集合之LinkedHashSet(含JDK1.8源码分析)
一、前言
上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的。
二、linkedHashSet的数据结构
因为linkedHashSet的底层是基于linkedHashMap实现的,所以linkedHashSet的数据结构就是linkedHashMap的数据结构,因为前面已经分析过了linkedHashMap的数据结构,这里不再赘述。集合之LinkedHashMap(含JDK1.8源码分析)。
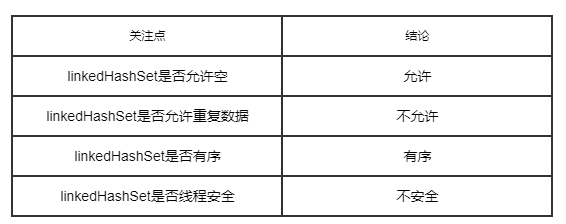
四个关注点在linkedHashSet上的答案
三、linkedHashSet源码分析-属性及构造函数
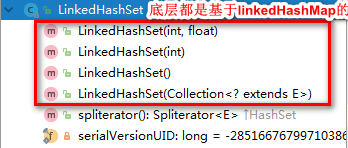
3.1 类的继承关系
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
说明:继承HashSet,实现了Set接口,其内定义了一些共有的操作。
3.2 类的属性
由上图可知,除了本身的序列号,linkedHashSet并没有定义一些新的属性,其属性都是继承自hashSet。
3.3 类的构造函数
说明:如上图所示,linkedHashSet的四种构造函数都是基于linkedHashMap实现的,这里列出一种,其它几种也是一样。
/**
* Constructs a new, empty linked hash set with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity of the linked hash set
* @param loadFactor the load factor of the linked hash set
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
通过super调用父类hashSet对应的构造函数,如下:
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
四、linkedHashSet源码分析-核心函数
linkedHashSet的add方法,contains方法,remove方法等等都是继承自hashSet的,也是基于hashMap实现的,只是一些细节上还是基于linkedHashMap实现而已,前面已经分析过,这里不再赘述。
举例:
public class Test {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("zs");
linkedHashSet.add("ls");
linkedHashSet.add("ww");
linkedHashSet.add("zl");
linkedHashSet.add(null);
linkedHashSet.add("zs");
System.out.println(linkedHashSet);
boolean zs1 = linkedHashSet.remove("zs");
System.out.println("删除zs===" + zs1);
System.out.println(linkedHashSet);
boolean zs = linkedHashSet.contains("zs");
System.out.println("是否包含zs===" + zs);
}
}
结果:可见,linkedHashSet允许空值,不允许重复数据,元素按照插入顺序排列。
[zs, ls, ww, zl, null]
删除zs===true
[ls, ww, zl, null]
是否包含zs===false
五、总结
可见,linkedHashSet是与linkedHashMap相对应的,分析完linkedHashMap再来看linkedHashSet就很简单了。
集合之LinkedHashSet(含JDK1.8源码分析)的更多相关文章
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- 集合之HashMap(含JDK1.8源码分析)
一.前言 之前的List,讲了ArrayList.LinkedList,反映的是两种思想: (1)ArrayList以数组形式实现,顺序插入.查找快,插入.删除较慢 (2)LinkedList以链表形 ...
- 集合之LinkedList(含JDK1.8源码分析)
一.前言 LinkedList是基于链表实现的,所以先讲解一下什么是链表.链表原先是C/C++的概念,是一种线性的存储结构,意思是将要存储的数据存在一个存储单元里面,这个存储单元里面除了存放有待存储的 ...
- 集合之ArrayList(含JDK1.8源码分析)
一.ArrayList的数据结构 ArrayList底层的数据结构就是数组,数组元素类型为Object类型,即可以存放所有类型数据.我们对ArrayList类的实例的所有的操作(增删改查等),其底层都 ...
- 集合之TreeMap(含JDK1.8源码分析)
一.前言 前面所说的hashMap和linkedHashMap都不具备统计的功能,或者说它们的统计性能的时间复杂度都不是很好,要想对两者进行统计,需要遍历所有的entry,时间复杂度比较高,此时,我们 ...
- 集合之LinkedHashMap(含JDK1.8源码分析)
一.前言 大多数的情况下,只要不涉及线程安全问题,map都可以使用hashMap,不过hashMap有一个问题,hashMap的迭代顺序不是hashMap的存储顺序,即hashMap中的元素是无序的. ...
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
随机推荐
- [BJOI2015]树的同构
嘟嘟嘟 判断树的同构的方法就是树上哈希. 如果树是一棵有根树,那么只要从根节点出发dfs,每一个节点的哈希值等于按传统方式算出来的子树的哈希值的结果.需要注意的是,算完子树的哈希值后要先排序再加起来, ...
- P1897 电梯里的爱情
简单模拟: 没什么好说的,因为范围比较水,所以直接按题意直接模拟1就好 #include<iostream> using namespace std; #define ll long lo ...
- [MicroPython]TPYBoard智能小车“飞奔的TPYBoard装甲一号”
智能小车作为现代的新发明,是以后的发展方向,他可以按照预先设定的模式在一个环境里自动的运作,不需要人为的管理,可应用于科学勘探等等的用途.智能小车能够实时显示时间.速度.里程,具有自动寻迹.寻光.避障 ...
- Angularjs 过滤器使用
Filter:格式化数据 // HTML表达式: {{ filter_expression | filter : expression : comparator}} // JS表达式: $filt ...
- 【php增删改查实例】第二十四节 - 文件上传在项目中的具体应用
文件上传在项目中,一般有两个用武之地,分别为设置用户的头像和上传附件.本节我们演示如果进行用户头像的上传. 因为一个用户单独并且唯一对应了一个头像,是一对一的关系,所以我们需要去给tm_users表添 ...
- Ansible 简介
Ansible 是一个开源的基于 OpenSSH 的自动化配置管理工具.可以用它来配置系统.部署软件和编排更高级的 IT 任务,比如持续部署或零停机更新.Ansible 的主要目标是简单和易用,并且它 ...
- Google 宣布在 4 月 1 日关闭站内搜索
今春,Google 计划终止又一项产品,它就是“站内搜索”(Site Search)功能.这项产品主要出售给 web 出版商,让它们可以在自家网站内运用业内领先的搜索技术.虽然该公司并未公开宣布此事, ...
- Flask的蓝图和红图
1.蓝图 对于简单的项目来说,比如项目就只有一个user模块,我们可以都将视图函数定义在一个文件里面,不需要用到蓝图. 但是如果我们的项目有多个模块,如下有v1模块,v2模块.....等,那么如果我们 ...
- HDU - 1166 - 敌兵布阵 线段树的单点修改,区间求和
#include<iostream> #include<stdio.h> #include<string.h> #include<algorithm> ...
- CF每日一练 Codeforces Round #520 (Div. 2)
比赛过程总结:过程中有事就玩手机了,后面打的状态不是很好,A题理解错题意,表明了内心不在状态,B题想法和思路都是完全正确的,但是并没有写出来,因为自己代码能力不强,思路不是特别清晰,把代码后面写乱了, ...