Python网络爬虫四大选择器用法原理总结


- 选择所有标签: *
- 选择<a>标 签: a
- 选择所有class=”link” 的元素: .l in k
- 选择 class=”link” 的<a>标签: a.link
- 选择 id= " home ” 的<a>标签: a Jhome
- 选择父元素为<a>标签的所有< span>子标签: a > span
- 选择<a>标签内部的所有<span>标签: a span
- 选择title属性为” Home ” 的所有<a>标签: a [title=Home]
Python网络爬虫四大选择器用法原理总结的更多相关文章
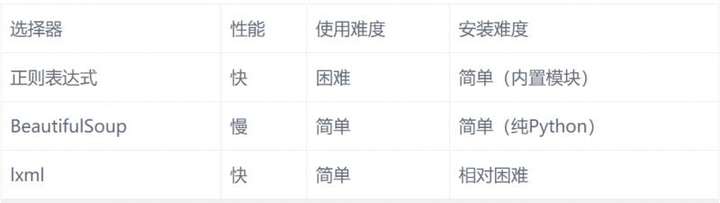
- Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
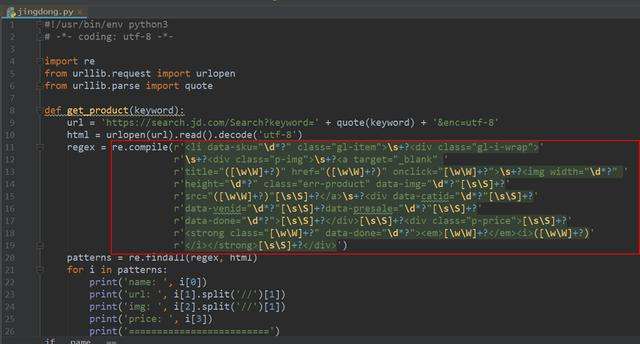
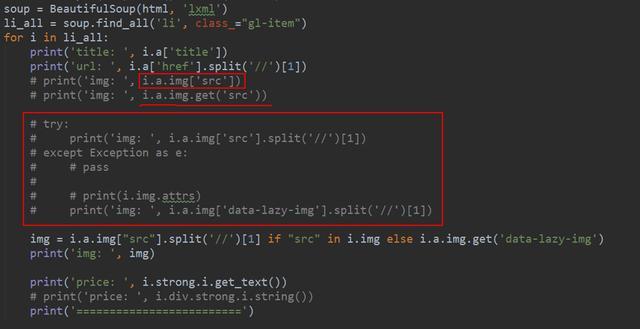
一.正则表达式 正则表达式为我们提供了抓取数据的快捷方式.虽然该正则表达式更容易适应未来变化,但又存在难以构造.可读性差的问题.当在爬京东网的时候,正则表达式如下图所示: 此外 ,我们都知道,网页时常 ...
- python网络爬虫进阶之HTTP原理,爬虫的基本原理,Cookies和代理介绍
目录 一.HTTP基本原理 (一)URI和URL (二)超文本 (三)HTTP和HTTPS (四)HTTP请求过程 (五)请求 1.请求方法 2.请求的网址 3.请求头 4.请求体 (六)响应 1.响 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2
Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2 1. 数据采集1 1.1. http lib1 1.2. HTML Parsers,1 1.3. 第8章 web爬取199 1 2 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
随机推荐
- java soket通信总结 bio nio aio的区别和总结
1 同步 指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪 自己上街买衣服,自己亲自干这件事,别的事干不了. 2 异步 异步是指用户进程触发IO操作以后便开始做自己的事情,而当IO操作 ...
- 你的 IDEA 是如何配置的?卡不卡?试试这样配置
本文作者在和同事的一次讨论中发现,对 IntelliJ IDEA 内存采用不同的设置方案,会对 IDE 的速度和响应能力产生不同的影响. Don't be a Scrooge and give you ...
- Python三大器之装饰器
Python三大器之装饰器 开放封闭原则 一个良好的项目必定是遵守了开放封闭原则的,就比如一段好的Python代码必定是遵循PEP8规范一样.那么什么是开放封闭原则?具体表现在那些点? 开放封闭原则的 ...
- EnvironmentPostProcessor
概览 SpringBoot支持动态的读取文件,留下的扩展接口 org.springframework.boot.env.EnvironmentPostProcessor,进行配置文件的集中管理,从而避 ...
- JavaWEB实现qq邮箱发送验证码——qq1692700664
// 随机验证码public String achieveCode() { String[] beforeShuffle = new String[] { "2", "3 ...
- 且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset
作者:Jules S. Damji 译者:足下 本文翻译自 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets ,翻译已 ...
- java后端无法接收到前端传递的json对象
java后端无法接收到前端传递的json对象 一·可能是因为未使用@RequestBody 在Controller层中,要么使用@RestController要么使用@Controller+@@Req ...
- js事件入门(1)
1.事件相关概念 1.1 什么是事件? 事件是用户在访问页面时执行的操作,也就是用户访问页面时的行为.当浏览器探测到一个事件时,比如鼠标点击或者按键.它可以触发与这个事件相关的JavaScript对象 ...
- 如何去除List集合中重复的元素
1.通过循环进行删除 public static void removeDuplicate(List list) { for ( int i = 0 ; i < list.size() - 1 ...
- 第一步:安装centos_8
关于centos的安装其实大部分时候都是在虚拟机环境下安装. 好处无疑有这几个:方便,快速,主要就是整出事情了我可以直接删了重装 我这边是在vmware下进行一个安装 vmware我这边给出下载链接: ...