Python之 爬虫(十二)关于深度优先和广度优先
- 网站的树结构
- 深度优先算法和实现
- 广度优先算法和实现
网站的树结构
通过伯乐在线网站为例子:
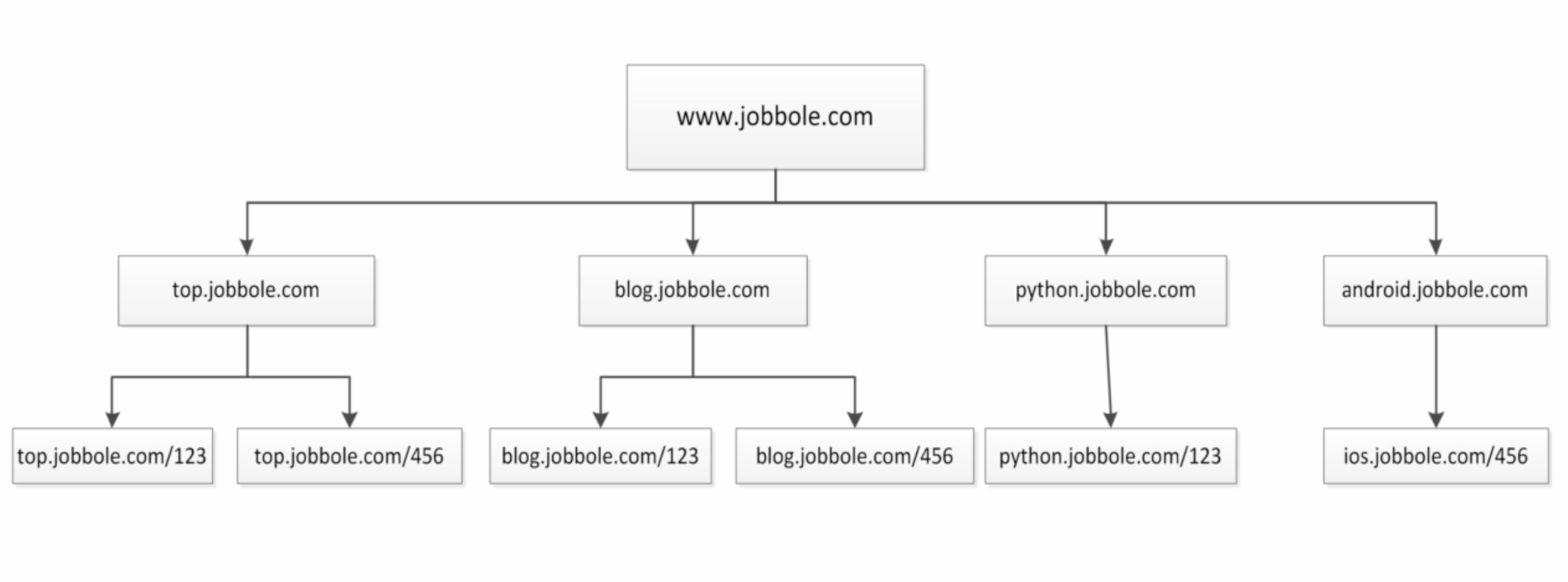
并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据的时候就会涉及到去重的问题,我们需要将爬过的url记录下来,我们将上图进行更改

在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先
深度优先
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接,通过下图进行理解:
注:scrapy默认采用的是深度优先算法
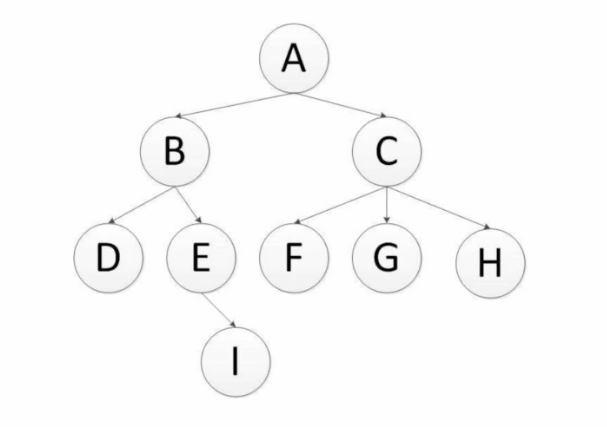
这里是深度优先,所以这里的爬取的顺序式:
A-B-D-E-I-C-F-G-H (递归实现)
深度优先算法的实现(伪代码):

广度优先
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页,通过下图进行理解:

还是以这个图为例子,广度优先的爬取顺序为:
A-B-C-D-E-F-G-H-I (队列实现)
广度优先代码的实现(伪代码):

Python之 爬虫(十二)关于深度优先和广度优先的更多相关文章
- 进击的Python【第十二章】:mysql介绍与简单操作,sqlachemy介绍与简单应用
进击的Python[第十二章]:mysql介绍与简单操作,sqlachemy介绍与简单应用 一.数据库介绍 什么是数据库? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,每个数 ...
- python 教程 第二十二章、 其它应用
第二十二章. 其它应用 1) Web服务 ##代码 s 000063.SZ ##开盘 o 26.60 ##最高 h 27.05 ##最低 g 26.52 ##最新 l1 26.66 ##涨跌 c ...
- python 教程 第十二章、 标准库
第十二章. 标准库 See Python Manuals ? The Python Standard Library ? 1) sys模块 import sys if len(sys.argv) ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python爬虫(十二)_XPath与lxml类库
Python学习指南 有同学说,我正则用的不好,处理HTML文档很累,有没有其他的方法? 有!那就是XPath,我们可以用先将HTML文档转换成XML文档,然后用XPath查找HTML节点或元素. 什 ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
随机推荐
- (八)利用 Profile 构建不同环境的部署包
接上回继续,项目开发好以后,通常要在多个环境部署,象我们公司多达5种环境:本机环境(local).(开发小组内自测的)开发环境(dev).(提供给测试团队的)测试环境(test).预发布环境(pre) ...
- MySQL LIMIT:限制查询结果的记录条数
基本的语法格式如下: <LIMIT> [<位置偏移量>,] <行数> LIMIT 接受一个或两个数字参数.参数必须是一个整数常量.如果给定两个参数,第一个参数指定第 ...
- 曹工改bug:centos下,mongodb开机不能自启动,systemctl、rc.local都试了,还是不行,要不要放弃?
问题背景 最近装个centos 7.6的环境,其中,基础环境包括,redis.nginx.mongodb.fastdfs.mysql等,其中,自启动使用的是systemctl,其他几个组件,都没啥问题 ...
- yii2.0数据库操作
User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的一条数据(举个例子): User::find()->w ...
- fatal error C1083: Cannot open include file: '_defs.h': No such file or directory
b-PAC SDK: https://www.baidu.com/link?url=p6FcG0fvFl6XJf9QdSFLBP16eaS03jOQsdr0zd8cYprHWwqVy5t53bzMrA ...
- Linux性能优化思路
性能测试的核心,就是找出性能瓶颈并进行性能优化,解决"慢"的问题,最终满足客户业务需求. [性能需求来源及性能问题现象] 性能需求的来源,主要分为以下几类: 项目组提出性能需求: ...
- JavaWeb网上图书商城完整项目--day02-10.提交注册表单功能之页面实现
1.当从服务器返回的注册错误信息的时候,我们在注册界面需要将错误信息显示出来 我们需要修改regist.jsp页面的代码:其中error是一个haspmap,c标签对map的属性可以直接使用 ${er ...
- linux网络编程-socket(37)
在编程的时候需要加上对应pthread开头的头文件,gcc编译的时候需要加了-lpthread选项 第三个参数是线程的入口参数,函数的参数是void*,返回值是void*,第四个参数传递给线程函数的参 ...
- 一文告诉你Linux如何配置KVM虚拟化--安装篇
KVM全称"Kernel-based Virtual Machine",即基于内核的虚拟机,在linux内启用kvm需要硬件,内核和软件(qemu)支持,这篇文章教你如何配置并安装 ...
- git命令--使用fork模式工作
一. 1.第一步,先将原作者项目fork到自己的目录下,这个可以直接在控制台操作 可以看到该项目在ins-product目录下,fork之后,可以去查看自己的工作目录 可以看到在本人目录下已经存在该项 ...