正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1α||w||1即为L1正则化项。
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量ww中各个元素的绝对值之和,通常表示为||w||1||w||1
- L2正则化是指权值向量ww中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2||w||2
一般都会在正则化项之前添加一个系数,Python中用αα表示,一些文章也用λλ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
L1和L2正则化的直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:
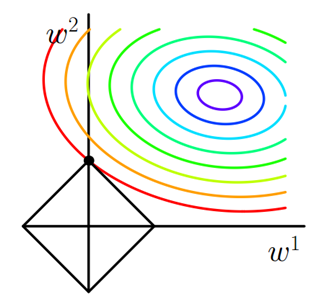
J=J0+α∑w|w|(1)(1)J=J0+α∑w|w|其中J0J0是原始的损失函数,加号后面的一项是L1正则化项,αα是正则化系数。注意到L1正则化是权值的绝对值之和,JJ是带有绝对值符号的函数,因此JJ是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0J0后添加L1正则化项时,相当于对J0J0做了一个约束。令L=α∑w|w|L=α∑w|w|,则J=J0+LJ=J0+L,此时我们的任务变成在LL约束下求出J0J0取最小值的解。考虑二维的情况,即只有两个权值w1w1和w2w2,此时L=|w1|+|w2|L=|w1|+|w2|对于梯度下降法,求解J0J0的过程可以画出等值线,同时L1正则化的函数LL也可以在w1w2w1w2的二维平面上画出来。如下图:
图1 L1正则化图中等值线是J0J0的等值线,黑色方形是LL函数的图形。在图中,当J0J0等值线与LL图形首次相交的地方就是最优解。上图中J0J0与LL在LL的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)(w1,w2)=(0,w)。可以直观想象,因为LL函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0J0与这些角接触的机率会远大于与LL其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数αα,可以控制LL图形的大小。αα越小,LL的图形越大(上图中的黑色方框);αα越大,LL的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)(w1,w2)=(0,w)中的ww可以取到很小的值。
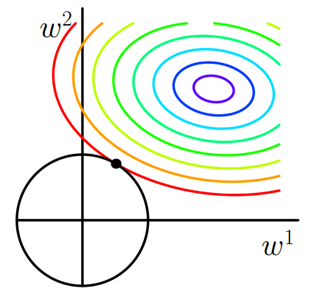
类似,假设有如下带L2正则化的损失函数:
J=J0+α∑ww2(2)(2)J=J0+α∑ww2同样可以画出他们在二维平面上的图形,如下:
图2 L2正则化二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0J0与LL相交时使得w1w1或w2w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θθ,hθ(x)hθ(x)是我们的假设函数,那么线性回归的代价函数如下:
J(θ)=12m∑i=1m(hθ(x(i))−y(i))2(3)(3)J(θ)=12m∑i=1m(hθ(x(i))−y(i))2那么在梯度下降法中,最终用于迭代计算参数θθ的迭代式为:
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))x(i)j(4)(4)θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))xj(i)其中αα是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:
θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)j(5)(5)θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))xj(i)其中λλ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θjθj都要先乘以一个小于1的因子,从而使得θjθj不断减小,因此总得来看,θθ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
- 原文出处:https://blog.csdn.net/jinping_shi/article/details/52433975
- 感谢该文作者,本文主要留档后期复习归纳总结(非原创)
正则化 L1 L2的更多相关文章
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
随机推荐
- jira和svn关联后,不显示Subversion Commits标签或不显示svn提交信息
1.jira的版本是7.3.6 2.不显示Subversion Commits标签或不显示svn提交信息 其实是权限的分配问题 3.管理员登录 找到对应项目的权限管理 4.[评论权限]——[编辑所有评 ...
- 使用MiniProfiler检测页面性能
1.引入nuget包 PM> Install-Package MiniProfiler 2.配置界面 @using StackExchange.Profiling; <head> . ...
- shiro 和 跨域过滤器冲突
在web.xml 中 cros要写在shiro 的配置前面,如下,不然会先过shiro 过滤器就产生跨域问题, 参考web.xml 的过滤器加载顺序 <!-- 跨域请求 --> <f ...
- 添加日志(配置spring)---Java_web
一.配置日志--以下三部 1.配置web.xml; 2.配置 log4j.properties; 3.配置jar包 以下是文件目录 二.配置 web.xml (注意:下面的classpath即lo ...
- MSSQL无法启动-原来电脑登录密码改了,重启后要设置
Sql Server (MSSQLSERVER) 服务无法启动 - 晓菜鸟 - 博客园 http://www.cnblogs.com/52XF/p/4230578.html --摘抄如下: 一.是 ...
- nova 命令管理虚拟机
nova命令管理虚拟机: $ nova list #查看虚拟机$ nova stop [vm-name]或[vm-id] #关闭虚拟机$ nova start [vm-name]或[vm-id] #启 ...
- Linux就该这么学(3)-管道符、重定向与环境变量(学习笔记)
1.Linux命令与文件读写操作有关的重定向技术: 学习目标:主要解决输出信息的保存问题. 标准覆盖输出重定向: 标准追加输出重定向 错误覆盖输出重定向 错误追加输出重定向 输入重定向 标准输入(ST ...
- Python3-lamba表达式、zip函数
lambda表达式 学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即: # 普通条件语句 == : name = 'wupeiqi' else: name = 'alex' ...
- 空串、null串和isEmpty方法
空串 空串""是长度为0的字符串.可以调用以下代码检查字符串是否为空: if(str.length() == 0) 或 if(str.equals("")) 空 ...
- 利用URLConnection http协议实现webservice接口功能(附HttpUtil.java)
URL的openConnection()方法将返回一个URLConnection对象,该对象表示应用程序和 URL 之间的通信链接.程序可以通过URLConnection实例向该URL发送请求.读取U ...