论文阅读笔记二十二:End-to-End Instance Segmentation with Recurrent Attention(CVPR2017)

论文源址:https://arxiv.org/abs/1605.09410
tensorflow 代码:https://github.com/renmengye/rec-attend-public
摘要
卷积网络在像语义分割等结构预测任务中效果较好,但对于场景中不同实例个体分割仍存在一定的挑战性。实例分割有很多应用场景,比如,自动驾驶,图像捕捉,智能视频问答系统等。将大量的图形模型与低层次的可视化信息相结合用于实例分割。该文提出了一个端到端的带有注意力机制的RNN结构,来进行精细的实例分割。该网络顺序生成每个区域中的分割对象。
介绍
传统的语义分割无法指明图像中每个类别物体的个数。实例分割与之相比难度要大一些,因为实例分割需要区分相邻的,忽略的实例。在面向基于图像的机器理解的过程中进行实例分割也是十分重要的。实例分割的数据集有CityScapes。
对于实例分割,一种可行的方法是将其当作为一个结构输出问题。一个至关重要的问题是结构输出的维度。这个维度可以是目标物的个数乘以该物体的像素。标准的FCN网络很难将图像中的所有实例标记进行输出。进来有结合图形结构进行实例分割,但造成的结构过于复杂,同时需要消耗大量的时间,另外,这种方式无法进行端到端的训练。
像目标检测相似,重合也是实例分割中的一个主要挑战,为了自底向上的解决此问题,需要将两个互不相关的区域进行融合,对于小规模来说,这十分具有挑战性。使用NMS可以处理重合问题,但由于检测时会有大量的前景重叠,因此使用NMS可能会降低检测的效果。受此启发,本文使用一种递归方式来进行活动的NMS,对重合问题进行自上而下的分析。
一个相关问题是对一个图像中每个目标类别的实例个数进行统计。计数问题已经形成了一个特殊的任务设置,检测通过后接的回归进行实现,或者对一个计数误差标准进行区分度的学习。
为解决上述挑战,该文提出了一种基于RNN同时,利用注意力机制的新模型用于实例分割。该网络进行实例分割的同时,进行了计数操作。通过使用一个时间链,使一次只输出一个实例。执行动态的NMS,利用一个已经分割好的目标,用于辅助后续重合的目标物中。受人反复和专注的思想启发,使用基于RNN对一个实例进行分割。分割与计数进行联合训练可以使定义的循环网络的方程自动的进行停止操作。
循环注意力机制
本文主要包含四个部分:(1)external memory:捕捉分割物体的状态(2)box proposal network:负责对感兴趣的目标物体进行定位。(3)segmentation network:对box中的物体进行像素级的分类(分割)。(4)scoring network :决定一个实例是否被找到,同时决定何时进行停止操作。网络结构如下
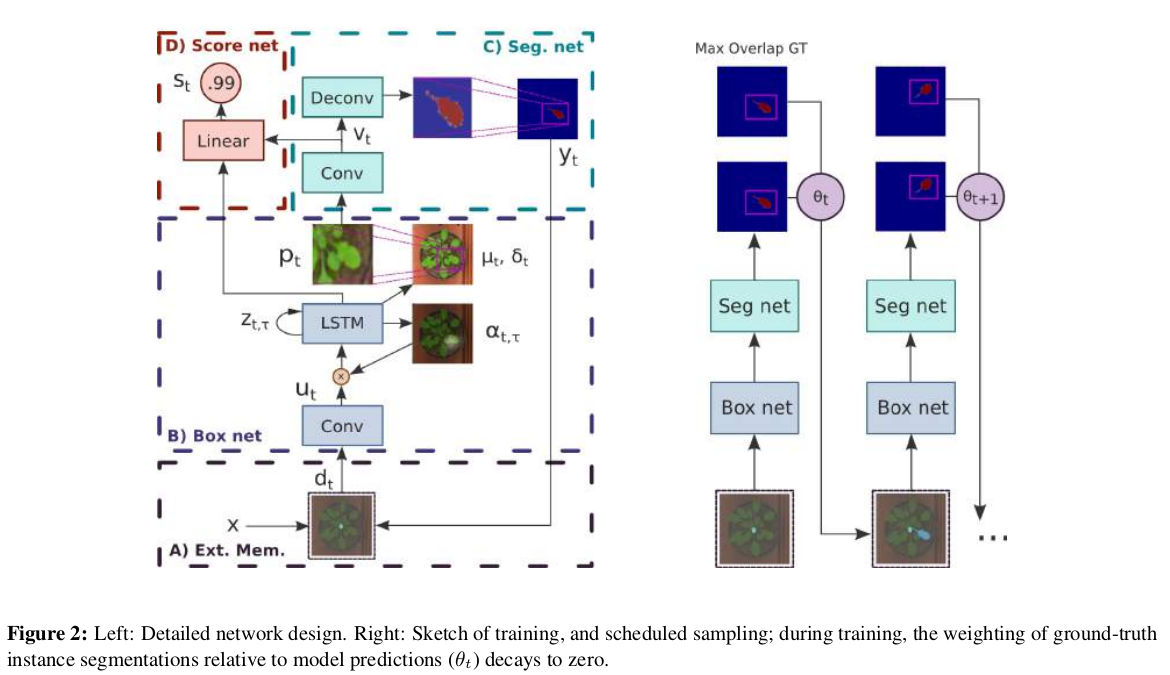
符号:

输入的预处理:
预训练一个FCN网络,包含两部分,(1)由一系列带跳跃结构的翻卷积网络生成的1通道的像素级前景分割结果。(2)对每个目标物体生成一个角度的map。对于每一个前景像素,计算其相对于物体中心的相关角度,同时,将角度量化为8个不同的类别,生成8个通道,如下图。对角度的预测可以增强模型对目标物边界细节信息的编码。预训练模型的输入为三通道的彩色图像,输出为9通道(1通道的前景+8通道的角度)

(1)External memory
为了在已分割的目标物决定下一个寻找的方向。该文结合external memory用于提供以前所有步骤得到的边界细节信息。该文假设完整的分割信息有助于网络分析目标物体重合的原因,同时,决定下一个感兴趣区域。feature map共计有10个通道,第一个通道用于添加基于先前操作产生的新的像素。其他通道用于保存输入图片。
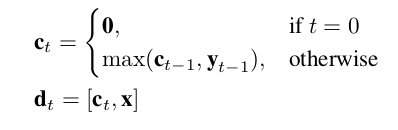
(2)Box network
该模块用于定位下一个感兴趣物体的位置。卷积网络输出一个大小为H'xW‘xL的feature map u_t,使用CNN对整副图像进行激活操作过于复杂,而且处理过程较为低效。简单的池化操作无法保存位置,该文选择动态池化操作来提取空间维度上的有用信息。通过增加一个权重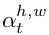 ,由于一次单向过程无法为上层网络提供足够的信息进而可以准确的将框画出,该文采用LSTM,每次输入一个维度为L的向量来观察不同位置的信息。所有位置的
,由于一次单向过程无法为上层网络提供足够的信息进而可以准确的将框画出,该文采用LSTM,每次输入一个维度为L的向量来观察不同位置的信息。所有位置的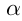 初始化为均匀分布。
初始化为均匀分布。
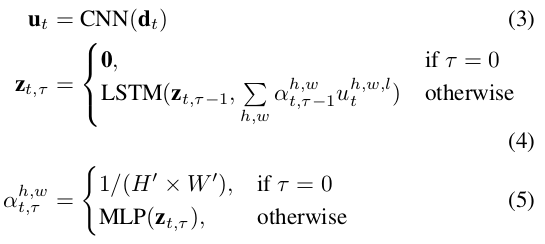
将LSTM的隐层状态送入一个线性网络层中用于预测框的坐标。将框参数化为:
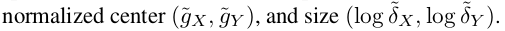
同时,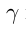 尺度因子也会被线性层进行预测,用于将patch恢复至原图大小。
尺度因子也会被线性层进行预测,用于将patch恢复至原图大小。
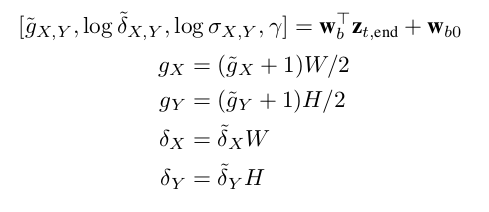
子区域的提取
该文参考DRAW采用高斯插值核从输入x中提取一个HxW的patch。同时,用d_t与原图进行拼接。该模型输出一个矩形框定位不同形状的目标物体。索引i,j代表HxW维度的patch。a,b代表原始图像的位置。Fx,Fy为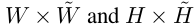 维度的矩阵,代表原图 (a,b)位置对提取的patch中(i,j)的作用大小。
维度的矩阵,代表原图 (a,b)位置对提取的patch中(i,j)的作用大小。
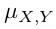 ,
,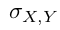 为由box network预测得到的高斯插值核的均值与方差。
为由box network预测得到的高斯插值核的均值与方差。
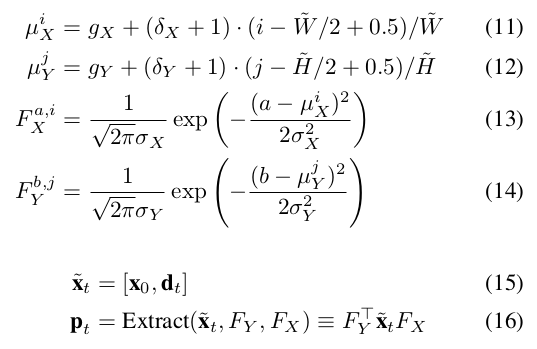
(3)Segmentation network
分割网络首先利用卷积网络生成一个feature map v_t,然后应用一个基于跳跃结构的翻卷积网络来进行上采样将低分辨率恢复至全部尺寸的分割结果。经过一个全卷积层,得到一个patch-level的分割预测热图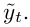 接着,利用计算得到的高斯核将预测的patch重新映射为原图,学习好的
接着,利用计算得到的高斯核将预测的patch重新映射为原图,学习好的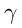 放大预测的框,常量
放大预测的框,常量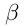 抑制框外的像素,用sigmoid函数产生0至1的分割值。
抑制框外的像素,用sigmoid函数产生0至1的分割值。
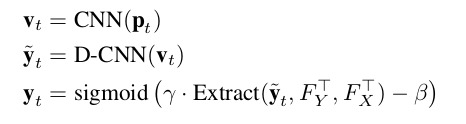
(4)Scoring network
为了得到图像中目标物体的个数,同时为了完成序列化处理过程,该文增加了一个scoring network。该文中的score 模型提取box network 和segmentation network中隐层状态的信息,来产生一个0至1的分数。
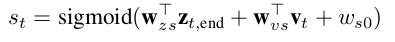
终止条件:该文整个模型的训练的序列长度为目标物体最大数量加1。进行inference时,当输出的score 降到0.5时就结束迭代过程。同时,损失函数有利于scores的降低。
损失函数
总的损失为三个损失分支的和:(1)分割IoU loss Ly(2)box IoU loss Lb(3)分数交叉熵损失Ls 在实验中将损失相关系数固定为1。
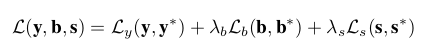
(a)匹配IoU损失(mIoU)实例分割的一个主要挑战,是模型的预测输出与实例ground truth的匹配。该文通过最大化权重进行预测与ground truth的二分图匹配。通过匹配方法,可以使损失函数对ground-truth的实例不敏感。不同于直接惩罚假正与假反的分割方法,本文的匹配权重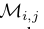 为一对分割结果IoU的分数。通过Hungarian算法进行计算得到matching。通过此算法并不需要反向传播来优化此网络。
为一对分割结果IoU的分数。通过Hungarian算法进行计算得到matching。通过此算法并不需要反向传播来优化此网络。

(b)Soft box IoU loss:虽然可以根据生成的框的四个坐标中推出准确的IoU的值。但若两个框不重复,则其梯度就会消失。不利于基于梯度下降法的学习。该文提出了一个较宽松的box IoU。同样利用高斯核将一个patch重新映射原始的大小。对框的ground truth 进行padding,通过匹配预测得到的框与padding 后的ground truth进行匹配得到mIoU。匹配到的ground truth 在宽和高上进行缩放操作。
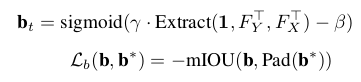
(c)monotonic score loss:为了满足可以自行停止迭代操作。网络首先应该输出更多确信的目标物。该文设计一个损失函数促进score的降低。score为1的迭代与先前的下界进行比较,而0的会与接下来score的上界进行比较。
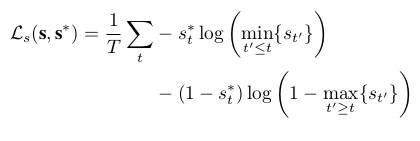
训练过程
Booststrap training:box与segmentation网络以来彼此的输出来决定下一时间段的动作。针对这两个网络的本质的特点:该文提出了一个bootstrap 训练方法:先使用分割与box的ground truth对网络分开进行预训练。后期,将ground truth替换为模型预测的数值。
Scheduled sampling:为了平滑各个阶段之间输出的变化,提出了scheduled sampling。在网络的输入阶段,渐渐的将ground truth移除。在训练时,外部存储结构中的输入有一个随即开关,利用与ground truth 或者前阶段网络的输出中匹配最大的部分进行实例分割。在训练的结束阶段,整个模型完全依赖于来自前几步的输出。与预测过程相同。
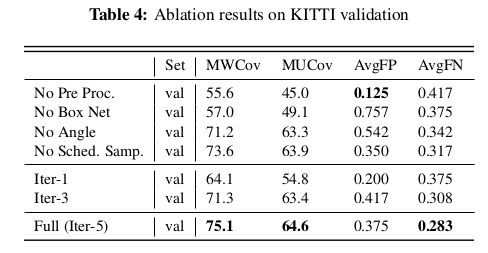
实验
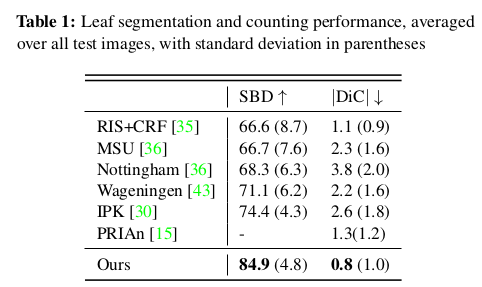
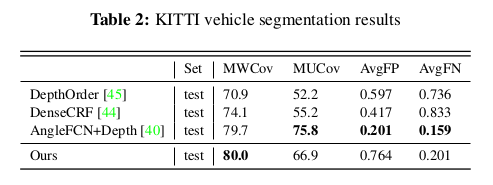
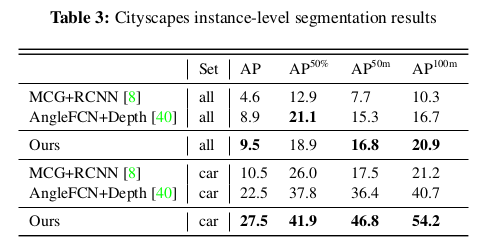



Reference
[1] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L.Zitnick, and D. Parikh. VQA: Visual question answering. In ICCV, 2015. 1
[2] M. Bai and R. Urtasun. Deep watershed transform for instance segmentation. CoRR, abs/1611.08303, 2016. 5
[3] D. Banica and C. Sminchisescu. Second-order constrained parametric proposals and sequential search-based structured prediction for semantic segmentation in RGB-D images. In
CVPR, 2015. 5
论文阅读笔记二十二:End-to-End Instance Segmentation with Recurrent Attention(CVPR2017)的更多相关文章
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )
论文原址:https://arxiv.org/pdf/1409.4842.pdf 代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4) ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- 论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)
论文原址:https://arxiv.org/abs/1707.02921 代码: https://github.com/LimBee/NTIRE2017 摘要 以DNN进行超分辨的研究比较流行,其中 ...
- 论文阅读笔记三十九:Accurate Single Stage Detector Using Recurrent Rolling Convolution(RRC CVPR2017)
论文源址:https://arxiv.org/abs/1704.05776 开源代码:https://github.com/xiaohaoChen/rrc_detection 摘要 大多数目标检测及定 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记三十六:Mask R-CNN(CVPR2017)
论文源址:https://arxiv.org/pdf/1703.06870.pdf 开源代码:https://github.com/matterport/Mask_RCNN 摘要 Mask R-CNN ...
随机推荐
- Microsoft SQL - 操作语句
操作语句(Operation Statement) 操作数据库 创建数据库 关键字:create database 用于创建各种数据库对象(数据库.表.触发器.存储过程等) 格式如:create &l ...
- setInterval 传值设参数
<script type="text/javascript" > window.onload=function(){ for(var i=1;i<3;i++){ ...
- TCP通信实现对接硬件发送与接收十六进制数据 & int与byte的转换原理 & java中正负数的表示
今天收到的一份需求任务是对接硬件,TCP通信,并给出通信端口与数据包格式,如下: 1.首先编写了一个简单的十六进制转byte[]数组与byte[]转换16进制字符串的两个方法,如下: /** * 将十 ...
- Pycharm 2018 Activation code 在线激活
1. 下载官方 pycharm https://www.jetbrains.com/pycharm/download/ 2. 点击获取激活码 点击获取激活码 2.1 打开 hosts 文件 2.2 ...
- 无线桥接(WDS)如何设置?
一.WDS使用介绍 无线桥接(WDS)可以将多台无线路由器通过无线方式互联,从而将无线信号扩展放大.无线终端在移动过程中可以自动切换较好的信号,实现无线漫游. 本文指导将TL-WR740N当作副路由器 ...
- linux系统常用运维命令
目录/文件处理命令 mkdir dirname 创建文件夹 mkdir -p /tmp/a/b 递归创建目录 rm -rf dirname 删除目录及内 ...
- Unity3D ParticleSystem粒子系统
粒子系统检视面板 点击粒子系统检视面板的右上角的"+"来增加新的模块.(Show All Modules:显示全部) 初始化模块: 持续时间(Duration):粒子系统发射粒子的 ...
- 防火墙iptables的简单使用
规则定义 # service iptables start # chkconfig iptables on 想让规则生效,则shell命令行下执行 sh /bin/iptables.sh即可 [roo ...
- 缓存系列之五:通过codis3.2实现redis3.2.8集群的管理
通过codis3.2实现redis3.2.8集群 一:Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没 ...
- Golang -- Signal处理
我们在生产环境下运行的系统要求优雅退出,即程序接收退出通知后,会有机会先执行一段清理代码,将收尾工作做完后再真正退出.我们采用系统Signal来 通知系统退出,即kill pragram-pid.我们 ...