用于文本分类的多层注意力模型(Hierachical Attention Nerworks)
论文来源:Hierarchical Attention Networks for Document Classification
1、概述
文本分类时NLP应用中最基本的任务,从之前的机器学习到现在基于词表示的神经网络模型,分类准确度也有了很大的提升。本文基于前人的思想引入多层注意力网络来更多的关注文本的上下文结构。
2、模型结构
多层注意力网络(HAN)的结构如下图所示:

整个网络结构包括四个部分:
1)词序列编码器
2)基于词级的注意力层
3)句子编码器
4)基于句子级的注意力层
整个网络结构由双向GRU网络和注意力机制组合而成,具体的网络结构公式如下:
1)词序列编码器
给定一个句子中的单词 $w_{it}$ ,其中 $i$ 表示第 $i$ 个句子,$t$ 表示第 $t$ 个词。通过一个词嵌入矩阵 $W_e$ 将单词转换成向量表示,具体如下所示:
$ x_{it} = W_e; w_{it}$
接下来看看利用双向GRU实现的整个编码流程:
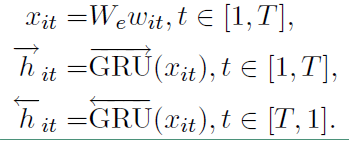
最终的 $h_{it} = [{\rightarrow{h}}_{it}, \leftarrow{h}_{it}]$ 。
2)词级的注意力层
注意力层的具体流程如下:
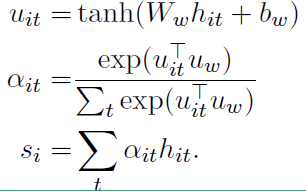
上面式子中,$u_{it}$ 是 $h_{it}$ 的隐层表示,$a_{it}$ 是经 $softmax$ 函数处理后的归一化权重系数,$u_w$ 是一个随机初始化的向量,之后会作为模型的参数一起被训练,$s_i$ 就是我们得到的第 $i$ 个句子的向量表示。
3)句子编码器
也是基于双向GRU实现编码的,其流程如下,
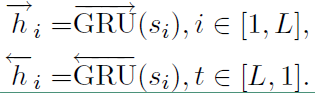
公式和词编码类似,最后的 $h_i$ 也是通过拼接得到的
4)句子级注意力层
注意力层的流程如下,和词级的一致
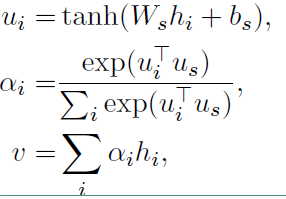
最后得到的向量 $v$ 就是文档的向量表示,这是文档的高层表示。接下来就可以用可以用这个向量表示作为文档的特征。
3、分类
直接用 $ softmax$ 函数进行多分类即可
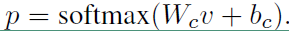
损失函数如下:
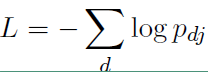
用于文本分类的多层注意力模型(Hierachical Attention Nerworks)的更多相关文章
- 用于文本分类的RNN-Attention网络
用于文本分类的RNN-Attention网络 https://blog.csdn.net/thriving_fcl/article/details/73381217 Attention机制在NLP上最 ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 将迁移学习用于文本分类 《 Universal Language Model Fine-tuning for Text Classification》
将迁移学习用于文本分类 < Universal Language Model Fine-tuning for Text Classification> 2018-07-27 20:07:4 ...
- 文本分类实战(六)—— RCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
目录 DAN(Deep Average Network) Fasttext fasttext文本分类 fasttext的n-gram模型 Doc2vec DAN(Deep Average Networ ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(四)—— Bi-LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(三)—— charCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- Java学习笔记之——单例模式
(1)懒汉式:对象在方法中,第一次调用时创建对象,线程不安全的 public class Singleton { //外部不可以创建对象,就要在内部创建一个对象,还能够在外部获取 private ...
- JavaScript有这几种测试分类
译者按: 也许你讨厌测试,但是你不得不面对它,所以至少区分一下单元测试.集成测试与功能测试?对吧… 原文: What are Unit Testing, Integration Testing and ...
- 2017 ACM-ICPC西安网赛B-Coin
B-Coin Bob has a not even coin, every time he tosses the coin, the probability that the coin's front ...
- laravel使用Schema创建数据表
1.简介 迁移就像数据库的版本控制,允许团队简单轻松的编辑并共享应用的数据库表结构,迁移通常和Laravel的schema构建器结对从而可以很容易地构建应用的数据库表结构.如果你曾经告知小组成员需要手 ...
- js 毫秒转天时分秒
formatDuring: function(mss) { var days = parseInt(mss / (1000 * 60 * 60 * 24)); var hours = parseInt ...
- layui table 表格模板按钮实例
这是个是全部的jsp 页面: <%@page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8& ...
- 2017-11-07 中文代码示例之Angular入门教程尝试
"中文编程"知乎专栏原址 原文: 中文代码示例教程之Angular尝试 为了检验中文命名在Angular中的支持程度, 把Angular官方入门教程的示例代码中尽量使用了中文命名. ...
- Mac上Homebrew的安装
Mac系统版本: 10.14.2 下载brew_install 访问:https://raw.githubusercontent.com/Homebrew/install/master/install ...
- web自动化 基于python+Selenium+PHP+Ftp实现的轻量级web自动化测试框架
基于python+Selenium+PHP+Ftp实现的轻量级web自动化测试框架 by:授客 QQ:1033553122 博客:http://blog.sina.com.cn/ishou ...
- Apktool(2)——使用前必须知道的apk知识
这里拿testapp.apk为例,如下图所示,左图为直接解压apk得到的文件,右图为apktool反编译得到的文件(反编译的使用在下一篇重点介绍) 图1 解压apk和反编译apk得到的文件目录对比 一 ...