Synchronized 和 Lock 锁在JVM中的实现原理以及代码解析
正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
一、深入JVM锁机制:synchronized
synrhronized关键字简洁、清晰、语义明确,因此即使有了Lock接口,使用的还是非常广泛。其应用层的语义是可以把任何一个非null对象作为"锁",当synchronized作用在方法上时,锁住的便是对象实例(this);当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁;当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。在HotSpot JVM实现中,锁有个专门的名字:对象监视器。
1.1 线程状态及状态转换
当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程:
◆ Contention List:所有请求锁的线程将被首先放置到该竞争队列。
◆ Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List。
◆ Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set。
◆ OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck,可以理解为Ready线程
◆ Owner:获得锁的线程称为Owner。
◆ !Owner:释放锁的线程。
下图反映了个状态转换关系:
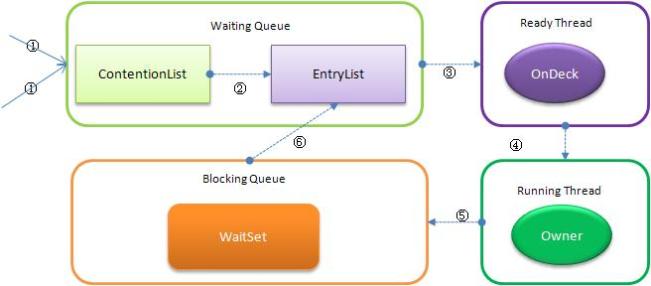
新请求锁的线程将首先被加入到ConetentionList中,当某个拥有锁的线程(Owner状态)调用unlock之后,如果发现EntryList为空则从ContentionList中移动线程到EntryList,下面说明下ContentionList和EntryList的实现方式:
1.2ContentionList虚拟队列
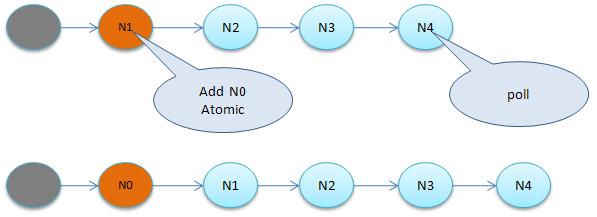
ContentionList并不是一个真正的Queue,而只是一个虚拟队列,原因在于ContentionList是由Node及其next指针逻辑构成,并不存在一个Queue的数据结构。ContentionList是一个后进先出(LIFO)的队列,每次新加Node时都会在队头进行,通过CAS改变第一个节点的的指针为新增节点,同时设置新增节点的next指向后续节点,而取得操作则发生在队尾。
显然,该结构其实是个Lock-Free的队列。
因为只有Owner线程才能从队尾取元素(Owner线程在unlock时会从ContentionList中迁移线程到EntryList),也即线程出列操作无争用,当然也就避免了CAS的ABA问题。
1.3 EntryList
EntryList与ContentionList逻辑上同属等待队列,ContentionList会被线程并发访问,为了降低对ContentionList队尾的争用,而建立EntryList。Owner线程在unlock时会从ContentionList中迁移线程到EntryList,并会指定EntryList中的某个线程(一般为Head)为Ready(OnDeck)线程。Owner线程并不是把锁传递给OnDeck线程,只是把竞争锁的权利交给OnDeck,OnDeck线程需要重新竞争锁。这样做虽然牺牲了一定的公平性,但极大的提高了整体吞吐量,在Hotspot中把OnDeck的选择行为称之为“竞争切换”。
OnDeck线程获得锁后即变为owner线程,无法获得锁则会依然留在EntryList中,考虑到公平性,在EntryList中的位置不发生变化(依然在队头)。如果Owner线程被wait方法阻塞,则转移到WaitSet队列;如果在某个时刻被notify/notifyAll唤醒,则再次转移到EntryList。
1.4 自旋锁
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数);线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能。这个地方正式与Lock的区别所在,Lock的阻塞操作是自己在队列中使用LockSupport中的park方法进行阻塞。
缓解上述问题的办法便是自旋,其原理是:当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在Owner线程释放锁后,争用线程可能会立即得到锁,从而避免了系统阻塞。但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择,如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。
对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略,具体如下:
◆ 如果平均负载小于CPUs则一直自旋。
◆ 如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞。
◆ 如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞。
◆ 如果CPU处于节电模式则停止自旋。
◆ 自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差)。
◆ 自旋时会适当放弃线程优先级之间的差异。
那synchronized实现何时使用了自旋锁?答案是在线程进入ContentionList时,也即第一步操作前。线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。还有一个不公平的地方是自旋线程可能会抢占了Ready线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
1.5. 偏向锁
在JVM1.6中引入了偏向锁,偏向锁主要解决无竞争下的锁性能问题,首先我们看下无竞争下锁存在什么问题:
现在几乎所有的锁都是可重入的,也即已经获得锁的线程可以多次锁住/解锁监视对象,按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS操作),CAS操作会延迟本地调用,因此偏向锁的想法是一旦线程第一次获得了监视对象,之后让监视对象“偏向”这个线程,之后的多次调用则可以避免CAS操作,说白了就是置个变量,如果发现为true则无需再走各种加锁/解锁流程。但还有很多概念需要解释、很多引入的问题需要解决。
1.5.1 CAS及SMP架构
CAS为什么会引入本地延迟?这要从SMP(对称多处理器)架构说起,下图大概表明了SMP的结构:
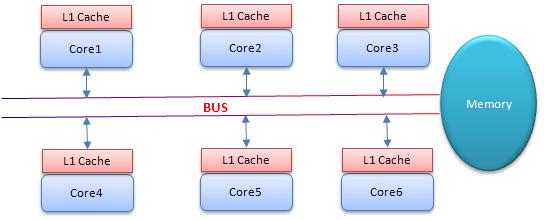
其意思是所有的CPU会共享一条系统总线(BUS),靠此总线连接主存。每个核都有自己的一级缓存,各核相对于BUS对称分布,因此这种结构称为“对称多处理器”。
而CAS的全称为Compare-And-Swap,是一条CPU的原子指令,其作用是让CPU比较后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM只是封装了汇编调用,那些AtomicInteger类便是使用了这些封装后的接口。
Core1和Core2可能会同时把主存中某个位置的值Load到自己的L1 Cache中,当Core1在自己的L1 Cache中修改这个位置的值时,会通过总线,使Core2中L1 Cache对应的值“失效”,而Core2一旦发现自己L1 Cache中的值失效(称为Cache命中缺失)则会通过总线从内存中加载该地址最新的值,大家通过总线的来回通信称为“Cache一致性流量”,因为总线被设计为固定的“通信能力”,如果Cache一致性流量过大,总线将成为瓶颈。而当Core1和Core2中的值再次一致时,称为“Cache一致性”,从这个层面来说,锁设计的终极目标便是减少Cache一致性流量。
而CAS恰好会导致Cache一致性流量,如果有很多线程都共享同一个对象,当某个Core CAS成功时必然会引起总线风暴,这就是所谓的本地延迟,本质上偏向锁就是为了消除CAS,降低Cache一致性流量。
1.5.2 Cache一致性:
上面提到Cache一致性,其实是有协议支持的,现在通用的协议是MESI(最早由Intel开始支持),具体参考:http://en.wikipedia.org/wiki/MESI_protocol,以后会仔细讲解这部分。
1.5.3 Cache一致性流量的例外情况:
其实也不是所有的CAS都会导致总线风暴,这跟Cache一致性协议有关,具体参考:http://blogs.oracle.com/dave/entry/biased_locking_in_hotspot
NUMA(Non Uniform Memory Access Achitecture)架构:
与SMP对应还有非对称多处理器架构,现在主要应用在一些高端处理器上,主要特点是没有总线,没有公用主存,每个Core有自己的内存,针对这种结构此处不做讨论。
1.5.4 偏向解除
偏向锁引入的一个重要问题是,在多争用的场景下,如果另外一个线程争用偏向对象,拥有者需要释放偏向锁,而释放的过程会带来一些性能开销,但总体说来偏向锁带来的好处还是大于CAS代价的。
1.6. 总结
关于锁,JVM中还引入了一些其他技术比如锁膨胀等,这些与自旋锁、偏向锁相比影响不是很大,这里就不做介绍。
通过上面的介绍可以看出,synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。
2、深入JVM锁机制:Lock
1. ReentrantLock的调用过程
AbstractQueuedSynchronizer
|---Sync
|---NonfairSync
|---NonfairSync
经过观察ReentrantLock把所有Lock接口的操作都委派到一个Sync类上,该类继承了AbstractQueuedSynchronizer:
- static abstract class Sync extends AbstractQueuedSynchronizer
Sync又有两个子类:
- final static class NonfairSync extends Sync
- final static class FairSync extends Sync
显然是为了支持公平锁和非公平锁而定义,默认情况下为非公平锁。
先理一下Reentrant.lock()方法的调用过程(默认非公平锁):
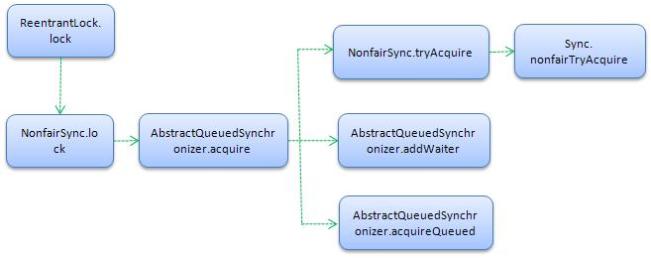
这些讨厌的Template模式导致很难直观的看到整个调用过程,其实通过上面调用过程及AbstractQueuedSynchronizer的注释可以发现,AbstractQueuedSynchronizer中抽象了绝大多数Lock的功能,而只把tryAcquire方法延迟到子类中实现。tryAcquire方法的语义在于用具体子类判断请求线程是否可以获得锁,无论成功与否AbstractQueuedSynchronizer都将处理后面的流程。
2. 锁实现(加锁)
简单说来,AbstractQueuedSynchronizer会把所有的请求线程构成一个CLH队列,当一个线程执行完毕(lock.unlock())时会激活自己的后继节点,但正在执行的线程并不在队列中,而那些等待执行的线程全部处于阻塞状态,经过调查线程的显式阻塞是通过调用LockSupport.park()完成,而LockSupport.park()则调用sun.misc.Unsafe.park()本地方法,再进一步,HotSpot在Linux中中通过调用pthread_mutex_lock函数把线程交给系统内核进行阻塞。
该队列如图:
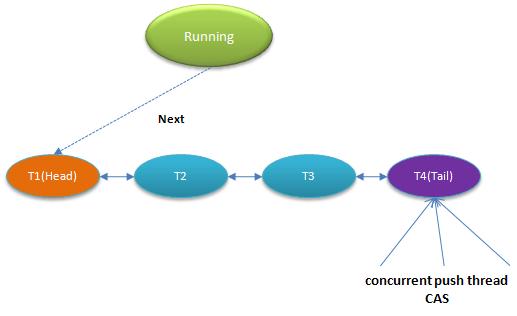
与synchronized相同的是,这也是一个虚拟队列,不存在队列实例,仅存在节点之间的前后关系。
令人疑惑的是为什么采用CLH队列呢?原生的CLH队列是用于自旋锁,但Doug Lea把其改造为阻塞锁。
当有线程竞争锁时,该线程会首先尝试获得锁,这对于那些已经在队列中排队的线程来说显得不公平,这也是非公平锁的由来,与synchronized实现类似,这样会极大提高吞吐量。
如果已经存在Running线程,则新的竞争线程会被追加到队尾,具体是采用基于CAS的Lock-Free算法,因为线程并发对Tail调用CAS可能会导致其他线程CAS失败,解决办法是 循环CAS[在 AtomicXXX中 也是使用这种循环CAS操作] 直至成功。AbstractQueuedSynchronizer的实现非常精巧,令人叹为观止,不入细节难以完全领会其精髓,下面详细说明实现过程:
2.1 Sync.nonfairTryAcquire
nonfairTryAcquire方法将是lock方法间接调用的第一个方法,每次请求锁时都会首先调用该方法。
final boolean nonfairTryAcquire(int acquires) { //acquires=1
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) { //发现没有线程占用锁
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { //发现当前占用锁的是自己 则对应的计数器加1 修改对应的state 这里体现了偏向锁
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
该方法会首先判断当前状态,如果c==0说明没有线程正在竞争该锁,如果不c !=0 说明有线程正拥有了该锁。
如果发现c==0,则通过CAS设置该状态值为acquires,acquires的初始调用值为1,每次线程重入该锁都会+1,每次unlock都会-1,但为0时释放锁。如果CAS设置成功,则可以预计其他任何线程调用CAS都不会再成功,也就认为当前线程得到了该锁,也作为Running线程,很显然这个Running线程并未进入等待队列。
如果c !=0 但发现自己已经拥有锁,只是简单地++acquires,并修改status值,但因为没有竞争,所以通过setStatus修改,而非CAS,也就是说这段代码实现了偏向锁的功能,并且实现的非常漂亮。
2.2 AbstractQueuedSynchronizer.addWaiter
addWaiter方法负责把当前无法获得锁的线程包装为一个Node添加到队尾:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
- 如果当前队尾已经存在(tail!=null),则使用CAS把当前线程更新为Tail。
- 如果当前Tail为null或则线程调用CAS设置队尾失败,则通过enq方法继续设置Tail。
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
Node h = new Node(); // Dummy header
h.next = node;
node.prev = h;
if (compareAndSetHead(h)) {
tail = node;
return h;
}
}
else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
该方法就是循环调用CAS,即使有高并发的场景,无限循环将会最终成功把当前线程追加到队尾(或设置队头)。总而言之,addWaiter的目的就是通过CAS把当前现在追加到队尾,并返回包装后的Node实例。
把线程要包装为Node对象的主要原因,除了用Node构造供虚拟队列外,还用Node包装了各种线程状态,这些状态被精心设计为一些数字值:
◆ SIGNAL(-1) :线程的后继线程正/已被阻塞,当该线程release或cancel时要重新这个后继线程(unpark)。
◆ CANCELLED(1):因为超时或中断,该线程已经被取消。
◆ CONDITION(-2):表明该线程被处于条件队列,就是因为调用了Condition.await而被阻塞。
◆ PROPAGATE(-3):传播共享锁。
◆ 0:0代表无状态。
2.3 AbstractQueuedSynchronizer.acquireQueued
acquireQueued的主要作用是把已经追加到队列的线程节点 (addWaiter方法返回值)进行阻塞,但阻塞前又通过tryAccquire重试是否能获得锁,如果重试成功能则无需阻塞,直接返回
final boolean acquireQueued(final Node node, int arg) {
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { //
setHead(node);
p.next = null; // help GC
return interrupted; // if执行满足 也就是 头队列的线程获得了锁 则执行 if 中的 内容 renturn 退出整个的 for 循环
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) //在此阻塞
interrupted = true;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
}
仔细看看这个方法是个无限循环,感觉如果p == head && tryAcquire(arg)条件不满足循环将永远无法结束,当然不会出现死循环,奥秘在于第12行的parkAndCheckInterrupt会把当前线程挂起,从而阻塞住线程的调用栈。
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
如前面所述,LockSupport.park最终把线程交给系统(Linux)内核进行阻塞。当然也不是马上把请求不到锁的线程进行阻塞,还要检查该线程的状态,比如如果该线程处于Cancel状态则没有必要,具体的检查在shouldParkAfterFailedAcquire中:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
检查原则在于:
◆ 规则1:如果前继的节点状态为SIGNAL,表明当前节点需要unpark,则返回成功,此时acquireQueued方法的第12行(parkAndCheckInterrupt)将导致线程阻塞。
◆ 规则2:如果前继节点状态为CANCELLED(ws>0),说明前置节点已经被放弃,则回溯到一个非取消的前继节点,返回false,acquireQueued方法的无限循环将递归调用该方法,直至规则1返回true,导致线程阻塞。
◆ 规则3:如果前继节点状态为非SIGNAL、非CANCELLED,则设置前继的状态为SIGNAL,返回false后进入acquireQueued的无限循环,与规则2同。
总体看来,shouldParkAfterFailedAcquire就是靠前继节点判断当前线程是否应该被阻塞,如果前继节点处于CANCELLED状态,则顺便删除这些节点重新构造队列。
至此,锁住线程的逻辑已经完成,下面讨论解锁的过程。
3. 解 锁
请求锁不成功的线程会被挂起在acquireQueued方法的第12行,12行以后的代码必须等线程被解锁锁才能执行,假如被阻塞的线程得到解锁,则执行第13行,即设置interrupted = true,之后又进入无限循环。
从无限循环的代码可以看出,并不是得到解锁的线程一定能获得锁,必须在第6行中调用tryAccquire重新竞争,因为锁是非公平的,有可能被新加入的线程获得,从而导致刚被唤醒的线程再次被阻塞,这个细节充分体现了“非公平”的精髓。通过之后将要介绍的解锁机制会看到,第一个被解锁的线程就是Head,因此p == head的判断基本都会成功。
至此可以看到,把tryAcquire方法延迟到子类中实现的做法非常精妙并具有极强的可扩展性,令人叹为观止!当然精妙的不是这个Templae设计模式,而是Doug Lea对锁结构的精心布局。
解锁代码相对简单,主要体现在AbstractQueuedSynchronizer.release和Sync.tryRelease方法中:
class AbstractQueuedSynchronizer
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
class Sync
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
tryRelease与tryAcquire语义相同,把如何释放的逻辑延迟到子类中。tryRelease语义很明确:如果线程多次锁定,则进行多次释放,直至status==0则真正释放锁,所谓释放锁即设置status为0,因为无竞争所以没有使用CAS。
release的语义在于:如果可以释放锁,则唤醒队列第一个线程(Head),具体唤醒代码如下:
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
这段代码的意思在于找出第一个可以unpark的线程,一般说来head.next == head,Head就是第一个线程,但Head.next可能被取消或被置为null,因此比较稳妥的办法是从后往前找第一个可用线程。貌似回溯会导致性能降低,其实这个发生的几率很小,所以不会有性能影响。之后便是通知系统内核继续该线程,在Linux下是通过pthread_mutex_unlock完成。之后,被解锁的线程进入上面所说的重新竞争状态。
4. Lock VS Synchronized
AbstractQueuedSynchronizer通过构造一个基于阻塞的CLH队列容纳所有的阻塞线程,而对该队列的操作均通过Lock-Free(CAS)操作,但对已经获得锁的线程而言,ReentrantLock实现了偏向锁的功能。
synchronized的底层也是一个基于CAS操作的等待队列,但JVM实现的更精细,把等待队列分为ContentionList和EntryList,目的是为了降低线程的出列速度;当然也实现了偏向锁,从数据结构来说二者设计没有本质区别。但synchronized还实现了自旋锁,并针对不同的系统和硬件体系进行了优化,而Lock则完全依靠系统阻塞挂起等待线程。
当然Lock比synchronized更适合在应用层扩展,可以继承AbstractQueuedSynchronizer定义各种实现,比如实现读写锁(ReadWriteLock),公平或不公平锁;同时,Lock对应的Condition也比wait/notify要方便的多、灵活的多。
Synchronized 和 Lock 锁在JVM中的实现原理以及代码解析的更多相关文章
- Python中sort和sorted函数代码解析
Python中sort和sorted函数代码解析 本文研究的主要是Python中sort和sorted函数的相关内容,具体如下. 一.sort函数 sort函数是序列的内部函数 函数原型: L.sor ...
- java多线程 synchronized 与lock锁 实现线程安全
如果有多个线程在同时运行,而这些线程可能会同时运行这段代码.程序每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的. 通过卖火车票的例子 火车站要卖票,我们模 ...
- synchronized 与 lock锁的异同
相同点: 二者都可以解决线程安全问题: 不同点: 1..Synchronized 是Java内置的关键字:Lock是一个Java类: 2.Synchronized 无法判断锁的状态:Lock可以判断是 ...
- 不使用synchronized和lock 锁实现线程安全单例
单例实现方式一,锁机制 public class Singleton { private static Singleton singleton=null; public Singleton() { } ...
- JVM中OutOFMemory和StackOverflowError异常代码
1.Out of Memory 异常 右键Run As --->Run Configuration 设置JVM参数 -Xms20m -Xmx20m 上代码: /** * VM Args:-Xms ...
- 转:synchronized和LOCK的实现原理---深入JVM锁机制
JVM底层又是如何实现synchronized的? 目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug ...
- JAVA中synchronized和lock详解
目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea.本文并不比较synchronize ...
- synchronized与static synchronized 的差别、synchronized在JVM底层的实现原理及Java多线程锁理解
本Blog分为例如以下部分: 第一部分:synchronized与static synchronized 的差别 第二部分:JVM底层又是怎样实现synchronized的 第三部分:Java多线程锁 ...
- 为什么Java有了synchronized之后还造了Lock锁这个轮子?
众所周知,synchronized和Lock锁是java并发变成中两大利器,可以用来解决线程安全的问题.但是为什么Java有了synchronized之后还是提供了Lock接口这个api,难道仅仅只是 ...
随机推荐
- 解决Java中There is no getter for property XXX'XXX' in 'class XXX'的问题
当你出现There is no getter for property XXX'XXX' in 'class XXX'时, 就是在你的这个类中没有找到你这个属性. 检查两个地方 1.你的返回值类型是否 ...
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- 安卓视频播放器(VideoView)
VideoView是安卓自带的视频播放器类,该类集成有显示和控制两大部分,在布局文件中添加VideoView然后在java文件中简单的调用控制命令,即可实现本地或者网络视频的播放.本章实现视频的居中播 ...
- stc15f104w模拟串口使用
stc15f104w单片机体积小,全8个引脚完全够一般的控制使用,最小系统也就是个电路滤波----加上一个47uf电容和一个103电容即可,但因为其是一个5V单片机,供电需要使用5V左右电源. 该款单 ...
- 插头dp初探
问题描述 插头dp用于解决一类可基于图连通性递推的问题.用插头来表示轮廓线上的连通性,然后根据连通性与下一位结合讨论进行转移. 表示连通性的方法 与字符串循环最小表示不同,这种方法用于给轮廓线上的联通 ...
- python之获取当前操作系统(平台)
Python在不同环境平台使用时,需要判断当前是什么系统,比如常用的windows,linux等 下面介绍一些能够获取当前系统的命令 1.使用sys.platform获取 #!/usr/bin/env ...
- HDU 1006 Digital Roots
Problem Description The digital root of a positive integer is found by summing the digits of the int ...
- Jenkins可用环境变量以及使用方法
Jenkins可用环境变量以及使用方法
- 西安活动 | 9月15号 "拥抱开源, 又见.NET" 线下交流活动
随着.NET Core的发布和开源,.NET又重新回到了人们的视野.除了开源.跨平台.高性能以及优秀的语言特性,越来越多的第三方开源库也出现在了github上——包括ML.NET机器学习.Xamari ...
- Java并发编程-再谈 AbstractQueuedSynchronizer 1 :独占模式
关于AbstractQueuedSynchronizer JDK1.5之后引入了并发包java.util.concurrent,大大提高了Java程序的并发性能.关于java.util.concurr ...