Go基础系列:Go实现工作池的两种方式
worker pool简介
worker pool其实就是线程池thread pool。对于go来说,直接使用的是goroutine而非线程,不过这里仍然以线程来解释线程池。
在线程池模型中,有2个队列一个池子:任务队列、已完成任务队列和线程池。其中已完成任务队列可能存在也可能不存在,依据实际需求而定。
只要有任务进来,就会放进任务队列中。只要线程执行完了一个任务,就将任务放进已完成任务队列,有时候还会将任务的处理结果也放进已完成队列中。
worker pool中包含了一堆的线程(worker,对go而言每个worker就是一个goroutine),这些线程嗷嗷待哺,等待着为它们分配任务,或者自己去任务队列中取任务。取得任务后更新任务队列,然后执行任务,并将执行完成的任务放进已完成队列。
下图来自wiki:
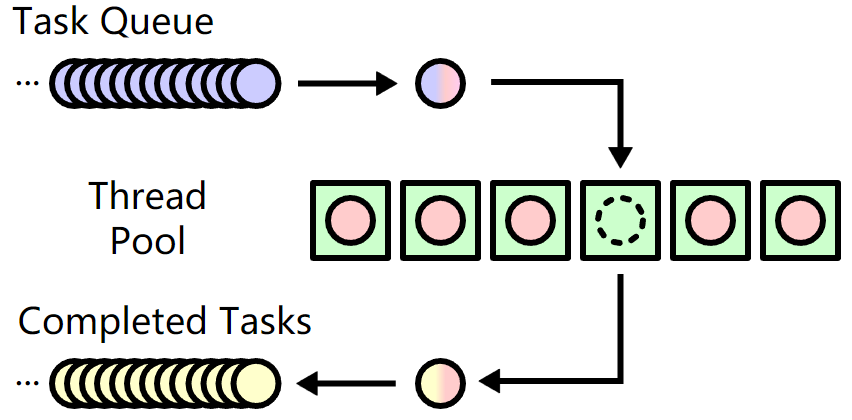
在Go中有两种方式可以实现工作池:传统的互斥锁、channel。
传统互斥锁机制的工作池
假设Go中的任务的定义形式为:
type Task struct {
...
}
每次有任务进来时,都将任务放在任务队列中。
使用传统的互斥锁方式实现,任务队列的定义结构大概如下:
type Queue struct{
M sync.Mutex
Tasks []Task
}
然后在执行任务的函数中加上Lock()和Unlock()。例如:
func Worker(queue *Queue) {
for {
// Lock()和Unlock()之间的是critical section
queue.M.Lock()
// 取出任务
task := queue.Tasks[0]
// 更新任务队列
queue.Tasks = queue.Tasks[1:]
queue.M.Unlock()
// 在此goroutine中执行任务
process(task)
}
}
假如在线程池中激活了100个goroutine来执行Worker()。Lock()和Unlock()保证了在同一时间点只能有一个goroutine取得任务并随之更新任务列表,取任务和更新任务队列都是critical section中的代码,它们是具有原子性。然后这个goroutine可以执行自己取得的任务。于此同时,其它goroutine可以争夺互斥锁,只要争抢到互斥锁,就可以取得任务并更新任务列表。当某个goroutine执行完process(task),它将因为for循环再次参与互斥锁的争抢。
上面只是给出了一点主要的代码段,要实现完整的线程池,还有很多额外的代码。
通过互斥锁,上面的一切操作都是线程安全的。但问题在于加锁/解锁的机制比较重量级,当worker(即goroutine)的数量足够多,锁机制的实现将出现瓶颈。
通过buffered channel实现工作池
在Go中,也能用buffered channel实现工作池。
示例代码很长,所以这里先拆分解释每一部分,最后给出完整的代码段。
在下面的示例中,每个worker的工作都是计算每个数值的位数相加之和。例如给定一个数值234,worker则计算2+3+4=9。这里交给worker的数值是随机生成的[0,999)范围内的数值。
这个示例有几个核心功能需要先解释,也是通过channel实现线程池的一般功能:
- 创建一个task buffered channel,并通过allocate()函数将生成的任务存放到task buffered channel中
- 创建一个goroutine pool,每个goroutine监听task buffered channel,并从中取出任务
- goroutine执行任务后,将结果写入到result buffered channel中
- 从result buffered channel中取出计算结果并输出
首先,创建Task和Result两个结构,并创建它们的通道:
type Task struct {
ID int
randnum int
}
type Result struct {
task Task
result int
}
var tasks = make(chan Task, 10)
var results = make(chan Result, 10)
这里,每个Task都有自己的ID,以及该任务将要被worker计算的随机数。每个Result都包含了worker的计算结果result以及这个结果对应的task,这样从Result中就可以取出任务信息以及计算结果。
另外,两个通道都是buffered channel,容量都是10。每个worker都会监听tasks通道,并取出其中的任务进行计算,然后将计算结果和任务自身放进results通道中。
然后是计算位数之和的函数process(),它将作为worker的工作任务之一。
func process(num int) int {
sum := 0
for num != 0 {
digit := num % 10
sum += digit
num /= 10
}
time.Sleep(2 * time.Second)
return sum
}
这个计算过程其实很简单,但随后还睡眠了2秒,用来假装执行一个计算任务是需要一点时间的。
然后是worker(),它监听tasks通道并取出任务进行计算,并将结果放进results通道。
func worker(wg *WaitGroup){
defer wg.Done()
for task := range tasks {
result := Result{task, process(task.randnum)}
results <- result
}
}
上面的代码很容易理解,只要tasks channel不关闭,就会一直监听该channel。需要注意的是,该函数使用指针类型的*WaitGroup作为参数,不能直接使用值类型的WaitGroup作为参数,这样会使得每个worker都有一个自己的WaitGroup。
然后是创建工作池的函数createWorkerPool(),它有一个数值参数,表示要创建多少个worker。
func createWorkerPool(numOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < numOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
创建工作池时,首先创建一个WaitGroup的值wg,这个wg被工作池中的所有goroutine共享,每创建一个goroutine都wg.Add(1)。创建完所有的goroutine后等待所有的groutine都执行完它们的任务,只要有一个任务还没有执行完,这个函数就会被Wait()阻塞。当所有任务都执行完成后,关闭results通道,因为没有结果再需要向该通道写了。
当然,这里是否需要关闭results通道,是由稍后的range迭代这个通道决定的,不关闭这个通道会一直阻塞range,最终导致死锁。
工作池部分已经完成了。现在需要使用allocate()函数分配任务:生成一大堆的随机数,然后将Task放进tasks通道。该函数有一个代表创建任务数量的数值参数:
func allocate(numOfTasks int) {
for i := 0; i < numOfTasks; i++ {
randnum := rand.Intn(999)
task := Task{i, randnum}
tasks <- task
}
close(tasks)
}
注意,最后需要关闭tasks通道,因为所有任务都分配完之后,没有任务再需要分配。当然,这里之所以需要关闭tasks通道,是因为worker()中使用了range迭代tasks通道,如果不关闭这个通道,worker将在取完所有任务后一直阻塞,最终导致死锁。
再接着的是取出results通道中的结果进行输出,函数名为getResult():
func getResult(done chan bool) {
for result := range results {
fmt.Printf("Task id %d, randnum %d , sum %d\n", result.task.id, result.task.randnum, result.result)
}
done <- true
}
getResult()中使用了一个done参数,这个参数是一个信号通道,用来表示results中的所有结果都取出来并处理完成了,这个通道不一定要用bool类型,任何类型皆可,它不用来传数据,仅用来返回可读,所以上面直接close(done)的效果也一样。通过下面的main()函数,就能理解done信号通道的作用。
最后还差main()函数:
func main() {
// 记录起始终止时间,用来测试完成所有任务耗费时长
startTime := time.Now()
numOfWorkers := 20
numOfTasks := 100
// 创建任务到任务队列中
go allocate(numOfTasks)
// 创建工作池
go createWorkerPool(numOfWorkers)
// 取得结果
var done = make(chan bool)
go getResult(done)
// 如果results中还有数据,将阻塞在此
// 直到发送了信号给done通道
<- done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}
上面分配了20个worker,这20个worker总共需要处理的任务数量为100。但注意,无论是tasks还是results通道,容量都是10,意味着任务队列最长只能是10个任务。
下面是完整的代码段:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Task struct {
id int
randnum int
}
type Result struct {
task Task
result int
}
var tasks = make(chan Task, 10)
var results = make(chan Result, 10)
func process(num int) int {
sum := 0
for num != 0 {
digit := num % 10
sum += digit
num /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
defer wg.Done()
for task := range tasks {
result := Result{task, process(task.randnum)}
results <- result
}
}
func createWorkerPool(numOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < numOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(numOfTasks int) {
for i := 0; i < numOfTasks; i++ {
randnum := rand.Intn(999)
task := Task{i, randnum}
tasks <- task
}
close(tasks)
}
func getResult(done chan bool) {
for result := range results {
fmt.Printf("Task id %d, randnum %d , sum %d\n", result.task.id, result.task.randnum, result.result)
}
done <- true
}
func main() {
startTime := time.Now()
numOfWorkers := 20
numOfTasks := 100
var done = make(chan bool)
go getResult(done)
go allocate(numOfTasks)
go createWorkerPool(numOfWorkers)
// 必须在allocate()和getResult()之后创建工作池
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}
执行结果:
Task id 19, randnum 914 , sum 14
Task id 9, randnum 150 , sum 6
Task id 15, randnum 215 , sum 8
............
Task id 97, randnum 315 , sum 9
Task id 99, randnum 641 , sum 11
total time taken 10.0174705 seconds
总共花费10秒。
可以试着将任务数量、worker数量修改修改,看看它们的性能比例情况。例如,将worker数量设置为99,将需要4秒,将worker数量设置为10,将需要20秒。
Go基础系列:Go实现工作池的两种方式的更多相关文章
- 网络协议 finally{ return问题 注入问题 jdbc注册驱动问题 PreparedStatement 连接池目的 1.2.1DBCP连接池 C3P0连接池 MYSQL两种方式进行实物管理 JDBC事务 DBUtils事务 ThreadLocal 事务特性 并发访问 隔离级别
1.1.1 API详解:注册驱动 DriverManager.registerDriver(new com.mysql.jdbc.Driver());不建议使用 原因有2个: >导致驱动被注册2 ...
- Android 应用开发 之通过AsyncTask与ThreadPool(线程池)两种方式异步加载大量数据的分析与对比--转载
在加载大量数据的时候,经常会用到异步加载,所谓异步加载,就是把耗时的工作放到子线程里执行,当数据加载完毕的时候再到主线程进行UI刷新.在数据量非常大的情况下,我们通常会使用两种技术来进行异步加载,一 ...
- 配置Java连接池的两种方式:tomcat方式以及spring方式
1. tomcat方式:在context.xml配置连接池,然后在web.xml中写配置代码(也能够在server.xml文件里配置连接池).这两种方法的差别是:在tomcat6版本号及以上中cont ...
- JDBC 连接池的两种方式——dbcp & c3p0
申明:本文对于连接资源关闭采用自定义的 JDBCUtils 工具: package com.test.utils; import java.sql.Connection; import java.sq ...
- [算法基础]斐波那契(recursion+loop)两种方式执行时间对比
一.斐波那契数列求第n项两种方式 1.递归(自上而下)def recur_fibonacci(n): if n <= 0: return 0 if n == 1: return 1 return ...
- 万恶技术系列笔记-jupyter工作路径和源文件打开方式
万恶技术系列笔记-jupyter工作路径和源文件打开方式 脚本文件,ipynb的正确打开姿势: ipynb不能直接打开,需要复制到工作路径.例如 10_monkeys_model_1.ipynb ...
- SpringCloud系列-整合Hystrix的两种方式
Hystrix [hɪst'rɪks],中文含义是豪猪,因其背上长满棘刺,从而拥有了自我保护的能力.本文所说的Hystrix是Netflix开源的一款容错框架,同样具有自我保护能力. 本文目录 一.H ...
- 【Xamarin 挖墙脚系列:IOS 开发界面的3种方式】
原文:[Xamarin 挖墙脚系列:IOS 开发界面的3种方式] xcode6进行三种基本的界面布局的方法,分别是手写UI,xib和storyboard.手写UI是最早进行UI界面布局的方法,优点是灵 ...
- 基础知识:编程语言介绍、Python介绍、Python解释器安装、运行Python解释器的两种方式、变量、数据类型基本使用
2018年3月19日 今日学习内容: 1.编程语言的介绍 2.Python介绍 3.安装Python解释器(多版本共存) 4.运行Python解释器程序两种方式.(交互式与命令行式)(♥♥♥♥♥) 5 ...
随机推荐
- java中的接口与继承,接口的例子讲解
extends 继承类:implements 实现接口. 简单说: 1.extends是继承父类,只要那个类不是声明为final或者那个类定义为abstract的就能继承, 2.JAVA中不支持多重继 ...
- JS prototype chaining(原型链)整理中······
初学原型链整理 构造器(constructor).原型(prototype).实例(instance); 每一个构造器都有一个prototype对象,这个prototype对象有一个指针指向该构造器: ...
- Geomystery现已上架!
欢迎体验由王涵.程立智.郑昊.蔡镇泽.李明伦.温志成同学开发的几何解谜游戏Geomystery,现已上架Microsoft官方商城! https://www.microsoft.com/zh-cn/s ...
- Runtime "Apache Tomcat v6.0 (3)" is invalid. The JRE could not be found. Edit the server and change the JRE location解决方案
使用eclipse,启动Tomcat时出现The JRE could not be found ,Edit server and change teh JRE location的错误提示! 原因:重装 ...
- 从今天开始慢慢阅读java9源码决心的声明。
我从很早的时候就好奇java的源码了,因为有使用者就有制作者. 在校期间使用了java两年多的我却不知道java里面的任何东西. 这个寒假前我无意之间看到了java9出现的新闻,网上查询到原来源码就隐 ...
- android 界面设计
wm = (WindowManager) getSystemService(Context.WINDOW_SERVICE); DisplayMetrics dm = new DisplayMetric ...
- java获取当前日期的前一天和后一天
/** * 获得指定日期的前一天 * @param specifiedDay * @return * @throws Exception */ public static String getSpec ...
- 吴恩达机器学习笔记44-核函数(Kernels)
回顾我们之前讨论过可以使用高级数的多项式模型来解决无法用直线进行分隔的分类问题: 为了获得上图所示的判定边界,我们的模型可能是
- kafka扫盲笔记,实战入门
Kafka作为大数据时代的产物,自有其生存之道.让我们跟随扫盲班的培训,进行大致了解与使用kafka吧.(平时工作有使用不代表就知道kafka了哟) 1. kafka介绍 1.1. 拥有的能力(能干什 ...
- 应用监控CAT之cat-client源码阅读(一)
CAT 由大众点评开发的,基于 Java 的实时应用监控平台,包括实时应用监控,业务监控.对于及时发现线上问题非常有用.(不知道大家有没有在用) 应用自然是最初级的,用完之后,还想了解下其背后的原理, ...