scrapy 爬取糗事百科
- 安装scrapy
conda install scrapy
- 创建scrapy项目
scrapy startproject qiubai
- 启动pycharm,发现新增加了qiubai这个目录
- 在spider目录下创建indexpage.py文件
- 编写糗百爬虫,获取首页的所有作者信息
#导入scrapy
import scrapy #创建糗百爬虫类
class QiuBaiSpider(scrapy.Spider):
#定义爬虫的名字
name = 'qiubai'
#定义爬虫开始的URL
start_urls=['http://www.qiushibaike.com/',] #处理爬取的信息
def parse(self, response):
li=response.xpath('//div[@class="author clearfix"]/a[2]/h2/text()').extract()
#li=response.xpath("//h2/text()").extract()
for item in li:
print item
- 在和scrapy.cfg同级的目录下创建manage.py
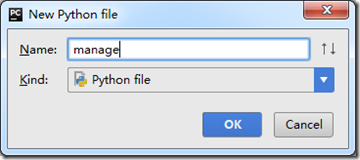
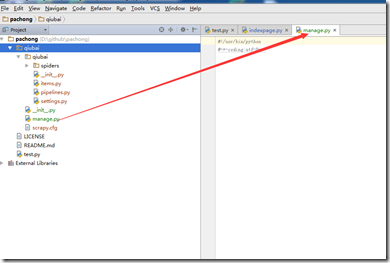
输入代码
from scrapy.cmdline import execute execute()
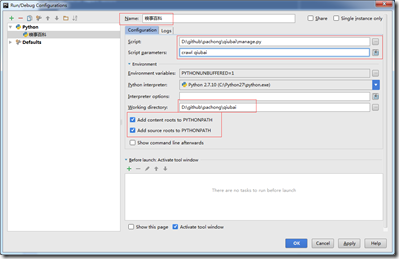
- 配置运行参数
- 查看本机useragent http://whatsmyuseragent.com/
- 在settings.py中设置USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36'
- 运行爬虫
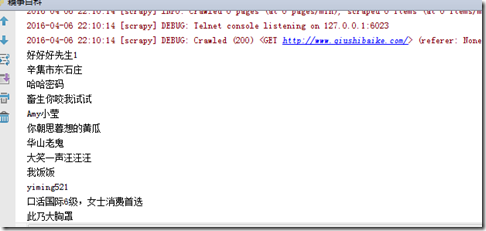
scrapy 爬取糗事百科的更多相关文章
- python爬虫29 | 使用scrapy爬取糗事百科的例子,告诉你它有多厉害!
是时候给你说说 爬虫框架了 使用框架来爬取数据 会节省我们更多时间 很快就能抓取到我们想要抓取的内容 框架集合了许多操作 比如请求,数据解析,存储等等 都可以由框架完成 有些小伙伴就要问了 你他妈的 ...
- 爬虫--使用scrapy爬取糗事百科并在txt文件中持久化存储
工程目录结构 spiders下的first源码 # -*- coding: utf- -*- import scrapy from firstBlood.items import Firstblood ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python学习(十六)写爬虫爬取糗事百科段子
原文链接:爬取糗事百科段子 利用前面学到的文件.正则表达式.urllib的知识,综合运用,爬取糗事百科的段子先用urllib库获取糗事百科热帖第一页的数据.并打开文件进行保存,正好可以熟悉一下之前学过 ...
- 16-多线程爬取糗事百科(python+Tread)
https://www.cnblogs.com/alamZ/p/7414020.html 课件内容 #_*_ coding: utf-8 _*_ ''' Created on 2018年7月17日 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
随机推荐
- 【爬虫】在使用xpath时,排除指定标签
xpath排除某个节点 主要时应用name()这个函数获取便签名 res = html.xpath("//*[name(.)!='style']")
- Javascript数组系列二之迭代方法1
我们在<Javascript数组系列一之栈与队列 >中介绍了一些数组的用法.比如:数组如何表现的和「栈」一样,用什么方法表现的和「队列」一样等等一些方法,因为 Javascript 中的数 ...
- 探索SQL Server元数据(三):索引元数据
背景 在第一篇中我介绍了如何访问元数据,元数据为什么在数据库里面,以及如何使用元数据.介绍了如何查出各种数据库对象的在数据库里面的名字.第二篇,我选择了触发器的主题,因为它是一个能提供很好例子的数据库 ...
- 转:Redis 使用经验总结
转自:Redis 总结精讲 看一篇成高手系统-4 本文围绕以下几点进行阐述 1.为什么使用redis2.使用redis有什么缺点3.单线程的redis为什么这么快4.redis的数据类型,以及每种数据 ...
- vim 基础命令大全
VIM命令大全 光标控制命令 命令 光标移动h 向左移一个字符j 向下移一行k ...
- docker:版本变更
在2017年之前的版本号: v1.4, v1.5, v1.6, v1.7, v1.8, v1.9, v1.10, v1.11, v1.12, v1.13 从2017年开始版本后变更为:${yy} ...
- Win10家庭版-添加[组策略]
win10家庭版有很多功能都不能用,这一次就碰到了一个找不到‘组策略’的问题,在网上搜索到了一个方法,记录一下: 新建一个txt,将下面内容复制到文本中: =====分隔符====== @echo o ...
- appium+robotframework常见技巧总结
1.如何输入中文 方法: 在open application参数最后,新增unicodeKeyboard=True resetKeyboard=True:不加入这两个参数时,中文无法输入 2.如 ...
- 异常--finally关键字
finally定义: finally{}代码块中的代码是一定会执行的,一般用来关闭资源或者一些必须执行的代码,如数据库连接的关闭
- 基于python的Selenium使用小结
之前介绍过基于Unittest和TestNG自动化测试框架,然而基于Web端的测试的基础框架是需要Selenium做主要支撑的,这里边给大家介绍下Web测试核心之基于Python的Selenium 一 ...