ELK使用3-Logstash
一、命令行输入输出操作
1、命令行输出:
/application/elk/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }'
说明:
a、stdin{}[标准输入]
b、stdout{}[标准输出]
2、以json格式展示,在logstash中等号用 => 表示
/application/elk/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug} }'
3、输出到es
a、要使用按照自定义方式根据当前时间生成索引的方式来输入到es必须开启 manage_template => true此参数,如使用logstash默认的logstash-%{+YYYY.MM.dd} 则可以不用打开此参数,这个问题困扰了一下午。
/application/elk/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.30.41:9200"] index => "wohaoshuai-%{+YYYY.MM.dd}"} manage_template => true}'
如果不使用manage_template => true参数会报错如下:
[406] {"error":"Content-Type header [text/plain; charset=ISO-8859-1] is not supported","status":406} {:class=>"Elasticsearch::Transport::Transport::Errors::NotAcceptable", :level=>:error}
b、如果只是自己命名的index则不需要添加manage_template参数。
/application/elk/logstash/bin/logstash -e 'input { stdin{ } } output { elasticsearch { hosts => ["192.168.30.41:9200"] index => "wohaoshuaitest"} }'
4、既输出到es又输出到屏幕:
/application/elk/logstash/bin/logstash -e 'input { stdin{ } } output { stdout { codec => rubydebug } elasticsearch { hosts => ["192.168.30.41:9200"] index => "wohaoshuaitest"} }'
5、要删除后重新生成index收集需要删除相应的记录
rm -rf /application/elk/logstash/data/plugins/inputs/file/.sincedb_*
6、nginx日志格式设置:
log_format access_log_json '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sent":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';
7、filter
a、grok:对我们收进来的事件进行过滤。
利用正则表达式进行匹配进行字段的拆分,因此grok提供了一下预定义的正则表达式,logstash 5.6.1相应的文件在路径 /application/elk/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns下
简单的grok案例:
下面匹配的内容为:55.3.244.1 GET /index.html 15824 0.043
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" } #这一行的意思是,将消息按照logstash提供的正则字段匹配,然后将匹配的内容的字段命名为冒号后面自定义的名字
}
}
b、收集http日志,使用软件自定义的阿帕奇系统日志正则就可以,文件在/application/elk/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/httpd中
如图
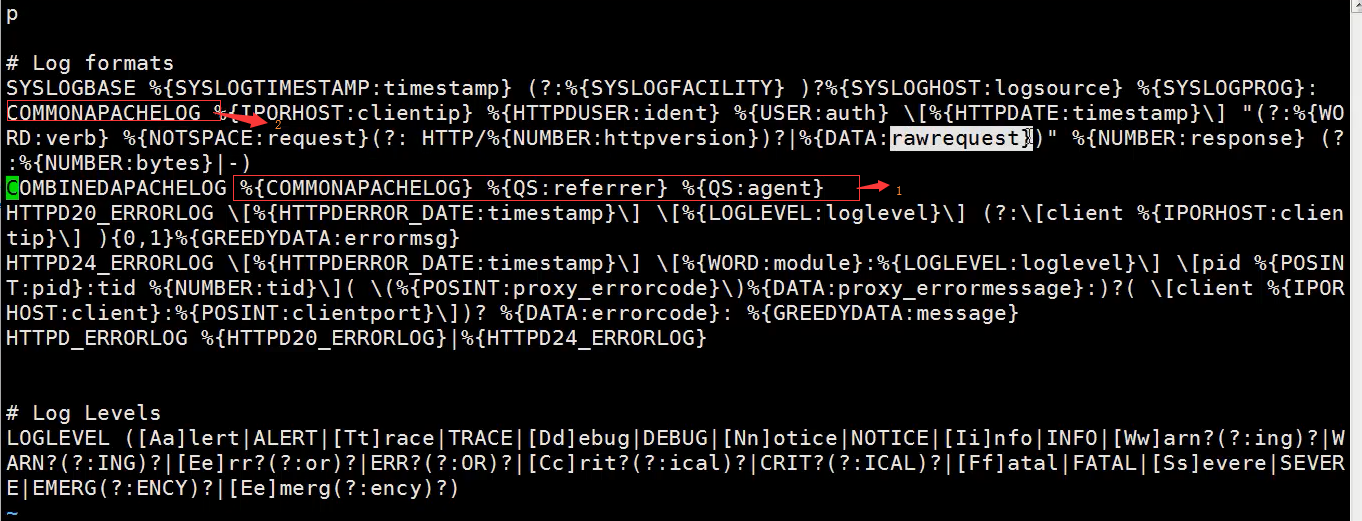
其中截图中序号1的意思是引用序号2中的匹配字段,然后又引用了两次QS匹配字段,QS匹配字段在同目录下的grok-patterns中
c、debuger地址http://grokdebug.herokuapp.com(需FQ)
二、公司架构设计
1、每个ES上面都启动一个Kibana
2、Kibana都连自己的ES
3、前端Nginx负载均衡+ ip_hash + 验证 +ACL
三、rsyslog记录
1、系统日志配置文件在/etc/rsyslog.conf中
2、配置文件中路径前面加 - 是为了不让日志立马写到文件中而是先进行缓存,在很多系统优化中都使用到。
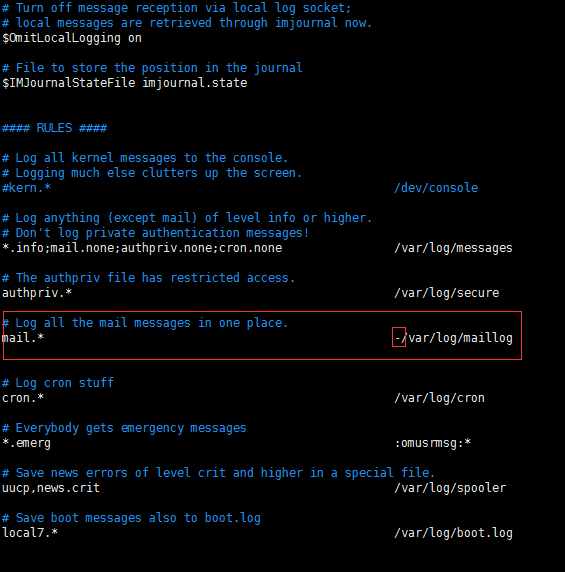
3、要打开系统日志收集功能需要如下操作:
a、sed -i 's/#*.* @@remote-host:514/*.* @@192.168.30.42:514/g' /etc/rsyslog.conf
b、 systemctl restart rsyslog
4、手动产生系统日志方法
logger hehe
四、tcp日志收集
1、给tcp端口发送消息方法
yum install -y nc
a、方法1:
echo "wohaoshuai" | nc 192.168.56.12 6666
b、方法2:
nc 192.168.30.42 6666 < /etc/resolv.conf
c、方法3:伪设备的方式
echo "wohaoshuai" > /dev/tcp/192.168.30.42/6666
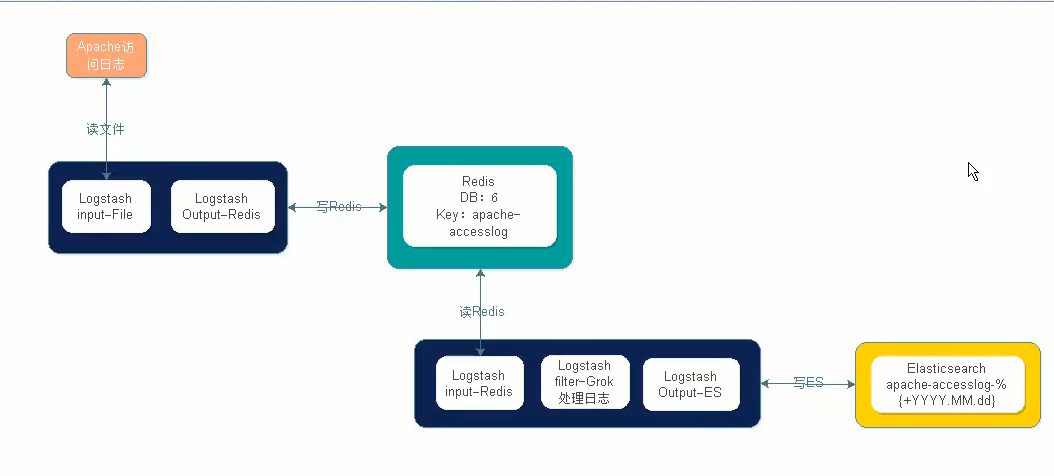
五、收集http日志架构
六、使用elk进行日志收集需求与思路
1、需求分析:
a、访问日志: apache访问日志、nginx访问日志、tomcat file - filter
b、错误日志:error log 、java日志 只接收,java异常需要处理
c、系统日志:/var/log/* syslog syslog,rsyslog
d、运行日志:程序写的 file,json
e、网络日志:防火墙,交换机,路由器的日志 syslog
2、标准化:日志放哪里 (/application/logs),格式是什么(JSON),命名规则 access_log error_log runtime_log 日志怎么切割,按天 按小时。access error crontab进行切分 runtime_log,所有的原始文本 rsync到NAS(文件服务器)后删除最近三天前的。
3、工具化:如何使用logstash进行收集方案
4、如果使用redis list 作为ELKstack的消息队列,那么请对所有list key的长度进行监控 llen key_name
a、根据实际情况,例如超过10万就报警。
七、相应logstash配置文件
1、stdin调试
input{
stdin{}
}
filter{
}
output{
#elasticsearch plugin
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "log-%{+YYYY.MM.dd}"
manage_template => true
}
stdout{
codec => rubydebug
}
}
2、file插件
input{
file{
path => ["/var/log/messages","/var/log/secure"]
#type => "system-log"
start_position => "beginning"
}
}
filter{
}
output{
#elasticsearch plugin
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "system-log-%{+YYYY.MM.dd}"
manage_template => true
}
stdout{
codec => rubydebug
}
}
3、使用type判断
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
file{
path => ["/application/elk/elasticsearch/logs/elk-elasticsearch.log"]
type => "es-log"
start_position => "beginning"
}
}
filter{
}
output{
#elasticsearch plugin
if [type] == "system-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "system-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
if [type] == "es-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "es-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
stdout{
codec => rubydebug
}
}
4、收集某个目录下的所有日志
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
file{
path => ["/application/elk/elasticsearch/logs/elk-elasticsearch.log"]
type => "es-log"
start_position => "beginning"
}
file{
path => ["/application/elk/elasticsearch/logs/**/*.log"]
type => "docker-log"
start_position => "beginning"
}
}
filter{
}
output{
#elasticsearch plugin
if [type] == "system-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "system-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
if [type] == "es-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "es-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
if [type] == "docker-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "docker-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
stdout{
codec => rubydebug
}
}
5、匹配与合并
input{
stdin {
codec => multiline
{
pattern => "^\[" #匹配这个正则
negate => true #匹配到这个正则后,可以为true或false
what => "previous" #和上面这一行合并起来。 还有一个值为next,和下面这一行合并起来.
}
}
}
filter{
}
output{
stdout{
codec => rubydebug
}
}
6、综合后写入es
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
file{
path => ["/application/elk/elasticsearch/logs/elk-elasticsearch.log"]
type => "es-log"
start_position => "beginning"
}
file{
path => ["/application/elk/elasticsearch/logs/containers/**/*.log"]
type => "docker-log"
start_position => "beginning"
codec => multiline
{
pattern => "^\{" #匹配这个正则
negate => true #匹配到这个正则后,可以为true或false
what => "previous" #和上面这一行合并起来。 还有一个值为next,和下面这一行合并起来.
}
}
}
filter{
}
output{
#elasticsearch plugin
if [type] == "system-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "system-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
if [type] == "es-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "es-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
if [type] == "docker-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "docker-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
stdout{
codec => rubydebug
}
}
7、收集nginx日志,并转换成json格式输出到es,nginx日志格式见本章 一.6
input{
file{
path => ["/var/log/nginx/access_log_json.log"]
start_position => "beginning"
codec => "json"
type => "nginx-log"
}
}
filter{
}
output{
if [type] == "nginx-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "nginx-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
stdout{
codec => rubydebug
}
}
8、收集系统日志
input{
syslog{
type => "system-syslog"
port => 514
}
}
filter{
}
output{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "system-syslog-%{+YYYY.MM}"
}
stdout{
codec => rubydebug
}
}
9、收集tcp日志
input{
tcp{
type => "tcp"
port => "6666"
mode => "server" #还有一个client
}
}
filter{
}
output{
stdout{
codec => rubydebug
}
}
10、filter匹配与筛选字段
input{
stdin{
#输入内容为:55.3.244.1 GET /index.html 15824 0.043
}
}
filter{
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output{
stdout{
codec => rubydebug
}
}
11、使用logstash自带的匹配规则匹配http日志
input{
file {
type => "http-log"
path => "/var/log/httpd/access_log"
start_position => beginning
}
}
filter{
grok {
match => {"message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output{
if [type] == "http-log"
{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "http-log-%{+YYYY.MM.dd}"
manage_template => true
}
}
stdout{
codec => rubydebug
}
}
12、获取输入信息到redis
input{
stdin{}
}
output{
redis{
host => "192.168.30.42"
port => "6379"
db => "6"
data_type => "list"
key => "demo"
}
stdout{
codec => rubydebug
}
}
13、收集http日志到redis
input{
file {
type => "http-log"
path => "/var/log/httpd/access_log"
start_position => beginning
}
}
output{
redis{
host => "192.168.30.42"
port => "6379"
db => "6"
data_type => "list"
key => "apache-accesslog"
}
stdout{
codec => rubydebug
}
}
14、获取redis日志到es
input{
redis{
host => "192.168.30.42"
port => "6379"
db => "6"
data_type => "list"
key => "apache-accesslog"
}
}
filter{
grok {
match => {"message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output{
elasticsearch{
hosts => ["192.168.30.41:9200"]
index => "redis-log-%{+YYYY.MM.dd}"
manage_template => true
}
stdout{
codec => rubydebug
}
}
ELK使用3-Logstash的更多相关文章
- ELK初学搭建(logstash)
ELK初学搭建(logstash) elasticsearch logstash kibana ELK初学搭建 logstash 1.环境准备 centos6.8_64 mini IP:192.168 ...
- ELK 架构之 Logstash 和 Filebeat 配置使用(采集过滤)
相关文章: ELK 架构之 Elasticsearch 和 Kibana 安装配置 ELK 架构之 Logstash 和 Filebeat 安装配置 ELK 使用步骤:Spring Boot 日志输出 ...
- ELK(elasticsearch+kibana+logstash)搜索引擎(一): 环境搭建
1.ELK简介 这里简单介绍一下elk架构中的各个组件,关于elk的详细介绍的请自行百度 Elasticsearch是个开源分布式搜索引擎,是整个ELK架构的核心 Logstash可以对数据进行收集. ...
- ELK 性能(1) — Logstash 性能及其替代方案
ELK 性能(1) - Logstash 性能及其替代方案 介绍 当谈及集中日志到 Elasticsearch 时,首先想到的日志传输(log shipper)就是 Logstash.开发者听说过它, ...
- Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日志集中分析平台
日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散在各个生产服务器,且开发人员无法登陆生产服务器,这时候就需要一个集中式的日志收集装置,对日志中的关键字进行监控,触发异常 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
- ELK 架构之 Logstash 和 Filebeat 安装配置
上一篇:ELK 架构之 Elasticsearch 和 Kibana 安装配置 阅读目录: 1. 环境准备 2. 安装 Logstash 3. 配置 Logstash 4. Logstash 采集的日 ...
- elk快速入门-Logstash
Logstash1.功能:数据输入,数据筛选,数据输出2.特性:数据来源中立性,支持众多数据源:如文件log file,指标,网站服务日志,关系型数据库,redis,mq等产生的数据3.beats:分 ...
- ELK Stack 介绍 & Logstash 日志收集
ELK Stack 组成 Software Description Function E:Elasticsearch Java 程序 存储,查询日志 L:Logstash Java 程序 收集.过滤日 ...
随机推荐
- 利用表格分页显示数据的js组件datatable的使用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Kubernetes重要概念理解
Kubernetes重要概念理解 kubernetes是目前最主流的容器编排工具,是下一代分布式架构的王者.2018年的kubernetes第一个版本1.10已经发布.下面整理一下,kubernete ...
- Callcenter 模块解析
CallCenter模块详细介绍 一. Callcenter模块说明: 提供了呼叫中心的ACD功能,把客户端通过不同的”方案”和”等级”分配给来电,一个以”评分”为基础的系统是用来分配这些呼入.来电者 ...
- oracle:10g下载地址(转载)
转载地址:http://www.veryhuo.com/a/view/177074.html Oracle 10g Database和Client多平台官方下载地址 http://www.veryhu ...
- bsdiff的编译与使用
bsdiff是一个差异包比较工具,可以用来实现增量更新. 下载地址:http://www.daemonology.net/bsdiff 编译 Mac环境 版本:macOS 10.12 1.解压下载的b ...
- lua内存监测和回收
以下来自书籍<Cocos2d-x之Lua核心编程> 1.----------------------------------------- 若想查看程序当前的内存占用情况,可以使用Lua提 ...
- Python-Mongodb vs mysql
mongodb https://www.cnblogs.com/kermitjam/articles/10147254.html#_label5 centos安装mongodb: https://bl ...
- 手机CPU架构体系分类及各大厂商
手机cpu相关知识,这对于开发Android应用程序适应各个机型有一定的辅助作用 . 手机cpu架构体系分类 指令集可分为复杂指令集(CISC)和精简指令集(RISC)两部分,代表架构分别是x86.A ...
- mysql 定期删除表中无用数据
MySQL5.1.x版本中引入了一项新特性EVENT,定期执行某些事物,这可以帮助我们实现定期执行某个小功能,不在依赖代码去实现. 我现在有一张表,这张表中的数据有个特点,每天都会有大量数据插入,但是 ...
- CSS学习——基础分类整理
1. CSS 层叠样式表: Cascading Style Sheets,定义如何显示html元素 CSS规则: 选择器{属性: 值; 属性: 值;} CSS注释: /*在这里写注释说 ...