Kafka技术内幕 读书笔记之(二) 生产者——新生产者客户端
消息系统通常由生产者(producer )、 消费者( consumer )和消息代理( broker ) 三大部分组成,生产者会将消息写入消息代理,消费者会从消息代理中读取消息 。
对于消息代理而言,生产者和消费者都属于客户端:生产者和消费者会发送客户端请求给服务端,服务端的处理分别是存储消息和获取消息,最后服务端返回响应结果给客户端。
这里主要分析新旧两个版本的生产者客户端,以及服务端的网络连接实现。
新生产者客户端
Kafka初期使用 Sca la编写 。 最新的客户端使用了 Java重新实现
新的生产者应用程序使用 KafkaProducer对象代表一个生产者客户端进程。 生产者要发送消息,并不是直接发送给服务端 ,而是先在客户端把消息放入队列中,
然后由一个消息发送线程从队列中拉取消息,以批量的方式发送消息给服务端。 Kafka的记录收集器( RecordAccumulator)负责缓存生产者
客户端产生的消息,发送线程( Sender )负责读取记录收集器的批量消息 , 通过网络发送给服务端。
KafkaProducer可以完成同步和异步两种模式的消息发迭, send方法返回的是一个 Future。
同步调用 send返回Future时, 需要立即调用get ,因为Future.get在没有返回结果时会一直阻塞。
异步提供一个回调,调用 send后可以继续发送消息而不用等待 。 当有结果运回时,会向动执行回调函数。
生产者客户端对象KafkaProducer send方法的处理逻辑是 : 首先序列化消息的 key和value (消息必须序列化成二进制流的形式才能在网络中传输),
然后为每一条消息选择对应的分区(表示要将消息存储至Kafka集群的哪个节点上),最后通知发送线程发送消息 。
Kafka的一个主题会有多个分区,分区作为并行任务的最小单位,消息选择分区根据消息是存含有键来判断。没有键的消息会采用round-robin方式,均衡地分发到不同的分区 。
如果指定了消息的键,为消息选择分区的算法是:对键进行散列化后,再与分区的数量-取模运算得到分区编号 。
1. 为消息选择分区
默认情况下主题的分区数量只有一个 。 一个主题只有一个分区时,会导致同一个主题的所有消息都只会保存到一个节点上。 一般要提前创建主题,指定更多
的分区数,这样同一个主题的所有消息就会分散在不同的节点上 。
Kafka通过将主题分成多个分区的语义来实现并行处理,生产者可以将一批消息分成多个分区,每个分区写入不同的服务端节点 。
如图所示,消息集的每条消息都会选择一个分区编号,不同的分区可以同时向分区的主副本节点发送生产请求 。 生产者客户端采用这种分区并行发送的方式,提
升生产者客户端的写入性能。 分区对消费者也有好处 , 消费者指定获取一个主题的消息,它也可以同时从多个分区读取消息,提升消费者客户端的读取性能。

如图 所示,假设Topic1主题有4个分区。一个分区有多个副本,灰色矩形表示主副本 , 白色矩形表示备份副本,备份副本的数据会和主副本保持同步 。
假设分区P4 还没有选举出主副本,那么没有键的消息不会被分配到分区P4 。 选择分区时,计数器是递增的,第一条消息写到分区P1,第二条消息写到分区P2,第三条写到分
区P3,第四条又会写到分区P1, 以此类推 。 只有分区P4可用了,新的消息才会写到分区P4上 。
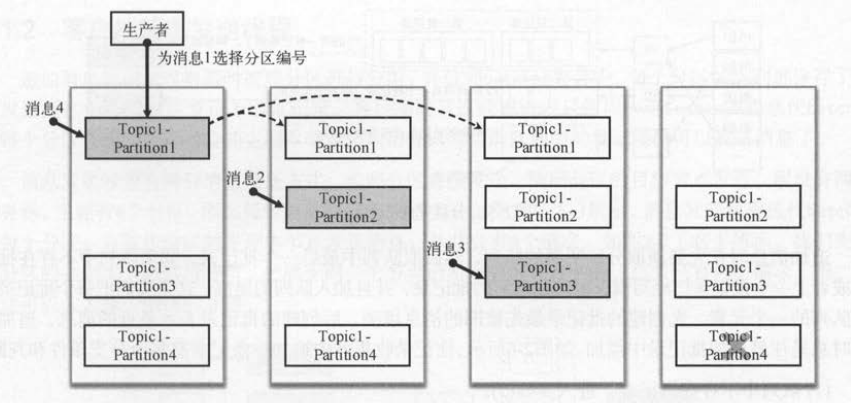
在客户端就为消息选择分区的目的是:只有为消息选择分区,才能知道应该发送到哪个节点,否则只能随便找一个服务端节点,再由那个节点去决定如何将消息、
转发给其他正确的节点来保存。 后面这种方式增加了服务端的负担,多了不必要的数据传输 。 这种方式比在客户端选择分区多了一次消息传输,
而且是全量的数据传输 。消息经过序列化,并且要存储的分区编号也己选择,下一步要将消息先缓存在客户端的记录收集器里 。
2. 客户端记录收集器
生产者发送的消息先在客户端缓存到记录收集器RecordAccumulator中,等到一定时机再由发送线程Sender批量地写入Kafka集群 。 生产者每生产一条消息,
就向记录收集器中追加一条消息,追加方法的返回值表示批记录( RecordBatch )是否满了 : 如果批记录满了, 则开始发送这一批数据 。 如图 所示,
每个分区都有一个双端队列用来缓存客户端的消息,队列的每个元素是一个批记录 。 一旦分区的队列中有批记录满了,就会被发送线程发送到分区对应的节点 。
客户端消息发送线程
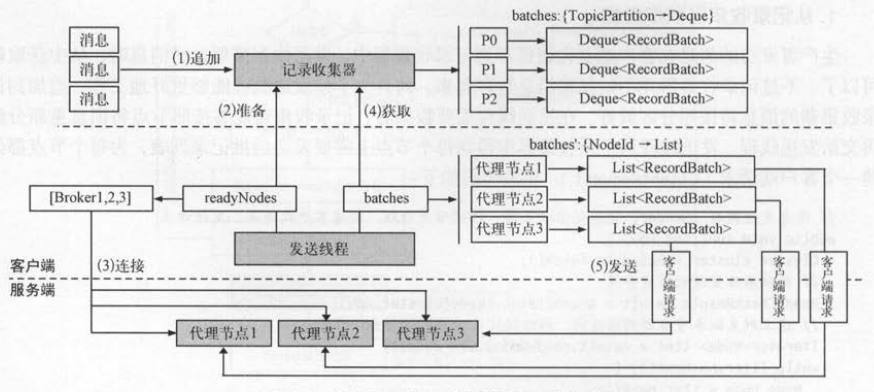
追加消息到记录收集器时按照分区进行分组,并放到 batches集合中,每个分区的队列都保存了即将发送到这个分区对应节点上的批记录,
客户端的发送线程可 以只使用一个 Sender线程迭代batches的每个分区,获取分区对应的主副本节点,取出分区对应的队列中的批记录就可以
发送消息了 。
消息发送线程有两种消息发送方式 : 按照分区直接发送 、 按照分区的目标节点发送。 假设有两台服务器, 主题有6个分区,那么每台服务器就有3个分区 。
如图(左)所示,消息发送线程迭代batches的每个分区 , 直接往分区的主副本节点发送消息,总共会有6个请求 。 如图(右)所示,我们先按
照分区的主副本节点进行分组, 把属于同一个节点的所有分区放在一起,总共只有两个请求 。 第二种做法可以大大减少网络的开销 。

1 . 从记录收集器获取数据
生产者发送的消息在客户端首先被保存到记录收集器中 ,发送线程需要发送消息时 ,从中获取就可以了 。记录收集器并不仅仅将消息暂存起来,
为了使发送线程能够更好地工作,追加到记录收集器的消息将按照分区放好。 在发送线程需要数据时, 记录收集器能够按照节点将消息重新分组
再交给发送线程。 发送线程从记录收集器中得到每个节点上需要发送的批记录列表 , 为每个节点都创建一个客户端请求( CllentRequest )。
追加消息到记录收集器的数据结构是batches : TopicPartition → Deque<RecordBatch>,读取记录收集器的数据结构是 batches:Nodeld → List<RecordBatch> 。
为了区分这两个 batches ,把后者叫作batches ’, 从batches转变为batches ’的步骤如下 。
(1)迭代 batches 的每个分区,获取TopicPartition 对应的主副本节点 : NodeId 。
(2)获取分区的批记录队列中的第一个批记录 : TopicPartition → RecordBatch 。
(3)将相同主副本节点的所有分区放在一起 : NodeId → List<RecordBatch>。
(4)将相同主副本节点的所有批记录放在一起: NodeId → List<RecordBatch>。
如图所示,步骤(1)产生batches ,步骤(4)产生batches ’ 。 发送线程从记录收集器获取数据,然后创建客户端请求并发送给服务端,具体步骤如下 。
(1)消息被记录收集器收集,并按照分区追加到队列的最后一个批记录中 。
(2)发送线程通过 ready ()从记录收集器中找出已经准备好的服务端节点 。
(3)节点已经准备好 , 如果客户端还没有和 它们建立连接,通过 connect ()建立到服务端的连接 。
(4)发送线程通过drain()从记录收集器获取按照节点整理好的每个分区的批记录 。
(5)发送线程得到每个节点的批记录后 , 为每个节点创建客户端请求,并将请求发送到服务端 。
发送线程不仅要从记录收集器读取数据 , 而且还要将读取到的数据用来创建客户端请求。
发送线程并不负责真正发送客户端请求 , 它会从记录收集器中取出要发送的消息 , 创建好客户端请求,然后把请求交给客户端网络对象( NetworkClient )去发送。
因为没有在发送线程中发送请求,所以创建客户端请求时需要保留目标节点,这样客户端网络对象获取出客户端请求时 , 才能知道要发送给哪个目标节点
客户端网络连接对象
客户端网络连接对象( NetworkCllent )管理了客户端和服务端之间的 网络通信,包括连接的建立、发送客户端请求 、读取客户端响应 。
1 准备发送客户端请求
客户端向服务端发送请求需要先建立网络连接。 如果服务端还没有准备好,即还不能连接,这个节点在客户端就会被移除掉,确保消息不会发送给还没有准备好的节点;
为了保证服务端的处理性能,客户端网络连接对象有一个限制条件:针对同一个服务端,如果上一个客户端请求还没有发送完成,则不允许发送新的客户端请求 。
2. 客户端轮询并调用回调函数
发送线程 发出请求的也会接收客户端响应 。 下面总结了客户端是否需要响应结果的两种场景下,执行顺序 。
- 不需要响应的流程。开始发送请求→添加客户端请求到队列→发送请求→请求发送成功→从队列中删除发送请求→构造客户端响应
- 需要响应的流程。开始发送请求→添加客户端请求到队列→发送请求→请求发送成功→等待接收响应→接收响应→接收到完整的响应→从队列中删除客户端请求→构造客户端响应 。
3 . 客户端请求和客户端响应的关系
客户端请求( CllentRequest )包含客户端发送的请求和回调处理器,客户端响应( CllentResponse )包含客户端请求对象和响应结果的内容。
客户端请求和客户端响应的生命周期都在客户端的连接管理类( NetworkCllent )里 。 NetworkCllent不仅负责将发送线程构造好的客户端请求发送出去,
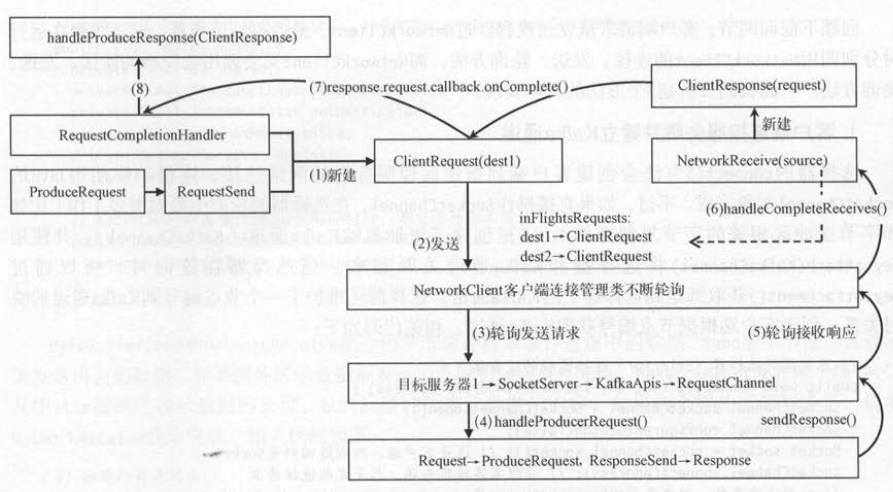
而且还要将服务端的响应结果构造成客户端响应并返回给客户端。 下图以“客户端发送请求,服务端接收请求,服务端返回结果,客户端接收请求”
这个完整的流程,来梳理这些对象之间的关联 。
(1) 发送线程创建的客户端请求对象包括请求本身和回调对象 。
(2) 发送线程将客户端请求交给 NetworkCllent ,并记录目标节点到客户端请求的映射关系 。
(3) NetworkCllent的轮询得到发送请求,将客户端请求发送到对应的服务端目标节点 。
(4) 服务端处理客户端请求 , 将客户端响应通过服务端的请求通道返回给客户端 。
(5) NetworkCllent的轮询得到响应结果, 说明客户端收到服务端发送过来的请求处理结果 。
(6) 由于客户端发送请求时发送到了不同节点,收到的结果也可能来自不同节点 。 服务端发送过来的响应结果都表示了它是从哪里来的,
客户端根据NetworkReceive的 source查找步骤(2)记录的信息,得到对应的客户端请求, 把客户端请求作为客户端响应的成员变量。
(7) 调用口 ClientResponse.ClientRequest.Callback.onComplete () ,触发回调函数的调用 。
(8) 客户端请求中的回调对象会使用客户端的响应结果 , 来调用生产者应用程序向定义的回调函数 。
选择器处理网络请求
生产者客户端会按照节点对消息进行分组,每个节点对应一个客户端请求,那么一个生产者客户端需要管理到多个服务端节点的网络连接。 涉及网络通信时, 一般使用选择器模式 。
选择器使用JavaNIO异步非阻塞方式管理连接和读写请求,它用单个线程就可以管理多个网络连接通道 。 使用选择器的好处是:生产者客户端只需要使用一个选择器,
就可以同时和Kafka集群的多个服务端进行网络通信。
SocketChannel(客户端网络连接通道) 。 底层的字节数据读写都发生在通道上,比如从通道中读取数据、将数据写入通道 。 通道会和字节缓冲区一起使用,
从通道中读取数据时需要构造一个缓冲区,调用 channel. read(buffer)就会将通道的数据灌入缓冲区;将数据写入通道时,要先将数据写到缓冲区中,
调用 channel. write(buffer)可将缓冲区中的每个字节写入通道 。
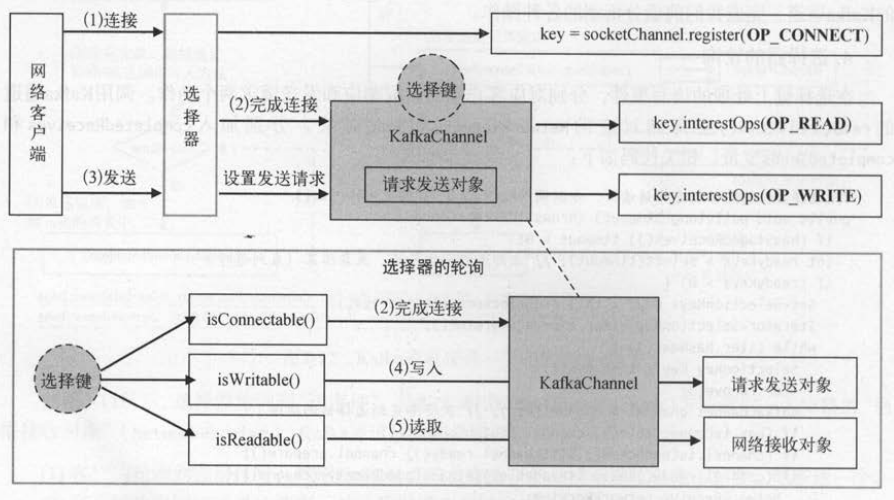
Selector(选择器) 。 发生在通道上的事件有读和写,选择器会通过选择键的方式监听读写事件的发生 。
SelectionKey (选择键) 。 将通道注册到选择器上, channel.register( selector)返回选择键,这样就将通道和选择器都关联了起来 。
读写事件发生时,通过选择键可以得到对应的通道,从而进行读写操作 。
客户端请求从发送线程经过NetworkClient ,最后再到选择器 。 发送线程在运行时分别调用NetworkClient 的连接、发送、轮询方法,而NetworkClient又会调用选择器
的连接 、 发送、轮询方法。 下面我们分析这3个方法的具体实现。
1. 客户端连接服务端并建立Kafka通道
Kafka通道( KafkaChannel )使用key.attach(KafkaChannel)将选择键和 Kafka 通道关联起来 。当选择器在轮询时,可以通过key.attachment () 获取绑定到
选择键上的Kafka 通道 。选择器还维护了一个节点编号至Kafka通道的映射关系,便于客户端根据节点编号获取Kafka通道 。
SocketChannel 、选择键、传输层、 Kafka通道的关系为 : SocketChannel注册到选择器上返回选择键,将选择器用于构造传输层,再把传输层用于构造Kafka通道 。
这样Kafka通道就和SocketChannel通过选择键进行了关联,本质上Kafka通道是对原始的SocketChannel的一层包装 。
2. Kafka通道和网络传输层
网络传输不可避免地需要操作Java I/O的字节缓冲区( ByteBuffer),传输层则面向底层的字节缓冲区,操作的是字节流。 Kafka通道使用抽象的 Send和NetworkReceive
表示网络传输中发送的请求和接收的响应 。 发生在 Kafka通道上的读写操作会利用传输层操作底层字节缓冲区,从而构造出NetworkReceive和 Send对象。

3. Kafka通道上的读写操作
客户端如果要操作Kafka通道,都要通过选择器 。 选择器监听到客户端的读写事件,会获取绑定到选择键上的Kafka通道 。
Kafka通道会将读写操作交给传输层,传输层再使用最底层的 SocketChannel完成数据传送 。 如图 所示,选择器如果监听到写事件发生,调用write ()方法把代表客户端请求的
Send对象发送到 Kafka通道; 选择器如果监听到读事件发生,调用 read ()方法从 Kafka通道中读取代表服务端响应结果的NetworkReceive
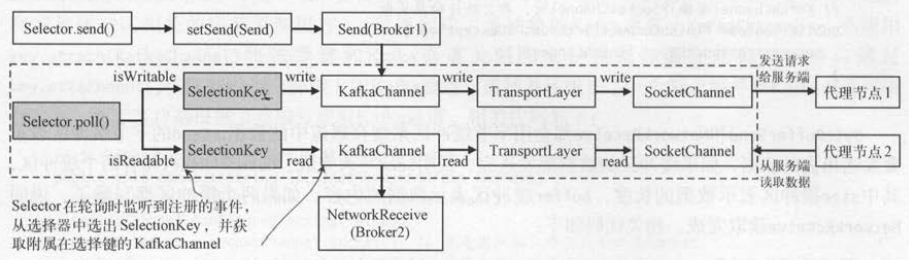
一个Kafka通道一次只能处理一个Send请求,每次Send时都要添加写事件。 当 Send发送成功后,就要取消写事件。 Kafka通道是由事件驱动的,如果没有请求,
就不需要监听写事件, Kafka通道就不需要做写操作。
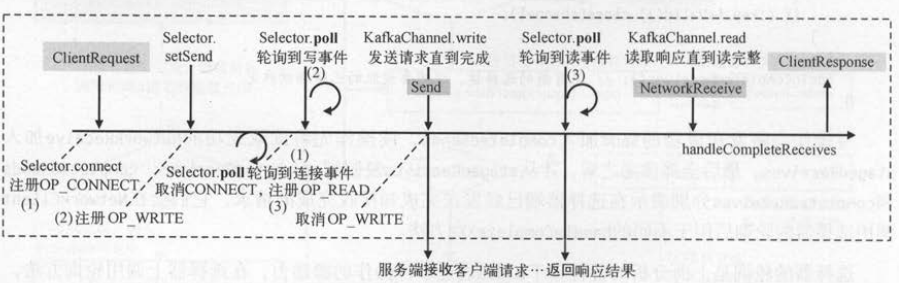
一个完整的发送请求和对应的事件监听步骤是 : 设置Send请求至Katka通道→注册写事件→发送请求→ Send请求发送完成→取消写事件。
Kafka通道上的读取操作和写入操作类似 。 读取操作如果一次 read () 没有完成 ,也要调用多次read()才能完成。 因为读取一次可能只是读取了一丁点,
构不成一个完整的NetworkReceive 。 读取数据时是将通道中的数据读取到NetworkReceiver的缓冲区中, 只有缓冲区的数据被填充满,
才表示接收到一个完整的NetworkRecive。
选择器轮询到“写事件”,会多次调用 KafkaChannel.write()方法发送一个完整的发送请求对象( Send ) , Kafka通道写入的具体步骤如下 。
(1) 发送请求时,通过 Kafka通道 的 setSend ()方法设置要发送的请求对象,并注册写事件 。
(2) 客户端轮询到写事件时, 会取出Kafka通道 中的发送请求 , 并发送给网络通道 。
(3) 如果本次写操作没有全部完成, 那么由于写事件仍然存在 , 客户端还会再次轮询到写事件 。
(4) 客户端新的轮询会继续发送请求, 如果发送完成 ,则取消写事件 ,并设置返回结果 。
(5) 请求发送完成后, 加入到completedSends集合中, 这个数据会被调用者使用 。
(6) 请求已经全部发送完成 , 重置 send对象为空 ,下一次新的请求才可以继续正常进行 。

选择器轮询到“读事件”,会多次调用 KafkaChannel.read ()方法读取一个完整的“网络接收对象”( NetworkReceiver), Kafka通道读取的具体步骤如下 。
(1)客户端轮询到读事件时,调用 Kafka通道的读方法,如果网络接收对象不存在,则新建一个 。
(2)客户端读取网络通道的数据,并将数据填充到网络连接对象 。
(3)如果本次读操作没有全部完成,客户端还会再次轮询到读事件 。
(4)客户端新的轮询会继续读取网络通道中的数据,如果读取完成,则设置返回结果 。
(5)读取完成后,加入到暂时完成的列表中,这个数据会被调用者使用 。
(6)读取全部完成,重置网络接收对象为空,下一次新的读取请求才可以继续正常进行
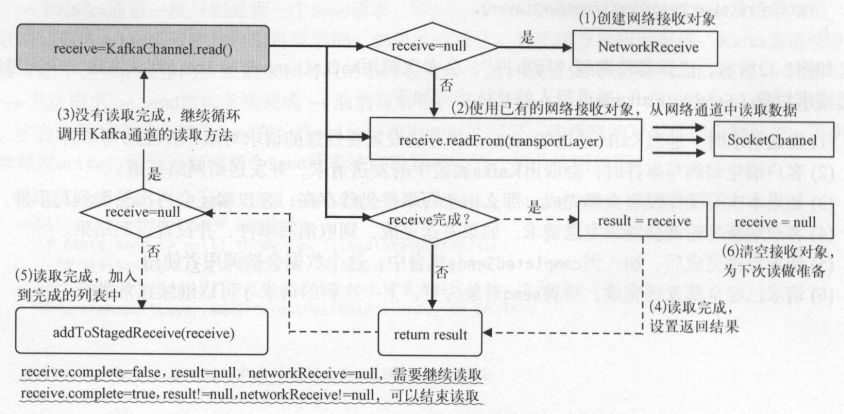
基于Kafka通道的连接、读取响应、发送请求 ,这些操作的前提条件是必须注册相应的连接 、 读取、写入事件。 选择器在轮询时监听到有对应的事件发生 ,
会获取选择键对应的Katka通道, 完成我们前面分析到的各种操作 。
4 . 选择器的轮询
选择键上处理的读写事件, 分别对应客户端的读取响应和发送请求两个动作 。 调用Kafka通道的read () 和 write () 会得到对应的 NetworkReceive 和
Send 对象 ,分别加入 completedReceives 和completedSends变扯 。
写操作会将发送成功的 Send加入 completedSends , 读操作先将读取成功的 NetworkReceive加入stagedReceives , 最后全部读完之后 ,
才从 stagedReceives复制到completedReceives 。 completedSends和completedReceives 分别表示在选择器端已经发送完成和接收完成的请求,
它们会在NetworkClient调用选择器的轮询启用于不同的 handleCompleteXXX方法 。选择器的轮询是上面分析的各种基于Kafka通道事件操作的源动力,
在选择器上调用轮询方法,通过不断地注册事件 、 执行事件处理、 取消事件,客户端才会发送请求给服务端,并从服务端读取响应结果。
不同的注册事件在选择器的轮询下,会触发不同的事件处理。 客户端建立连接时注册连接事件(步骤(1) ),发送请求时注册写事件(步骤(2))。
连接事件的处理合确认成功连接,并注册读事件(步骤(3))。 只有成功连接后,写事件才会被接着选择到 。 写事件发生时会将请求发送到服
务端,接着客户端就开始等待服务端返回响应结果 。 由于步骤(3)已经注册了读事件,因此服务端如果返回结果,选择器就能够监听到读事件。

Kafka技术内幕 读书笔记之(二) 生产者——新生产者客户端的更多相关文章
- Kafka技术内幕 读书笔记之(三) 生产者——消费者:高级API和低级API——基础知识
1. 使用消费组实现消息队列的两种模式 分布式的消息系统Kafka支持多个生产者和多个消费者,生产者可以将消息发布到集群中不同节点的不同分区上:消费者也可以消费集群中多个节点的多个分区上的消息 . 写 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(二)
消费者拉取消息 消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互.一个生产者写入的分区和消费者分配的分区都可能有多个,同时多个分区的主副本有可能在同一个节 ...
- Kafka技术内幕 读书笔记之(一) Kafka入门
在0.10版本之前, Kafka仅仅作为一个消息系统,主要用来解决应用解耦. 异步消息 . 流量削峰等问题. 在0.10版本之后, Kafka提供了连接器与流处理的能力,它也从分布式的消息系统逐渐成为 ...
- Kafka技术内幕 读书笔记之(二) 生产者——服务端网络连接
KafkaServer是Kafka服务端的主类, KafkaServer中和网络层有关的服务组件包括 SocketServer.KafkaApis 和 KafkaRequestHandlerPool后 ...
- Kafka技术内幕 读书笔记之(六) 存储层——日志的读写
-Kafka是一个分布式的( distributed ).分区的( partitioned ).复制的( replicated )提交日志( commitlog )服务 . “分布式”是所有分布式系统 ...
- Kafka技术内幕 读书笔记之(六) 存储层——服务端处理读写请求、分区与副本
如下图中分区到 日 志的虚线表示 : 业务逻辑层的一个分区对应物理存储层的一个日志 . 消息集到数据文件的虚线表示 : 客户端发送的消息集最终会写入日志分段对应的数据文件,存储到Kafka的消息代理节 ...
- Kafka技术内幕 读书笔记之(五) 协调者——延迟的加入组操作
协调者处理不同消费者的“加入组请求”,由于不能立即返回“加入组响应”给每个消费者,它会创建一个“延迟操作”,表示协调者会延迟发送“加入组响应”给消费者 . 但协调者不会为每个消费者的 “加入组请求 ...
- Kafka技术内幕 读书笔记之(三) 消费者:高级API和低级API——消费者消费消息和提交分区偏移量
消费者拉取钱程拉取每个分区的数据,会将分区的消息集包装成一个数据块( FetchedDataChunk )放入分区信息的队列中 . 而每个队列都对应一个消息流( KafkaStream ),消费者客户 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费组状态机
协调者保存的消费组元数据中记录了消费组的状态机 , 消费组状态机的转换主要发生在“加入组请求”和“同步组请求”的处理过程中 .协调者处理“离开消费组请求”“迁移消费组请求”“心跳请求” “提交偏移量请 ...
随机推荐
- POJ 1012
参考自:https://www.cnblogs.com/ECJTUACM-873284962/p/6480880.html Joseph Time Limit: 1000MS Memory Lim ...
- 进程间的通讯————IPC
""" IPC 指的是进程间通讯 之所以开启子进程 肯定需要它帮我们完成任务 很多情况下 需要将数据返回给父进程 然而 进程内存是物理隔离的 解决方案: 1.将共享数据放 ...
- bzoj 3673 可持久化并查集 by zky
Description n个集合 m个操作操作:1 a b 合并a,b所在集合2 k 回到第k次操作之后的状态(查询算作操作)3 a b 询问a,b是否属于同一集合,是则输出1否则输出0 0<n ...
- Linux 遍历目录下面所有文件,将目录名、文件名转为小写
当你从 Windows 服务器换到 Linux 服务器的时候,以前的上传目录的目录名.文件名会遇到大小写的问题.在 Windows 环境下面没有文件区分大小写的概念,而 Linux 却有严格的文件名大 ...
- VS编译LESS插件
1. LESS 用LESS写CSS可以用写程序代码的习惯写CSS.用了之后写CSS的效率会提高很多. 2.解释LESS 写出来的文件扩展名是.less,要运行的话,先解释成正常的CSS文件. 3. ...
- Linux及Windows查看占用端口的进程
想必大家在部署环境启动服务的时候,会遇到服务起不起来的问题,看日志,说是端口被占用了. 有的时候,我们不想改端口,那么,就需要去查看到底是哪个应用把这个端口给占用了,然后干掉它即可. 下面分别列举li ...
- prufer序列学习笔记
prufer序列是一个定义在无根树上的东西. 构造方法是:每次选一个编号最小的叶子结点,把他的父亲的编号加入到序列的最后.然后删掉这个叶节点.直到最后只剩下两个节点,此时得到的序列就是prufer序列 ...
- centos7破解安装confluence5.9.11
应用环境:Confluence是一个专业的企业知识管理与协同软件,也可以用于构建企业wiki.通过它可以实现团队成员之间的协作和知识共享. 安装环境:centos7.3 Java环境 1.7.0_79 ...
- Zabbix使用netstat监控会话
原文链接 TCP的连接状态对于我们web服务器来说是至关重要的,尤其是并发量ESTAB:或者是syn_recv值,假如这个值比较大的话我们可以认为是不是受到了攻击,或是是time_wait值比较高的话 ...
- 【SFA官方译文】:Spring Cloud Data Flow中的ETL
原创: 影宸风洛 SpringForAll社区 昨天 原文链接:https://www.baeldung.com/spring-cloud-data-flow-etl 作者:Norberto Ritz ...