scrapy暂停和重启,及url去重原理,telenet简单使用
一.scrapy暂停与重启
1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息:
scrapy crawl spider_name -s JOBDIR=dir/001——spider_name是你要爬取得spider的py文件名,JOBDIR是命令参数,即代表存放位置参数,dir是中间信息要保存的目录,001新生成的文件夹名是保存的中间信息,重启则读取该文件信息。可以将JOBDIR 设置在setting中,或写在custom_settings中,在Pycharm中都会执行,但是在Pycharm中无法发送ctrl+c,即无法将进程放入后台并暂停。
2.执行命令:scrapy crawl jobbole -s JOBDIR=jobs/001
2.1有可能会报以下错误,这是因为未进入到项目目录(crawl会搜索scrapy.cfg文件):

2.2进入目录正常运行后,ctrl+c暂停进程:
会在jobs下生成一个001文件夹生成如下图文件,request.seen是保存的已经访问了的url,spider.state是spider的状态信息,request.queue中有active.json和p0两个文件,p0是还需要继续做的request(跑完该文件就没有了)


3.重启(也是执行scrapy crawl jobbole -s JOBDIR=jobs/001):
会读取相关信息并继续执行,p0文件会减小,request.seen文件会增大(读取新的request,存入url),两次ctrl+c强制关掉,若需从新爬则可以指定新的文件夹,如jobs/002.
二.scrapy去重原理
对于每一个url的请求,调度器都会根据请求得相关信息加密(request_fingerprint)得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。
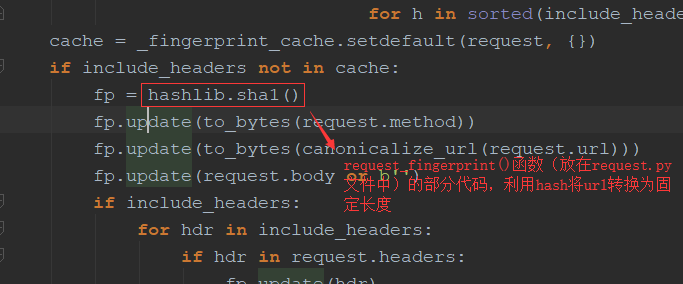

三.telnet的简单使用
1.telnet简介:
Scrapy配有内置的telnet控制台,用于检查和控制Scrapy运行过程。telnet控制台只是在Scrapy进程中运行的常规python shell,所以你可以从中做任何事情。
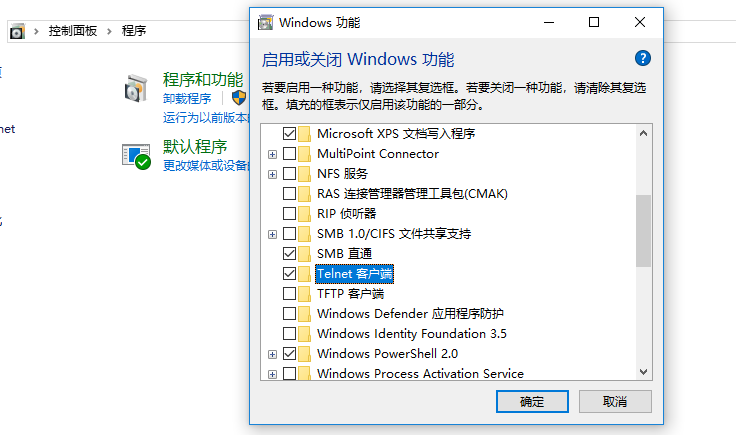
2.windows打开telnet客户端和服务端:
3.telenet连接:
telnet控制台侦听TELNETCONSOLE_PORT设置中定义的TCP端口 ,默认为6023,如下:
telenet localhost 6023
4.telenet简单使用(相当于一个python终端):
变量:

scrapy暂停和重启,及url去重原理,telenet简单使用的更多相关文章
- scrapy 爬虫的暂停与重启
暂停爬虫项目 首先在项目目录下创建一个文件夹用来存放暂停爬虫时的待处理请求url以及其他的信息.(文件夹名称:job_info) 在启动爬虫项目时候用pycharm自带的终端启动输入下面的命令: sc ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取 实现暂停与重启记录状态 1.首先cd进入到scrapy项目里 2.在scrapy项 ...
- 【转】larbin中的url去重算法
1.bloom filter算法 传说中,larbin使用bloom filter算法来进行url去重.那我们就先来了解下bloom filter算法好了. [以下转自:http://hi.baidu ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- 爬虫URL去重
这个要看你想抓取的网页数量是哪种规模的.如果是千万以下用hash表, set, 布隆过滤器基本可以解决,如果是海量的......嗯我也没做过海量的,不过hash表之类的就别想了,内存根本不够,分割线下 ...
- URL去重与文章去重的一些基本方法
一.url去重url存到数据库所有url放到set中(一亿条占用9G内存)md5之后放到set中(一亿条占用2,3G的内存)scrapy采用的就是类似方法bitmap方法(url经过hash后映射到b ...
- URL 去重的 6 种方案!(附详细实现代码)
URL 去重在我们日常工作中和面试中很常遇到,比如这些: 可以看出,包括阿里,网易云.优酷.作业帮等知名互联网公司都出现过类似的面试题,而且和 URL 去重比较类似的,如 IP 黑/白名单判断等也经常 ...
- [爬虫学习笔记]基于Bloom Filter的url去重模块UrlSeen
Url Seen用来做url去重.对于一个大的爬虫系统,它可能已经有百亿或者千亿的url,新来一个url如何能快速的判断url是否已经出现过非常关键.因为大的爬虫系统可能一秒钟就会下载 ...
随机推荐
- [TJOI2014]拼图
嘟嘟嘟 一眼看上去像状压dp,然后越想复杂度越不对劲,最后发现和爆搜差不多,索性就写爆搜了,复杂度\(O(\)能过\()\). 别忘了填拼图和回溯的时候只动拼图中是1的部分,不要把\(n * m\)的 ...
- 【转】iOS 音频-AVAudioSession
1. AVAudioSession 概述 最近一年一直在做IPC Camera的iOS客户端开发.和音频打交道,必须要弄清楚 AVAudioSession. 先看下苹果的官方图: Audio Se ...
- MYSQL学习笔记——sql语句优化工具
优化sql:思路: 使用explan->先查询type类型看看是all还是ref,然后判断 possible_keys (显示可能应用在这张表中的索引, 一个或多个.查询涉及到的字段是若存在索引 ...
- 004_centos安装pip的几种方式及pip源
一. (1) yum -y install epel-release yum install python-pip pip install --upgrade pip (2) python脚本的一键安 ...
- (三)JavaScript 语法
字符串(String)字面量 可以使用单引号或双引号: "John Doe" 'John Doe' 数组(Array)字面量 定义一个数组: [40, 100, 1, 5, 25, ...
- [TPYBoard - Micropython之会python就能做硬件 6] 学习使用OLED显示屏
转载请注明:@小五义 http://www.cnblogs.com/xiaowuyi 欢迎加入讨论群 64770604 一.实验器材 1.TPYBoard板子一块 2.数据线一条 ...
- Mybatis学习总结(九)——查询缓存
一.什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能.mybaits提供一级缓存和二级缓存. 1.一级缓存是sqlSession级别的缓存.在操作数据库时需要构造sqlSe ...
- 用 Django 管理现有数据库
在多数项目中,总有一些几乎一成不变的 CRUD 操作,编写这些代码很无聊,但又是整个系统必不可少的功能之一.我们在上一个项目中也面临类似的问题,虽然已经实现了一个功能相对完整的管理后台,也尽量做到了代 ...
- 【C#复习总结】垃圾回收机制(GC)2
理解C#垃圾回收机制我们首先说一下CLR(公共语言运行时,Common Language Runtime)它和Java虚拟机一样是一个运行时环境,核心功能包括:内存管理.程序集加载.安全性.异步处理和 ...
- .NET-记一次架构优化实战与方案-底层服务优化
目录 .NET-记一次架构优化实战与方案-梳理篇 .NET-记一次架构优化实战与方案-前端优化 .NET-记一次架构优化实战与方案-底层服务优化 前言 经过上一篇<.NET-记一次架构优化实战与 ...