深度学习框架PyTorch一书的学习-第五章-常用工具模块
https://github.com/chenyuntc/pytorch-book/blob/v1.0/chapter5-常用工具/chapter5.ipynb
希望大家直接到上面的网址去查看代码,下面是本人的笔记
在训练神经网络过程中,需要用到很多工具,其中最重要的三部分是:数据、可视化和GPU加速。本章主要介绍Pytorch在这几方面的工具模块,合理使用这些工具能够极大地提高编码效率。
1.数据处理
PyTorch提供了几个高效便捷的工具,以便使用者进行数据处理或增强等操作,同时可通过并行化加速数据加载。
基本原理就是使用Dataset提供数据集的封装,再使用Dataloader实现数据并行加载
1)Dataset
在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法:
__getitem__:返回一条数据,或一个样本。obj[index]等价于obj.__getitem__(index)__len__:返回样本的数量。len(obj)等价于obj.__len__()
这里我们以Kaggle经典挑战赛"Dogs vs. Cat"的数据为例,来详细讲解如何处理数据。"Dogs vs. Cats"是一个分类问题,判断一张图片是狗还是猫,其所有图片都存放在一个文件夹下,根据文件名的前缀判断是狗还是猫。
import torch as t
from torch.utils import data
自定义数据集加载函数:
import os
from PIL import Image
import numpy as np #加载数据
class DogCat(data.Dataset):
def __init__(self, root):
imgs = os.listdir(root)
#所有图片的绝对路径
#这里不实际加载图片,只是指定路径,当调用__getitem__时才会真正读图片
self.imgs = [os.path.join(root, img) for img in imgs] def __getitem__(self, index): #生成图片数据及其标签数据
img_path = self.imgs[index]
#dog则label为1,cat则为0
label = if 'dog' in img_path.split('/')[-] else
pil_img = Image.open(img_path)
array = np.asarray(pil_img)
data = t.from_numpy(array)
return data, label def __len__(self): #得到数据大小信息
return len(self.imgs)
测试:
dataset = DogCat('./data/dogcat/')
img, label = dataset[] #相当于调用dataset.__getitem__()
for img, label in dataset:
print(img.size(), img.float().mean(), label)
返回:
torch.Size([, , ]) tensor(150.5079)
torch.Size([, , ]) tensor(106.4915)
torch.Size([, , ]) tensor(171.8085)
torch.Size([, , ]) tensor(116.8138)
torch.Size([, , ]) tensor(115.5177)
torch.Size([, , ]) tensor(130.3004)
torch.Size([, , ]) tensor(151.7174)
torch.Size([, , ]) tensor(128.1550)
通过上面的代码,我们学习了如何自定义自己的数据集,并可以依次获取。但这里返回的数据不适合实际使用,因其具有如下两方面问题:
- 返回样本的形状不一,因每张图片的大小不一样,这对于需要取batch训练的神经网络来说很不友好
- 返回样本的数值较大,未归一化至[-1, 1]
针对上述问题,PyTorch提供了torchvision1。它是一个视觉工具包,提供了很多视觉图像处理的工具,其中transforms模块提供了对PIL Image对象和Tensor对象的常用操作。
对PIL Image的操作包括:
Scale:调整图片尺寸,长宽比保持不变CenterCrop、RandomCrop、RandomResizedCrop: 裁剪图片Pad:填充ToTensor:将PIL Image对象转成Tensor,会自动将[0, 255]归一化至[0, 1]
对Tensor的操作包括:
- Normalize:标准化,即减均值,除以标准差
- ToPILImage:将Tensor转为PIL Image对象
如果要对图片进行多个操作,可通过Compose函数将这些操作拼接起来,类似于nn.Sequential。注意,这些操作定义后是以函数的形式存在,真正使用时需调用它的__call__方法,这点类似于nn.Module。例如要将图片调整为,首先应构建这个操作
trans = Resize((224, 224)),然后调用trans(img)。
下面我们就用transforms的这些操作来优化上面实现的dataset。
import os
from PIL import Image
import numpy as np
from torchvision import transforms as T transform = T.Compose([
T.Resize(), #缩放图片,保持长宽比不变,最短边为224像素
T.CenterCrop(), #从图片中间切出224*224的图片
T.ToTensor(), #将图片(Image)转成Tensor,归一化至[, ]
T.Normalize(mean=[., ., .], std=[., ., .]) # 标准化至[-, ],规定均值和标准差,即减均值,除以标准差
]) #加载数据
class DogCat(data.Dataset):
def __init__(self, root, transforms=None):
imgs = os.listdir(root)
#所有图片的绝对路径
#这里不实际加载图片,只是指定路径,当调用__getitem__时才会真正读图片
self.imgs = [os.path.join(root, img) for img in imgs]
self.transforms = transform def __getitem__(self, index): #生成图片数据及其标签数据
img_path = self.imgs[index]
#dog则label为1,cat则为0
label = if 'dog' in img_path.split('/')[-] else
data = Image.open(img_path)
if self.transforms:
data = self.transforms(data)
return data, label def __len__(self): #得到数据大小信息
return len(self.imgs) dataset = DogCat('./data/dogcat/', transforms=transform)
img, label = dataset[]
for img, label in dataset:
print(img.size(), label)
返回:
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
torch.Size([, , ])
除了上述操作之外,transforms还可通过Lambda封装自定义的转换策略。例如想对PIL Image进行随机旋转,则可写成这样:
trans=T.Lambda(lambda img: img.rotate(random()*))
torchvision已经预先实现了常用的Dataset,包括前面使用过的CIFAR-10,以及ImageNet、COCO、MNIST、LSUN等数据集,可通过诸如torchvision.datasets.CIFAR10来调用,具体使用方法请参看官方文档1。在这里介绍一个会经常使用到的Dataset——ImageFolder,它的实现和上述的DogCat很相似。
ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
它主要有四个参数:
root:在root指定的路径下寻找图片transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象target_transform:对label的转换loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象
label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。
有以下成员变量:
- self.classes - 用一个list保存 类名
- self.class_to_idx - 类名对应的 索引
- self.imgs - 保存(图片路径, 图片class) tuple的list
比如文件:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png root/cat/.png
root/cat/nsdf3.png
root/cat/asd932_.png
调用为:
dset.ImageFolder(root="root folder path", [transform, target_transform])
开始操作:
from torchvision.datasets import ImageFolder
dataset = ImageFolder('data/dogcat_2/')
查看:
# cat文件夹的图片对应label ,dog对应1
dataset.class_to_idx
返回:
{'cat': , 'dog': }
#图片对应的类别
dataset.classes
返回:
['cat', 'dog']
# 所有图片的路径和对应的label
dataset.imgs
返回:
[('data/dogcat_2/cat/cat.12484.jpg', ),
('data/dogcat_2/cat/cat.12485.jpg', ),
('data/dogcat_2/cat/cat.12486.jpg', ),
('data/dogcat_2/cat/cat.12487.jpg', ),
('data/dogcat_2/dog/dog.12496.jpg', ),
('data/dogcat_2/dog/dog.12497.jpg', ),
('data/dogcat_2/dog/dog.12498.jpg', ),
('data/dogcat_2/dog/dog.12499.jpg', )]
# 没有任何的transform,所以返回的还是PIL Image对象
print(dataset[][]) # 第一维是第几张图,第二维为1返回label,返回0
dataset[][] # 为0返回图片数据
图示:

定义transform:
#加上transform
#给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。
#即:Normalized_image=(image-mean)/std
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([
T.RandomResizedCrop(), #先将给定的PIL.Image随机切,然后再resize成给定的size大小
T.RandomHorizontalFlip(), #随机水平翻转,概率为0.。即:一半的概率翻转,一半的概率不翻转
#把一个取值范围是[,]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,
#转换成形状为[C,H,W],取值范围是[,1.0]的torch.FloadTensor
T.ToTensor(),
normalize,
])
获取图片数据:
dataset = ImageFolder('data/dogcat_2/', transform=transform)
查看图片数据大小:
## 深度学习中图片数据一般保存成CxHxW,即通道数x图片高x图片宽
dataset[][].size()
返回:
torch.Size([, , ])
将tensor图片数据变回图片:
to_img = T.ToPILImage()
#将dataset[][]的图片数据通过和标准差和均值的计算重新返回成图片
to_img(dataset[][]*0.2+0.4)
图示:

2.DataLoader
Dataset__getitem__只返回一个样本。前面提到过,在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助我们实现这些功能。
DataLoader的函数定义如下:
DataLoader(dataset, batch_size=, shuffle=False, sampler=None, num_workers=, collate_fn=default_collate, pin_memory=False, drop_last=False)
- dataset:加载的数据集(Dataset对象)
- batch_size:batch size
- shuffle::是否将数据打乱
- sampler: 样本抽样,后续会详细介绍
- num_workers:使用多进程加载的进程数,0代表不使用多进程
- collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
- pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
- drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
下面举例说明:
from torch.utils.data import DataLoader
#上面对数据处理后得到dataset,下面使用DataLoader实现其他操作
dataloader = DataLoader(dataset, batch_size=, shuffle=True, num_workers=, drop_last=False)
dataiter = iter(dataloader)
imgs, labels = next(dataiter)
imgs.size() # batch_size, channel, height, weight
返回:
torch.Size([, , , ])
dataloader是一个可迭代的对象,意味着我们可以像使用迭代器一样使用它,例如:
for batch_datas, batch_labels in dataloader:
train()
或
dataiter = iter(dataloader)
batch_datas, batch_labesl = next(dataiter)
1》图片出问题时的解决方法:
1)将出错的样本剔除
在数据处理中,有时会出现某个样本无法读取等问题,比如某张图片损坏。这时在__getitem__函数中将出现异常,此时最好的解决方案即是将出错的样本剔除。如果实在是遇到这种情况无法处理,则可以返回None对象,然后在Dataloader中实现自定义的collate_fn,将空对象过滤掉。但要注意,在这种情况下dataloader返回的batch数目会少于batch_size。
下面举例说明:
class NewDogCat(DogCat): #继承前面实现的DogCat数据集
def __getitem__(self, index):
try:
# 调用父类的获取函数,即 DogCat.__getitem__(self, index)
return super(NewDogCat, self).__getitem__(index)
except:
return None, None
from torch.utils.data.dataloader import default_collate #导入默认的拼接方式
#自定义
def my_collate_fn(batch):
'''
batch中每个元素形如(data, label)
'''
# 过滤为None的数据
batch = list(filter(lambda x : x[] is not None, batch))
if len(batch) == : return t.Tensor()
return default_collate(batch) # 用默认方式拼接过滤后的batch数据
获取dataset:
#会去调用父类DogCat生成dataset
dataset = NewDogCat('data/dogcat_wrong/', transforms=transform)
查看:
dataset[]
返回:
(tensor([[[ 0.9804, 1.0196, 1.0980, ..., -1.1765, -1.1373, -1.1176],
[ 0.9804, 1.0196, 1.0980, ..., -1.1765, -1.1373, -1.1176],
[ 1.0588, 1.0980, 1.1765, ..., -1.1961, -1.1569, -1.1373],
...,
[ 2.2941, 2.2941, 2.3137, ..., 2.4902, 2.5098, 2.5098],
[ 2.2941, 2.2941, 2.3137, ..., 2.4902, 2.4902, 2.4902],
[ 2.2941, 2.2941, 2.3137, ..., 2.4902, 2.4902, 2.4902]], [[ 0.8824, 0.9216, 1.0000, ..., -1.2157, -1.1765, -1.1569],
[ 0.8824, 0.9216, 1.0000, ..., -1.2157, -1.1765, -1.1569],
[ 0.9608, 1.0000, 1.0784, ..., -1.2353, -1.1961, -1.1765],
...,
[ 2.1961, 2.1961, 2.2157, ..., 2.4902, 2.4902, 2.4902],
[ 2.1961, 2.1961, 2.2157, ..., 2.4902, 2.4902, 2.4902],
[ 2.1961, 2.1961, 2.2157, ..., 2.4902, 2.4902, 2.4902]], [[ 0.8235, 0.8627, 0.9412, ..., -1.1961, -1.1569, -1.1373],
[ 0.8235, 0.8627, 0.9412, ..., -1.1961, -1.1569, -1.1373],
[ 0.9020, 0.9412, 1.0196, ..., -1.2157, -1.1765, -1.1569],
...,
[ 2.0784, 2.0784, 2.0980, ..., 2.3529, 2.3529, 2.3529],
[ 2.0784, 2.0784, 2.0980, ..., 2.3333, 2.3333, 2.3333],
[ 2.0784, 2.0784, 2.0980, ..., 2.3333, 2.3333, 2.3333]]]), )
得到dataloader:
#然后对dataset进行处理,使用自定义的collate_fn
dataloader = DataLoader(dataset, , collate_fn=my_collate_fn, num_workers=,shuffle=True)
for batch_datas, batch_labels in dataloader:
print(batch_datas.size(), batch_labels.size())
返回:
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
来看一下上述batch_size的大小。其中第3个的batch_size为1,这是因为有一张图片损坏,导致其无法正常返回。而最后1个的batch_size也为1,这是因为共有9张(包括损坏的文件)图片,无法整除2(batch_size),因此最后一个batch的数据会少于batch_szie,可通过指定drop_last=True来丢弃最后一个不足batch_size的batch。
2)随机取一张图片代替
对于诸如样本损坏或数据集加载异常等情况,还可以通过其它方式解决。例如但凡遇到异常情况,就随机取一张图片代替:
import random
class NewDogCat(DogCat): #继承前面实现的DogCat数据集
def __getitem__(self, index):
try:
# 调用父类的获取函数,即 DogCat.__getitem__(self, index)
return super(NewDogCat, self).__getitem__(index)
except:
#更改这里成随机选取一个图片替代
new_index = random.randint(,len(self)-)
return self[new_index]
from torch.utils.data.dataloader import default_collate #导入默认的拼接方式
#自定义
def my_collate_fn(batch):
'''
batch中每个元素形如(data, label)
'''
# 过滤为None的数据
batch = list(filter(lambda x : x[] is not None, batch))
if len(batch) == : return t.Tensor()
return default_collate(batch) # 用默认方式拼接过滤后的batch数据
生成dataset:
#会去调用父类DogCat生成dataset
dataset = NewDogCat('data/dogcat_wrong/', transforms=transform)
生成dataloader并调用:
#然后对dataset进行处理,使用自定义的collate_fn
dataloader = DataLoader(dataset, , collate_fn=my_collate_fn, num_workers=,shuffle=True)
for batch_datas, batch_labels in dataloader:
print(batch_datas.size(), batch_labels.size())
返回:
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([])
torch.Size([, , , ]) torch.Size([]) #这是因为只有9张数据
相比较丢弃异常图片而言,这种做法会更好一些,因为它能保证每个batch的数目仍是batch_size
3)彻底清洗
但在大多数情况下,最好的方式还是对数据进行彻底清洗。
2》DataLoader的多进程-multiprocessing
DataLoader里面并没有太多的魔法方法,它封装了Python的标准库multiprocessing,使其能够实现多进程加速。在此提几点关于Dataset和DataLoader使用方面的建议:
- 高负载的操作放在
__getitem__中,如加载图片等。 - dataset中应尽量只包含只读对象,避免修改任何可变对象,利用多线程进行操作。
第一点是因为多进程会并行的调用__getitem__函数,将负载高的放在__getitem__函数中能够实现并行加速。
第二点是因为dataloader使用多进程加载,如果在Dataset实现中使用了可变对象,可能会有意想不到的冲突。在多线程/多进程中,修改一个可变对象,需要加锁,但是dataloader的设计使得其很难加锁(在实际使用中也应尽量避免锁的存在),因此最好避免在dataset中修改可变对象。
例如下面就是一个不好的例子,在多进程处理中self.num可能与预期不符,这种问题不会报错,因此难以发现。如果一定要修改可变对象,建议使用Python标准库Queue中的相关数据结构。
class BadDataset(Dataset):
def __init__(self):
self.datas = range()
self.num = # 取数据的次数
def __getitem__(self, index):
self.num +=
return self.datas[index]
使用Python multiprocessing库的另一个问题是,在使用多进程时,如果主程序异常终止(比如用Ctrl+C强行退出),相应的数据加载进程可能无法正常退出。这时你可能会发现程序已经退出了,但GPU显存和内存依旧被占用着,或通过top、ps aux依旧能够看到已经退出的程序,这时就需要手动强行杀掉进程。建议使用如下命令:
ps x | grep <cmdline> | awk '{print $1}' | xargs kill
ps x:获取当前用户的所有进程grep <cmdline>:找到已经停止的PyTorch程序的进程,例如你是通过python train.py启动的,那你就需要写grep 'python train.py'awk '{print $1}':获取进程的pidxargs kill:杀掉进程,根据需要可能要写成xargs kill -9强制杀掉进程
在执行这句命令之前,建议先打印确认一下是否会误杀其它进程
ps x | grep <cmdline> | ps x
3》sampler——采样(shuffle=True时使用)
PyTorch中还单独提供了一个sampler模块,用来对数据进行采样。
常用的有随机采样器:RandomSampler,当dataloader的shuffle参数为True时,系统会自动调用这个采样器,实现打乱数据。默认的是采用SequentialSampler,它会按顺序一个一个进行采样。
这里介绍另外一个很有用的采样方法: WeightedRandomSampler,它会根据每个样本的权重选取数据,在样本比例不均衡的问题中,可用它来进行重采样。
构建WeightedRandomSampler时需提供两个参数:
- 每个样本的权重
weights - 共选取的样本总数
num_samples
以及一个可选参数replacement
replacement用于指定是否可以重复选取某一个样本,默认为True,即允许在一个epoch中重复采样某一个数据。如果设为False,则当某一类的样本被全部选取完,但其样本数目仍未达到num_samples时,sampler将不会再从该类中选择数据,此时可能导致weights参数失效。
权重越大的样本被选中的概率越大,待选取的样本数目一般小于全部的样本数目。
下面举例说明:
dataset = DogCat('data/dogcat/', transforms=transform)
# 狗的图片被取出的概率是猫的概率的两倍,狗是1,猫是0
# 两类图片被取出的概率与weights的绝对大小无关,只和比值有关
weights = [ if label == else for data, label in dataset]
weights
返回:
[, , , , , , , ]
from torch.utils.data.sampler import WeightedRandomSampler
sampler = WeightedRandomSampler(weights, num_samples=,replacement=True)
dataloader = DataLoader(dataset, batch_size=,sampler=sampler)
for datas, labels in dataloader:
print(labels.tolist())
返回:
[, , ]
[, , ]
[, , ]
可见狗猫样本比例约为2:1,另外一共只有8个样本,但是却返回了9个,说明肯定有被重复返回的,这就是replacement参数的作用,下面将replacement设为False试试:
sampler = WeightedRandomSampler(weights, , replacement=False)
dataloader = DataLoader(dataset, batch_size=, sampler=sampler)
for datas, labels in dataloader:
print(labels.tolist())
返回:
[, , , ]
[, , , ]
在这种情况下,num_samples等于dataset的样本总数,为了不重复选取,sampler会将每个样本都返回,这样就失去weight参数的意义了。
从上面的例子可见sampler在样本采样中的作用:如果指定了sampler,shuffle将不再生效,并且sampler.num_samples会覆盖dataset的实际大小,即一个epoch返回的图片总数取决于sampler.num_samples。
3.计算机视觉工具包:torchvision
计算机视觉是深度学习中最重要的一类应用,为了方便研究者使用,PyTorch团队专门开发了一个视觉工具包torchvion,这个包独立于PyTorch,需通过pip instal torchvision安装。
在之前的例子中我们已经见识到了它的部分功能,这里再做一个系统性的介绍。torchvision主要包含三部分:
- models:提供深度学习中各种经典网络的网络结构以及预训练好的模型,包括
AlexNet、VGG系列、ResNet系列、Inception系列等。 - datasets: 提供常用的数据集加载,设计上都是继承
torhc.utils.data.Dataset,主要包括MNIST、CIFAR10/100、ImageNet、COCO等。 - transforms:提供常用的数据预处理操作,主要包括对Tensor以及PIL Image对象的操作。
1)models
from torchvision import models
from torch import nn
# 加载预训练好的模型,如果不存在会进行下载
# 预训练好的模型保存在 ~/.torch/models/下面
resnet34 = models.squeezenet1_1(pretrained=True, num_classes=) # 修改最后的全连接层为10分类问题(默认是ImageNet上的1000分类)
resnet34.fc=nn.Linear(, )
然后会开始下载模型:
Downloading: "https://download.pytorch.org/models/squeezenet1_1-f364aa15.pth" to /Users/user/.torch/models/squeezenet1_1-f364aa15.pth
4966400.0 bytes
2)datasets
下载数据:
from torchvision import datasets
# 指定数据集路径为data,如果数据集不存在则进行下载
# 通过train=False获取测试集
dataset = datasets.MNIST('data/', download=True, train=False, transform=transform)
返回:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
100.1%
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
113.5%
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
100.4%
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
180.4%
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Processing...
Done!
3)transforms
Transforms中涵盖了大部分对Tensor和PIL Image的常用处理,这些已在上文提到,这里就不再详细介绍。
需要注意的是转换分为两步
- 第一步:构建转换操作,例如
transf = transforms.Normalize(mean=x, std=y), - 第二步:执行转换操作,例如
output = transf(input)。
另外还可将多个处理操作用Compose拼接起来,形成一个处理转换流程。
from torchvision import transforms
to_pil = transforms.ToPILImage()
to_pil(t.randn(, , ))
图示:

4)常用函数
torchvision还提供了两个常用的函数。
一个是make_grid,它能将多张图片拼接成一个网格中;
另一个是save_img,它能将Tensor保存成图片。
dataloader = DataLoader(dataset, shuffle=True, batch_size=)
from torchvision.utils import make_grid, save_image
dataiter = iter(dataloader)
img = make_grid(next(dataiter)[], ) #[]是图片,[]是label,拼成4*4网格图片,且会转成3通道
save_image(img,'a.png')
出错:
RuntimeError: output with shape [, , ] doesn't match the broadcast shape [3, 224, 224]
好像make_grid并不能转成3通道啊?????
如果换成使用的是彩色图像,就成功运行:
dataset = DogCat('data/dogcat/', transforms=transform)
dataloader = DataLoader(dataset, shuffle=True, batch_size=)
from torchvision.utils import make_grid, save_image
dataiter = iter(dataloader)
img = make_grid(next(dataiter)[], ) #[]是图片,[]是label,拼成4*4网格图片,且会转成3通道
save_image(img,'a.png')
存储得到的a.png为:
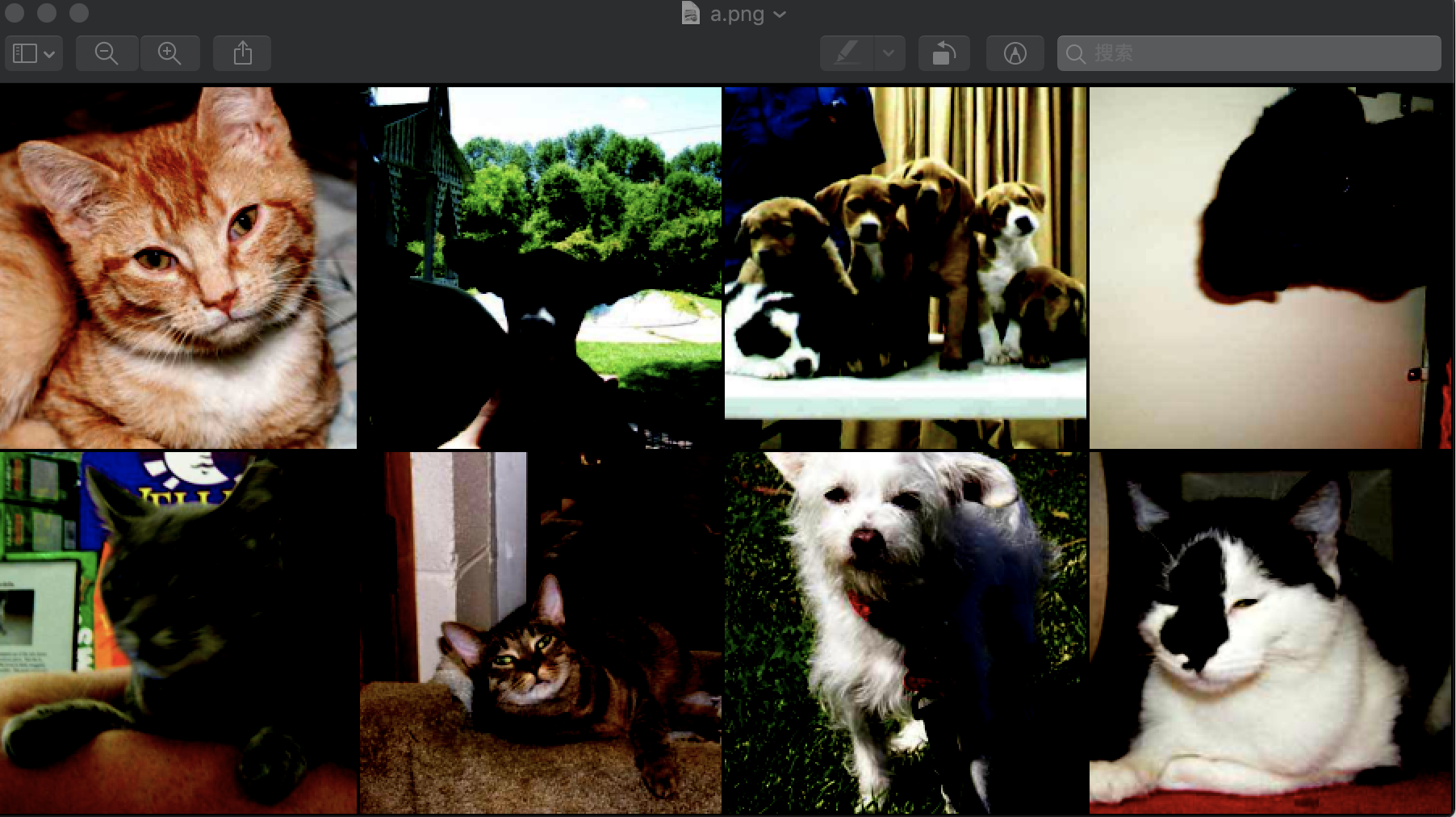
可以使用下面语句查看图像:
Image.open('a.png')
4.可视化工具
在训练神经网络时,我们希望能更直观地了解训练情况,包括损失曲线、输入图片、输出图片、卷积核的参数分布等信息。这些信息能帮助我们更好地监督网络的训练过程,并为参数优化提供方向和依据。最简单的办法就是打印输出,但其只能打印数值信息,不够直观,同时无法查看分布、图片、声音等。在本节,我们将介绍两个深度学习中常用的可视化工具:Tensorboard和Visdom
1)Tensorboard
Tensorboard最初是作为TensorFlow的可视化工具迅速流行开来。作为和TensorFlow深度集成的工具,Tensorboard能够展现你的TensorFlow网络计算图,绘制图像生成的定量指标图以及附加数据。但同时Tensorboard也是一个相对独立的工具,只要用户保存的数据遵循相应的格式,tensorboard就能读取这些数据并进行可视化。这里我们将主要介绍如何在PyTorch中使用tensorboardX1进行训练损失的可视化。 TensorboardX是将Tensorboard的功能抽取出来,使得非TensorFlow用户也能使用它进行可视化,几乎支持原生TensorBoard的全部功能。
在这里选择了其中一个来学习,选择了下面的Visdom
2)Visdom
可见pytorch visdom可视化工具学习—1—安装和使用
5.使用GPU加速:cuda
这部分内容在前面介绍Tensor、Module时大都提到过,这里将做一个总结,并深入介绍相关应用。
在PyTorch中以下数据结构分为CPU和GPU两个版本:
- Tensor
- nn.Module(包括常用的layer、loss function,以及容器Sequential等)
它们都带有一个.cuda方法,调用此方法即可将其转为对应的GPU对象。
注意,tensor.cuda会返回一个新对象,这个新对象的数据已转移至GPU,而之前的tensor还在原来的设备上(CPU)。
而module.cuda则会将所有的数据都迁移至GPU,并返回自己。所以module = module.cuda()和module.cuda()所起的作用一致。
nn.Module在GPU与CPU之间的转换,本质上还是利用了Tensor在GPU和CPU之间的转换。nn.Module的cuda方法是将nn.Module下的所有parameter(包括子module的parameter)都转移至GPU,而Parameter本质上也是tensor(Tensor的子类)。
下面将举例说明,这部分代码需要你具有两块GPU设备。但是因为我的机器中只有一块GPU,所以只能运行看看感觉,有些地方将会有点不同
P.S. 为什么将数据转移至GPU的方法叫做.cuda而不是.gpu,就像将数据转移至CPU调用的方法是.cpu?这是因为GPU的编程接口采用CUDA,而目前并不是所有的GPU都支持CUDA,只有部分Nvidia的GPU才支持。PyTorch未来可能会支持AMD的GPU,而AMD GPU的编程接口采用OpenCL,因此PyTorch还预留着.cl方法,用于以后支持AMD等的GPU。
user@home:/opt/user$ python
Python 3.6. |Anaconda custom (-bit)| (default, Oct , ::)
[GCC 7.2.] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch as t
>>> tensor = t.Tensor(,)
>>> tensor.cuda() #返回一个新的tensor,保存在第0块GPU上,但原来的tensor并没有改变
tensor([[-4.5677e+20, 3.0805e-41, 3.7835e-44, 0.0000e+00],
[ nan, 4.5817e-41, 1.3733e-14, 6.4069e+02],
[ 4.3066e+21, 1.1824e+22, 4.3066e+21, 6.3828e+28]], device='cuda:0')
>>> tensor.is_cuda
False
>>> tensor1 = tensor.cuda() # 不指定所使用的GPU设备,将默认使用第1块GPU
>>> tensor1.is_cuda
True
>>> tensor1.get_device() >>> tensor2 = tensor.cuda()
#因为我的机器上只有一个GPU,所以如果想要设置第二块GPU则会报错
Traceback (most recent call last):
File "<stdin>", line , in <module>
RuntimeError: CUDA error: invalid device ordinal
>>> from torch import nn
>>> module = nn.Linear(,)
#将模块设置为.cuda(),这样模块中的参数也会自动使用GPU
>>> module.cuda(device=)
Linear(in_features=, out_features=, bias=True)
>>> module.weight.is_cuda
True
在定义网络时也可以直接在声明参数的时候指定运行的GPU:
#-*- coding: utf- -*-
from __future__ import print_function
import torch as t class VeryBigModule(nn.Module):
def __init__(self):
super(VeryBigModule, self).__init__()
self.GiantParameter1 = t.nn.Parameter(t.randn(, )).cuda()
self.GiantParameter2 = t.nn.Parameter(t.randn(, )).cuda() def forward(self, x):
x = self.GiantParameter1.mm(x.cuda())
x = self.GiantParameter2.mm(x.cuda())
return x
上面最后一部分中,两个Parameter所占用的内存空间都非常大,大概是8个G,如果将这两个都同时放在一块GPU上几乎会将显存占满,无法再进行任何其它运算。此时可通过这种方式将不同的计算分布到不同的GPU中。
关于使用GPU的一些建议:
- GPU运算很快,但对于很小的运算量来说,并不能体现出它的优势,因此对于一些简单的操作可直接利用CPU完成
- 数据在CPU和GPU之间,以及GPU与GPU之间的传递会比较耗时,应当尽量避免
- 在进行低精度的计算时,可以考虑
HalfTensor,它相比于FloatTensor能节省一半的显存,但需千万注意数值溢出的情况。
另外这里需要专门提一下,大部分的损失函数也都属于nn.Module,但在使用GPU时,很多时候我们都忘记使用它的.cuda方法,这在大多数情况下不会报错,因为损失函数本身没有可学习的参数(learnable parameters)。
但在某些情况下会出现问题,为了保险起见同时也为了代码更规范,应记得调用criterion.cuda。
下面举例说明:
# 交叉熵损失函数,带权重
>>> criterion = t.nn.CrossEntropyLoss(weight=t.Tensor([,]))
>>> input = t.randn(,).cuda()
>>> target = t.Tensor([,,,]).long().cuda() # 下面这行会报错,因weight未被转移至GPU
# loss = criterion(input, target) >>> criterion.cuda()
CrossEntropyLoss()
>>> loss = criterion(input, target)
>>> criterion._buffers
OrderedDict([('weight', tensor([., .], device='cuda:0'))])
而除了调用对象的.cuda方法之外,还可以使用torch.cuda.device,来指定默认使用哪一块GPU:
>>> with t.cuda.device():
... a = t.cuda.FloatTensor(,)
... b = t.FloatTensor(,).cuda() #如果没有显示声明,就会报错
... print(a.get_device() == b.get_device() == )
...
... c = a + b
... print(c.get_device() == )
...
True
Traceback (most recent call last):
File "<stdin>", line , in <module>
RuntimeError: CUDA error: invalid device ordinal
从上面的情况发现最好还是显示指明使用的GPU,所以改成下面这样就可以了:
>>> with t.cuda.device():
... a = t.cuda.FloatTensor(,)
... b = t.FloatTensor(,).cuda()
... print(a.get_device() == b.get_device() == )
... c = a + b
... print(c.get_device() == )
... d = t.randn(,).cuda()
... print(d.get_device())
...
True
True
还可以使用torch.set_default_tensor_type使程序默认使用GPU,不需要手动调用cuda
>>> t.set_default_tensor_type('torch.cuda.FloatTensor')
>>> a = t.ones(,)
>>> a.is_cuda
True
如果服务器具有多个GPU,tensor.cuda()方法会将tensor保存到第一块GPU上,等价于tensor.cuda(0)。此时如果想使用第二块GPU,需手动指定tensor.cuda(1),而这需要修改大量代码,很是繁琐。
这里有两种替代方法:
- 一种是先调用
t.cuda.set_device(1)指定使用第二块GPU,后续的.cuda()都无需更改,切换GPU只需修改这一行代码。 - 更推荐的方法是设置环境变量
CUDA_VISIBLE_DEVICES,例如当export CUDA_VISIBLE_DEVICE=1(下标是从0开始,1代表第二块GPU),只使用第二块物理GPU,但在程序中这块GPU会被看成是第一块逻辑GPU,因此此时调用tensor.cuda()会将Tensor转移至第二块物理GPU。CUDA_VISIBLE_DEVICES还可以指定多个GPU,如export CUDA_VISIBLE_DEVICES=0,2,3,那么第一、三、四块物理GPU会被映射成第一、二、三块逻辑GPU,tensor.cuda(1)会将Tensor转移到第三块物理GPU上。
设置CUDA_VISIBLE_DEVICES有两种方法:
- 一种是在命令行中
CUDA_VISIBLE_DEVICES=0,1 python main.py - 一种是在程序中
import os;os.environ["CUDA_VISIBLE_DEVICES"] = "2"。如果使用IPython或者Jupyter notebook,还可以使用%env CUDA_VISIBLE_DEVICES=1,2来设置环境变量。
从 0.4 版本开始,pytorch新增了tensor.to(device)方法,能够实现设备透明,便于实现CPU/GPU兼容。这部份内容已经在第三章讲解过了。
从PyTorch 0.2版本中,PyTorch新增分布式GPU支持。分布式是指有多个GPU在多台服务器上,而并行一般指的是一台服务器上的多个GPU。分布式涉及到了服务器之间的通信,因此比较复杂,PyTorch封装了相应的接口,可以用几句简单的代码实现分布式训练。分布式对普通用户来说比较遥远,因为搭建一个分布式集群的代价十分大,使用也比较复杂。相比之下一机多卡更加现实。对于分布式训练,这里不做太多的介绍,感兴趣的读者可参考文档1。
单机多卡并行
要实现模型单机多卡十分容易,直接使用 new_module = nn.DataParallel(module, device_ids), 默认会把模型分布到所有的卡上。多卡并行的机制如下:
- 将模型(module)复制到每一张卡上
- 将形状为(N,C,H,W)的输入均等分为 n份(假设有n张卡),每一份形状是(N/n, C,H,W),然后在每张卡前向传播,反向传播,梯度求平均。要求batch-size 大于等于卡的个数(N>=n)
在绝大多数情况下,new_module的用法和module一致,除了极其特殊的情况下(RNN中的PackedSequence)。另外想要获取原始的单卡模型,需要通过new_module.module访问。
6.持久化
在PyTorch中,以下对象可以持久化到硬盘,并能通过相应的方法加载到内存中:
- Tensor
- Variable
- nn.Module
- Optimizer
本质上上述这些信息最终都是保存成Tensor。Tensor的保存和加载十分的简单,使用t.save和t.load即可完成相应的功能。在save/load时可指定使用的pickle模块,在load时还可将GPU tensor映射到CPU或其它GPU上。
我们可以通过t.save(obj, file_name)等方法保存任意可序列化的对象到file_name文件中,然后通过obj = t.load(file_name)方法加载保存的数据file_name。
对于Module和Optimizer对象,这里建议保存对应的state_dict,而不是直接保存整个Module/Optimizer对象。Optimizer对象保存的主要是参数,以及动量信息,通过加载之前的动量信息,能够有效地减少模型震荡
下面举例说明:
>>> a = t.Tensor(,)
>>> if t.cuda.is_available():
... a = a.cuda() # 把a转为GPU0上
... t.save(a, 'a.pth') #保存a的值到'a.pth'
... b = t.load('a.pth') #加载'a.pth'为b, 因为保存时tensor在GPU0上,所以b也会存储与GPU0
... c = t.load('a.pth', map_location=lambda storage, loc:storage) #加载为c, 存储于CPU
...
>>> b
tensor([[1.0373e-22, 9.1637e-41, 1.0373e-22, 9.1637e-41],
[2.5318e-12, 3.2127e+21, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
>>> a
tensor([[1.0373e-22, 9.1637e-41, 1.0373e-22, 9.1637e-41],
[2.5318e-12, 3.2127e+21, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
>>> a.get_device() == b.get_device()
True
>>> c.is_cuda #可见c为CPU
False
>>> c #三者的值是相同的
tensor([[1.0373e-22, 9.1637e-41, 1.0373e-22, 9.1637e-41],
[2.5318e-12, 3.2127e+21, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]], device='cpu')
存储模型和优化器参数:
>>> t.set_default_tensor_type('torch.FloatTensor')
>>> from torchvision.models import SqueezeNet
>>> model = SqueezeNet()
# module的state_dict是一个字典
>>> model.state_dict().keys()
odict_keys(['features.0.weight', 'features.0.bias', 'features.3.squeeze.weight', 'features.3.squeeze.bias', 'features.3.expand1x1.weight', 'features.3.expand1x1.bias', 'features.3.expand3x3.weight', 'features.3.expand3x3.bias', 'features.4.squeeze.weight', 'features.4.squeeze.bias', 'features.4.expand1x1.weight', 'features.4.expand1x1.bias', 'features.4.expand3x3.weight', 'features.4.expand3x3.bias', 'features.5.squeeze.weight', 'features.5.squeeze.bias', 'features.5.expand1x1.weight', 'features.5.expand1x1.bias', 'features.5.expand3x3.weight', 'features.5.expand3x3.bias', 'features.7.squeeze.weight', 'features.7.squeeze.bias', 'features.7.expand1x1.weight', 'features.7.expand1x1.bias', 'features.7.expand3x3.weight', 'features.7.expand3x3.bias',
'features.8.squeeze.weight', 'features.8.squeeze.bias', 'features.8.expand1x1.weight', 'features.8.expand1x1.bias', 'features.8.expand3x3.weight', 'features.8.expand3x3.bias', 'features.9.squeeze.weight', 'features.9.squeeze.bias', 'features.9.expand1x1.weight', 'features.9.expand1x1.bias', 'features.9.expand3x3.weight', 'features.9.expand3x3.bias', 'features.10.squeeze.weight', 'features.10.squeeze.bias', 'features.10.expand1x1.weight', 'features.10.expand1x1.bias', 'features.10.expand3x3.weight',
'features.10.expand3x3.bias', 'features.12.squeeze.weight', 'features.12.squeeze.bias', 'features.12.expand1x1.weight', 'features.12.expand1x1.bias', 'features.12.expand3x3.weight', 'features.12.expand3x3.bias', 'classifier.1.weight', 'classifier.1.bias'])
# Module对象的保存与加载
>>> t.save(model.state_dict(), 'squeezenet.pth')
>>> model.load_state_dict(t.load('squeezenet.pth'))
#优化器
>>> optimizer = t.optim.Adam(model.parameters(), lr=0.1)
>>> t.save(optimizer.state_dict(), 'optimizer.pth')
>>> optimizer.load_state_dict(t.load('optimizer.pth'))
#将两者的状态存放在一起
>>> all_data = dict(
... optimizer = optimizer.state_dict(),
... model = model.state_dict(),
... info = 'the all parameters of model and optimizer'
... )
>>> t.save(all_data, 'all.pth')
>>> load_all_data = t.load('all.pth')
>>> load_all_data.keys()
dict_keys(['optimizer', 'model', 'info'])
>>> load_all_data['model'].keys()
odict_keys(['features.0.weight', 'features.0.bias', 'features.3.squeeze.weight', 'features.3.squeeze.bias', 'features.3.expand1x1.weight', 'features.3.expand1x1.bias', 'features.3.expand3x3.weight', 'features.3.expand3x3.bias', 'features.4.squeeze.weight', 'features.4.squeeze.bias', 'features.4.expand1x1.weight', 'features.4.expand1x1.bias', 'features.4.expand3x3.weight', 'features.4.expand3x3.bias', 'features.5.squeeze.weight', 'features.5.squeeze.bias', 'features.5.expand1x1.weight', 'features.5.expand1x1.bias', 'features.5.expand3x3.weight', 'features.5.expand3x3.bias', 'features.7.squeeze.weight', 'features.7.squeeze.bias', 'features.7.expand1x1.weight', 'features.7.expand1x1.bias', 'features.7.expand3x3.weight', 'features.7.expand3x3.bias', 'features.8.squeeze.weight', 'features.8.squeeze.bias', 'features.8.expand1x1.weight', 'features.8.expand1x1.bias', 'features.8.expand3x3.weight', 'features.8.expand3x3.bias', 'features.9.squeeze.weight', 'features.9.squeeze.bias', 'features.9.expand1x1.weight', 'features.9.expand1x1.bias', 'features.9.expand3x3.weight', 'features.9.expand3x3.bias', 'features.10.squeeze.weight', 'features.10.squeeze.bias', 'features.10.expand1x1.weight', 'features.10.expand1x1.bias', 'features.10.expand3x3.weight', 'features.10.expand3x3.bias', 'features.12.squeeze.weight', 'features.12.squeeze.bias', 'features.12.expand1x1.weight', 'features.12.expand1x1.bias', 'features.12.expand3x3.weight', 'features.12.expand3x3.bias', 'classifier.1.weight', 'classifier.1.bias'])
>>> load_all_data['optimizer'].keys()
dict_keys(['state', 'param_groups'])
深度学习框架PyTorch一书的学习-第五章-常用工具模块的更多相关文章
- 深度学习框架PyTorch一书的学习-第四章-神经网络工具箱nn
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 本章介绍的nn模块是构建与autogr ...
- 深度学习框架PyTorch一书的学习-第六章-实战指南
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter6-实战指南 希望大家直接到上面的网址去查看代码,下面是本人的笔记 将上面地 ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-2-autograd
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 torch.autograd就是为了方 ...
- 深度学习框架PyTorch一书的学习-第一/二章
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 pytorch的设计遵循tensor- ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-1-Tensor
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 Tensor Tensor可以是一个数 ...
- 深度学习框架PyTorch一书的学习-第七章-生成对抗网络(GAN)
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter7-GAN生成动漫头像 GAN解决了非监督学习中的著名问题:给定一批样本,训 ...
- 《深度学习框架PyTorch:入门与实践》的Loss函数构建代码运行问题
在学习陈云的教程<深度学习框架PyTorch:入门与实践>的损失函数构建时代码如下: 可我运行如下代码: output = net(input) target = Variable(t.a ...
- 《深度学习框架PyTorch:入门与实践》读书笔记
https://github.com/chenyuntc/pytorch-book Chapter2 :PyTorch快速入门 + Chapter3: Tensor和Autograd + Chapte ...
- 神工鬼斧惟肖惟妙,M1 mac系统深度学习框架Pytorch的二次元动漫动画风格迁移滤镜AnimeGANv2+Ffmpeg(图片+视频)快速实践
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_201 前段时间,业界鼎鼎有名的动漫风格转化滤镜库AnimeGAN发布了最新的v2版本,一时间街谈巷议,风头无两.提起二次元,目前国 ...
随机推荐
- 输出映射resultType
√1:简单类型 √2:简单类型列表 √3:POJO类型只有列名或列名的别名与POJO的属性名一致,该列才可以映射成功只要列名或列名的别名与POJO的属性名有一个一致,就会创建POJO对象如果列名或列名 ...
- jQuery中页面返回顶部的方法总结
当页面过长时,通常会在页面下方有一个返回顶部的button,总结一下,大概三种实现方法,下面说下各方法及优缺点. 方法一 锚点定位 ? 1 <a href="#" class ...
- loj#6033. 「雅礼集训 2017 Day2」棋盘游戏(二分图博弈)
题意 链接 Sol 第一次做在二分图上博弈的题..感觉思路真是清奇.. 首先将图黑白染色. 对于某个点,若它一定在最大匹配上,那么Bob必胜.因为Bob可以一直沿着匹配边都,Alice只能走非匹配边. ...
- 自定义控件详解(六):Paint 画笔MaskFilter过滤
首先看一个API:setMaskFilter(MaskFilter maskfilter): 设置MaskFilter,可以用不同的MaskFilter实现滤镜的效果,如滤化,立体等. 以下有两个Ma ...
- Android沉浸式状态栏的简单实现
随着卡片式设计在Android系统的上越来越流行,比如现在早已经烂大街的沉浸式状态栏,几乎所有的主流的APP都支持沉浸式状态栏,如QQ.UC浏览器等等.所以觉得有必要学习一下,找了点资料,总结了一下, ...
- git 入门教程之 git 私服搭建教程
git 私服搭建教程 前几节我们的远程仓库使用的是 github 网站,托管项目大多是公开的,如果不想让任何人都能看到就需要收费,而且 github 网站毕竟在国外,访问速度太慢,基于上述两点原因,我 ...
- Scrapy 为每一个Spider设置自己的Pipeline
settings中的ITEM_PIPELINES 通常我们需要把数据存在数据库中,一般通过scrapy的pipelines管道机制来实现.做法是,先在pipelines.py模块中编写Pipeline ...
- 账号配置vue版本的扫码下单以及对店铺进行装修的步骤
新版vue配置说明文档 管理员后台: 1.配置管理-店铺配置(子账号)-扫码点餐tab页-开启vue版 2.配置管理-店铺配置(主账号)-扫码点餐tab页-开通装修配置 商家后台: 1.主账号-门店设 ...
- 自动化测试基础篇--Selenium获取元素属性
摘自https://www.cnblogs.com/sanzangTst/p/8375938.html 通常在做断言之前,都要先获取界面上元素的属性,然后与期望结果对比. 一.获取页面title 二. ...
- wamp 中安装cakephp Fatal error: You must enable the intl extension to use CakePHP. in XXX
今天在wamp下安装cakephp3.x的时候,报出这么一条错误:Fatal error: You must enable the intl extension to use CakePHP. in ...