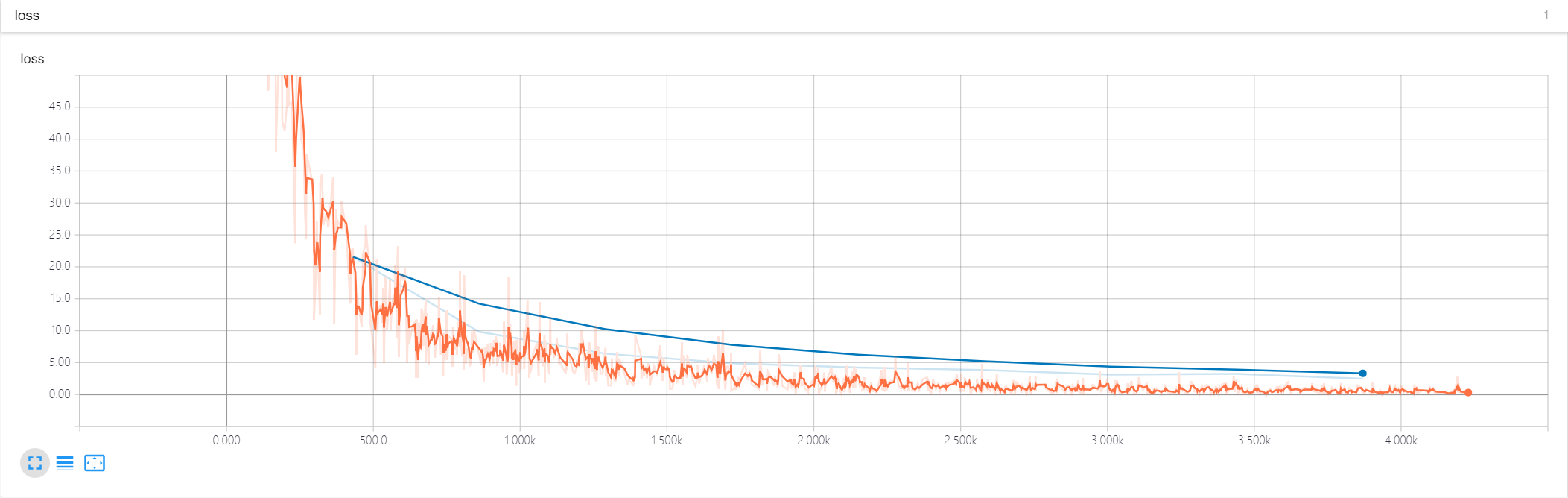
测试
correct = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('./ckpt'))
test_accuracy = sess.run(accuracy, feed_dict={x: X_test, y: y_test})
print("Test Accuracy = {}".format(test_accuracy))
INFO:tensorflow:Restoring parameters from ./ckpt/model.ckpt Test Accuracy = 0.9574000239372253
LeNet训练MNIST的更多相关文章
- Window10 上MindSpore(CPU)用LeNet网络训练MNIST
本文是在windows10上安装了CPU版本的Mindspore,并在mindspore的master分支基础上使用LeNet网络训练MNIST数据集,实践已训练成功,此文为记录过程中的出现问题: ( ...
- 使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始. 学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe 卷积神经网络原理参考:http://cs231 ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- CAFFE学习笔记(一)Caffe_Example之训练mnist
0.参考文献 [1]caffe官网<Training LeNet on MNIST with Caffe>; [2]薛开宇<读书笔记4学习搭建自己的网络MNIST在caffe上进行训 ...
- Caffe_Example之训练mnist
0.参考文献 [1]caffe官网<Training LeNet on MNIST with Caffe>; [2]薛开宇<读书笔记4学习搭建自己的网络MNIST在caffe上进行训 ...
- 【Caffe 测试】Training LeNet on MNIST with Caffe
Training LeNet on MNIST with Caffe We will assume that you have Caffe successfully compiled. If not, ...
- 2、TensorFlow训练MNIST
装载自:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html TensorFlow训练MNIST 这个教程的目标读者是对机器学习和T ...
- TensorFlow训练MNIST报错ResourceExhaustedError
title: TensorFlow训练MNIST报错ResourceExhaustedError date: 2018-04-01 12:35:44 categories: deep learning ...
- mxnet卷积神经网络训练MNIST数据集测试
mxnet框架下超全手写字体识别—从数据预处理到网络的训练—模型及日志的保存 import numpy as np import mxnet as mx import logging logging. ...
随机推荐
- 包建强的培训课程(1):Android App企业级开发
@import url(http://i.cnblogs.com/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/c ...
- kaldi 运行voxforge例子
---------------------------------------------------------------------------------------------------- ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- 干了这碗鸡汤:从理发店小弟到阿里P10技术大牛
1.引言 MIT TR 35(MIT Technology Review 35 Innovators Under 35)——“全球 35 位 35 岁以下科技创新青年”榜单,是全球最权威的青年科技创新 ...
- Numpy学习二:数组的索引与切片
1.一维数组索引与切片#创建一维数组arr1d = np.arange(10)print(arr1d) 结果:[0 1 2 3 4 5 6 7 8 9] #数组的索引从0开始,通过索引获取第三个元素a ...
- Kali学习笔记15:防火墙识别、负载均衡识别、WAF识别
防火墙简单的识别方式: 如图: 可以简单明了看出:发送SYN不回应,发送ACK回RST可以说明开启过滤等等 基于这个原理,我们可以写一个脚本来对防火墙来探测和识别: #!/usr/bin/python ...
- 应用监控CAT之cat-consumer源码阅读(二)
之前讲了 cat-client 进行cat埋点上报,那么上报给谁呢?以及后续故事如何?让我们来看看 cat-consumer 是如何接收处理的? 由cat-client发送数据,cat-consume ...
- 一条SQL语句在MySQL中如何执行的
本篇文章会分析一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的. 在分析之前我会先带着你看看 MySQL 的基础架构, ...
- [原创]K8uac bypassUAC(Win7/Wi8/Win10) 过46款杀软影响所有Windows版本
[原创]K8uac bypassUAC(Win7/Wi8/Win10) 过46款杀软影响所有Windows版本 工具: k8uac编译: VC++ 作者:K8哥哥发布: 2018/11/25 1:30 ...
- RabbitMQ集群简介
一个RabbitMQ消息代理是一个由一个或多个Erlang节点组成的逻辑组,其中的每个节点都共享users, virtual hosts, queues, exchanges, bindings, a ...