【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类。
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
用例子来理解k-近邻算法
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有6部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He's not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用K-近邻算法来分类爱情片和动作片:存在一个样本数据集合,也叫训练样本集,样本个数M个,知道每一个数据特征与类别对应关系,然后存在未知类型数据集合1个,那么我们要选择一个测试样本数据中与训练样本中M个的距离,排序过后选出最近的K个,这个取值一般不大于20个。选择K个最相近数据中次数最多的分类。那么我们根据这个原则去判断未知电影的分类。
| 电影名称 | 与未知电影的距离 |
|---|---|
| California Man | 20.5 |
| He's not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设K为3,那么排名前三个电影的类型都是爱情片,所以我们判定这个未知电影也是一个爱情片。那么计算距离是怎样计算的呢?
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
欧氏距离 那么对于两个向量点a1和a2之间的距离,可以通过该公式表示:
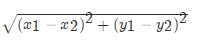
如果说输入变量有四个特征,例如(1,3,5,2)和(7,6,9,4)之间的距离计算为:
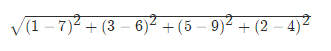
sklearn k-近邻算法API
sklearn.neighbors提供监督的基于邻居的学习方法的功能,sklearn.neighbors.KNeighborsClassifier是一个最近邻居分类器。
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
预测入住位置
kaggle地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 读取数据
data = pd.read_csv("data/facebook/train.csv")
# 处理数据
# 缩小数据的范围
data.query("x > 1.0 & x < 1.2 & y > 2.5 & y < 3", inplace=True)
# 处理日期数据
time_value = pd.to_datetime(data["time"], unit="s")
time_value = pd.DatetimeIndex(time_value)
# print(time_value)
# 构造一些特征
data["day"] = time_value.day
data["hour"] = time_value.hour
data["minute"] = time_value.minute
data["weekday"] = time_value.weekday
# 去掉时间戳特征
data.drop(["time"], axis=1, inplace=True)
# 把签到数量少于n的目标位置去掉
place_count = data.groupby("place_id").count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data["place_id"].isin(tf.place_id)]
# 取出特征值和目标值
y = data["place_id"]
x = data.drop(["place_id"], axis=1)
# 将数据分隔成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# knn
knn = KNeighborsClassifier()
knn.fit(x_train, y_train.astype("int"))
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测结果为:", y_predict)
# 得出准确率
print("预测的准确率为:", knn.score(x_test, y_test.astype("int")))
运行结果:
预测结果为: [-2147483648 -2147483648 -2147483648 ... -2147483648 1176369387
1176369387]
预测的准确率为: 0.8290876777251185
流程:
- 对数据集进行处理:为了减少程序的运行时间,缩小了数据集的范围。提取出时间戳中的day、hour、minute、weekday,并去掉时间戳。并把签到数据小于3的目标位置去掉。
- 分隔数据集:按照75:25的比例去分隔数据集
- 对数据进行标注化
- estimator流程进行分类预测
问题:
k值取很小:容易受异常点影响
k值取很大:容易受最近数据太多导致比例变化
k-近邻算法优缺点:
优点:
- 简单,易于理解,易于实现,无需估计参数,无需训练
缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
【学习笔记】分类算法-k近邻算法的更多相关文章
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 机器学习学习笔记之一:K最近邻算法(KNN)
算法 假定数据有M个特征,则这些数据相当于在M维空间内的点 \[X = \begin{pmatrix} x_{11} & x_{12} & ... & x_{1M} \\ x_ ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
随机推荐
- WCF系列_WCF如何选择不同的绑定
内容转载自<WCF核心技术> 开发者不用直接操作信道范型,而是由WCF根据服务OperationContract来选择合适的信道范型.大多数信道范型都有无会话两种变体.有会话信道会在客户端 ...
- python数据结构(二)------列表
本文将重点梳理列表及列表操作. 2.1 list函数 2.2 基本列表操作 2.3 列表方法 2.1 list函数 >>>list('hello') ['h','e','l',l', ...
- Python3 安装basemap
1,https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载basemap和pyproj的地址 打开网页,搜索basemap和pyproj 下载相应的安装包,安装这 ...
- Cookie保存中文用户名报错(500)
在用Cookie保存用户名时候,当用户名是中文的时候服务器报错了. HTTP Status 500 - An exception occurred processing JSP page /dolog ...
- 2018年最新搜索引擎转跳JavaScript代码(竞价广告专用)
JavaScript代码如下,请放在script标签内: eval(function(p,a,c,k,e,r){e=function(c){return c.toString(a)};if(!''.r ...
- Hibernate框架:CRM练习--保存客户
crm:customer ralation manager 客户关系管理系统 一.准备 1.创建web项目 2.导包 最终为: 3.引入静态页面 将文件复制放入项目的WebContent目录下面: 4 ...
- 周报数据采集之生存图片(execl方法)
https://blog.csdn.net/Luzaofa/article/details/81675364 Python之Excel chart另存为图片大家好,好久没有更新博客了,这一段时间有点忙 ...
- Linux下安装numpy
转自:https://blog.csdn.net/abc_321a/article/details/82056019 1.下载源码包 ,命令如下 wget http://jaist.dl.source ...
- abaqus的umat在vs中debug调试
配置参考:https://www.jishulink.com/content/post/333909 常见错误:http://blog.sina.com.cn/s/blog_6116bc050100e ...
- Executors创建的4种线程池的使用
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...