join 查询优化
在开发中往往会出现查询多表联查的情况,那么就会用到 join 查询。
Join查询种类
为了方便说明,先定义一个统一的表,下面再做例子。
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
表 t1、t2 结构相等,t2 1000条记录, t1 100 条记录,t1 的数据在 t2 上都有。
Index Nested-Loop Join(NLJ)
关于 NLJ 可以从名字上直接看出,这是一个使用到索引的 join 查询,正因为使用到索引,所以不需要用到临时表。
例子
select * from t1 straight_join t2 on (t1.a=t2.a);
straight_join :相当于强制版的 inner join。因为在使用 inner join 或 join 连接时,优化器默认使用的都是小表作为驱动表,但是如果排序或筛选条件列是被驱动表,那么该列的索引就会用不到,比如 select * from a inner join b where a.id=b.aid order by a.id,如果a的集合比b大,那么mysql就会以b为驱动表,这个时候如果a.id有索引的话,那么这个索引在 order by 排序时是不起效的(on 筛选时可以用到,排序只能通过驱动表排序)。那么就需要额外排序,甚至用到临时表,非常消耗性能,而 straight_join 的作用就是强制让左表作为驱动表,当然使用前提是在事先知道优化器选择的驱动表效率较低,然后才可以考虑使用 straight_join 。这里就是为了防止优化器选择错误的驱动表,当然,这里使用 inner join 也是会以 t1 小表作为基础表。
执行过程:
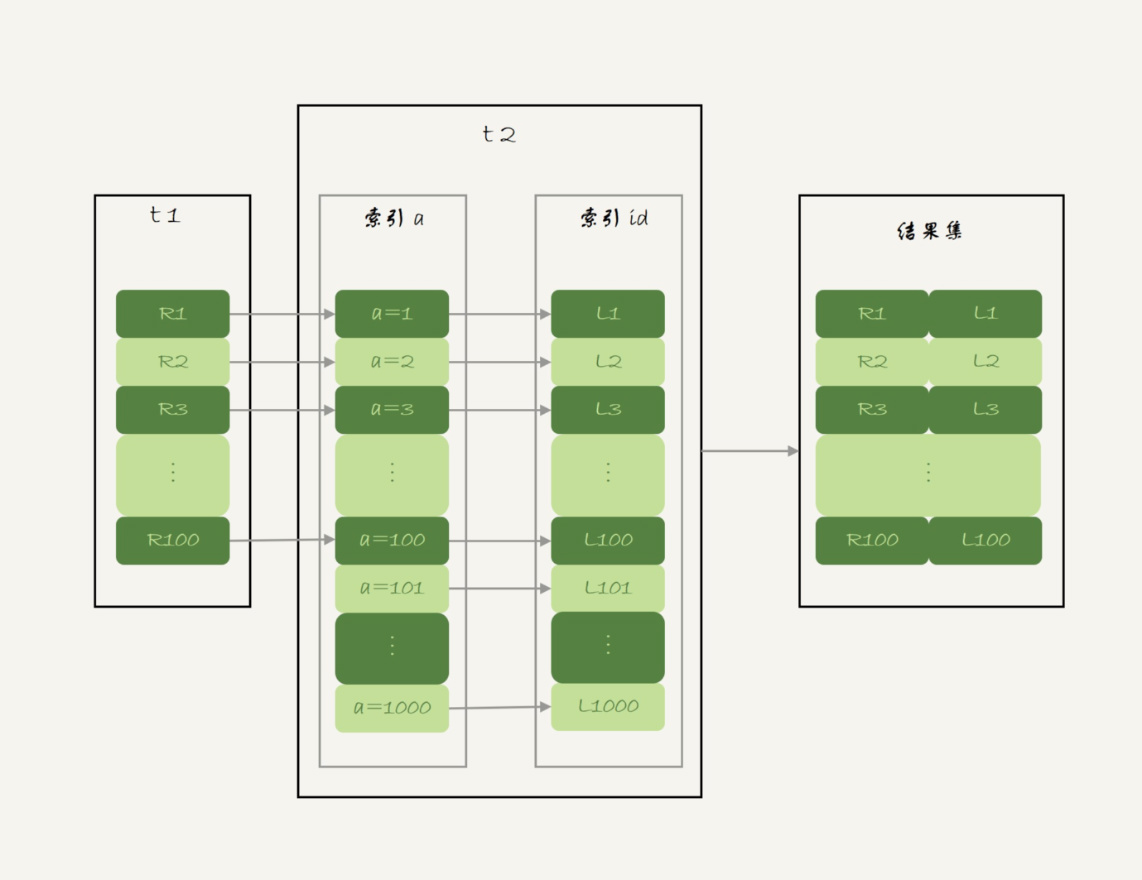
1、从表 t1 中读入一行数据 R;
2、从数据行 R 中,取出 a 字段到表 t2 里去查找;
3、取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
4、重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
整个过程步骤1 会遍历 t1 所有的行,所以一共会扫描100行。 而步骤2 因为会用到索引,所以每次扫描一次,一共扫描 100 行。最后拼接在一起,所以一共扫描 200 行。
公式:
假设被驱动表的行数是 M。每次在被驱动表查一行数据,要先搜索索引 a,再搜索主键索引。每次搜索一棵树近似复杂度是以 2 为底的 M 的对数,记为 log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。因此整个执行过程,近似复杂度是 N + N*2*log2M。
由此看来,不考虑其他因素的影响(比如上面straight_join 说到的情况),NLJ 方式以小表作为驱动表的效率会更高。
Simple Nested-Loop Join
没有用到索引。
例子
select * from t1 straight_join t2 on (t1.a=t2.b);
执行过程:
首先因为 straight_join 的作用,还是以 t1 为驱动表。执行时还是先从 t1 上取一条记录取 t2 上寻找对应的记录,但是因为 t2 的 b 列上没有索引,所以在 t2 上执行的是全表扫描。所以扫描行数为 100+100*1000。所以 Simple Nested-Loop Join 的效率很低,这种方式也是没有被 MySQL 采用。
Block Nested-Loop Join(BNJ)
这种方式也是没有用到索引,但是和上面一种的区别是在内存中实现的。主要思路是将驱动表加载到一个内存空间 join_buffer 中,然后从被驱动表上每次拿出一条记录到 join_buffer 中找到符合条件的记录,然后返回。join_buffer 大小可由参数 join_buffer_size 设定,默认值是 256k。在 explain 中出现 Block Nested Loop 说明使用的是 BNJ 算法,BNJ 执行效率比较低,所以应该避免。
例子
select * from t1 straight_join t2 on (t1.a=t2.b);
执行过程:
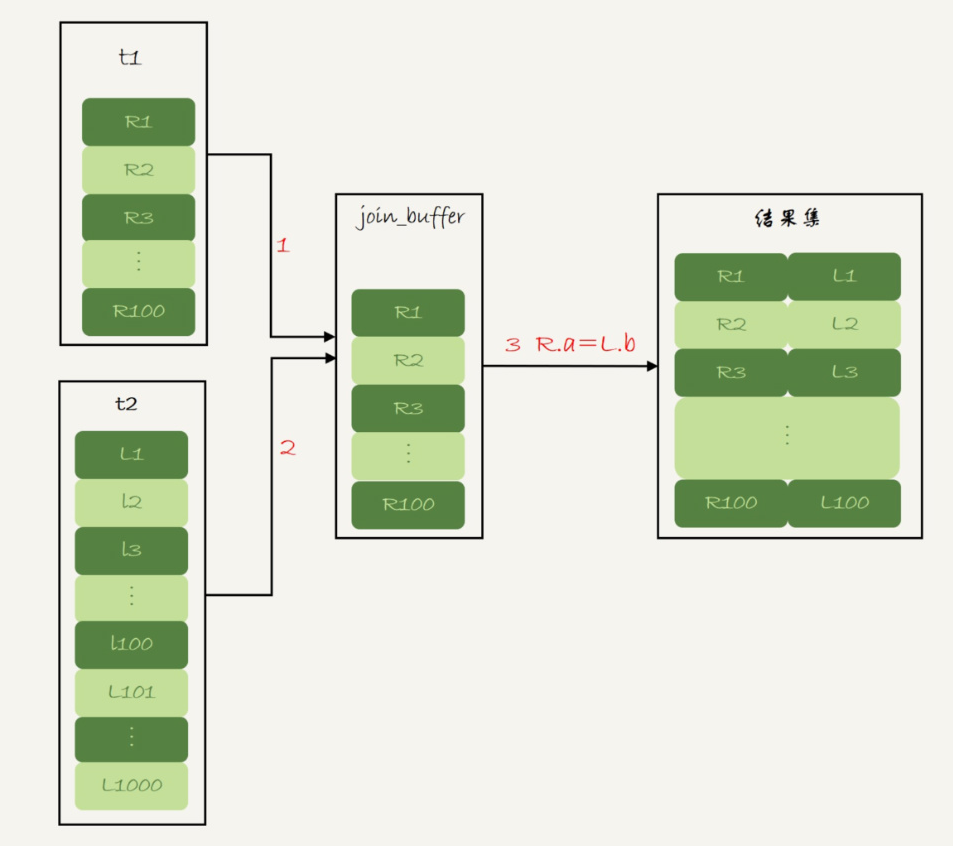
1、如果 join_buffer 空间足够存储 t1 所有记录:
1)把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
2)扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。需要注意的是,因为 join_buffer 是无序数组,所以虽然 t1 的a 列有索引,在这一步寻找时也不会用到索引。
2、如果 join_buffer 空间不能存储 t1 的所有记录。那么就会分批来处理。
1)扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
2)扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
3)清空 join_buffer;
4)继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。
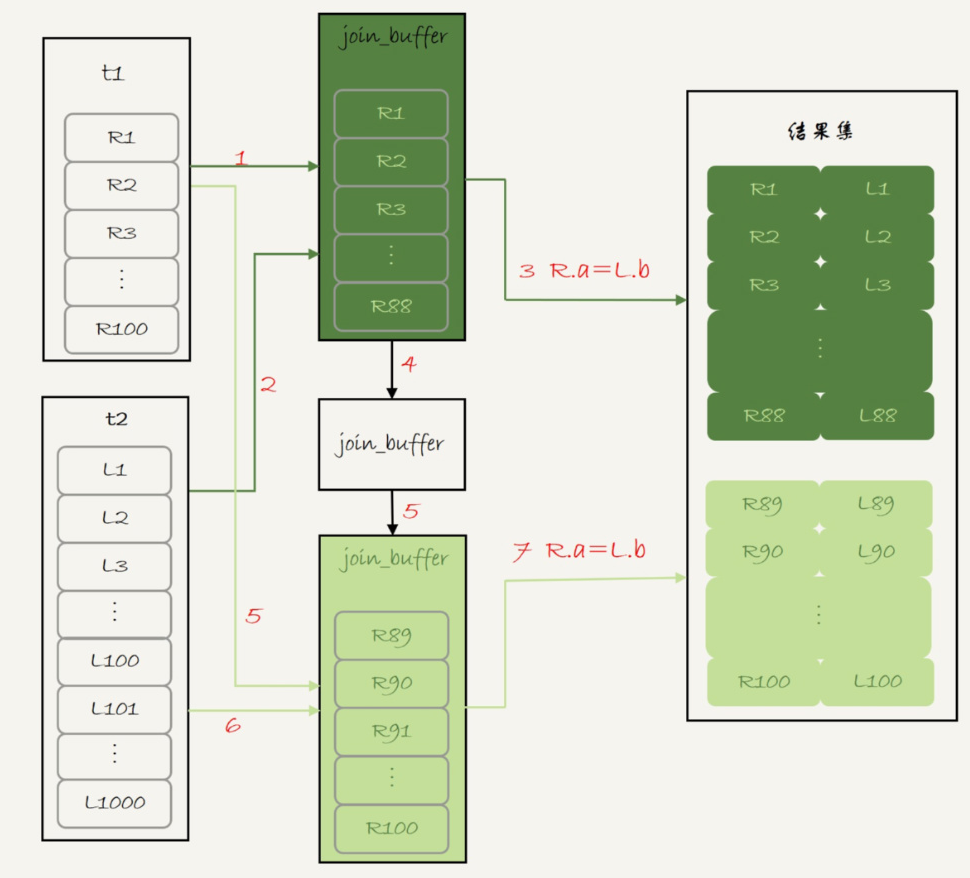
结论:以上这两种扫描的总行数都是一样的。 1、将 t1扫描进 join_buffer 100行;2、t2 每行去 joiin_buffer 上进行全表扫描 100*t2总行数1000。所以总行数为 100 +100*1000。和上面的 Simple Nested-Loop Join 方式扫描的行数一样,但是因为使用的 join_buffer 是在内存中的,所以执行的速度会比 Simple Nested-Loop Join 快得多。
公式:
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。注意,这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。那么扫描行数就是 N+λ*N*M。
由此可以看出,驱动表参与筛选的记录数越少,扫描的行数就越少,效率也就越高。也就是在不考虑其他因素的影响下,以小表为驱动表可以提高 BNJ方式的执行效率。
优化
Index Nested-Loop Join(NLJ)
NLJ 查询过程中会用到索引,所以查询的效率会很快,但是其还是有优化空间的,那就是 MySQL 5.6引入的 Batched Key Access(BKA) 算法。其原理就是通过 MRR 实现顺序读,因为之前的 NLJ 过程是每次拿一条记录去匹配,然后得到对应的一条记录,这样每次获取的记录主键很有可能不是按顺序去查询的,同时多次的查询使得执行效率比较低(每次都需要从 B+树的根节点开始查找匹配)。
MRR
MRR 会先将要查询的记录主键添加到 read_rnd_buffer中(如果放不下就分多次进行),对 read_rnd_buffer 中的 id 进行递增排序,然后再依次按 id 去查询,经过 MRR 优化的执行就会走 B+ 树的叶子节点,所以查询效率提高。下面以 sql:select * from t1 where a>=1 and a<=100 为例,其中 a 列有索引,看一下开启 MRR 执行的流程图:
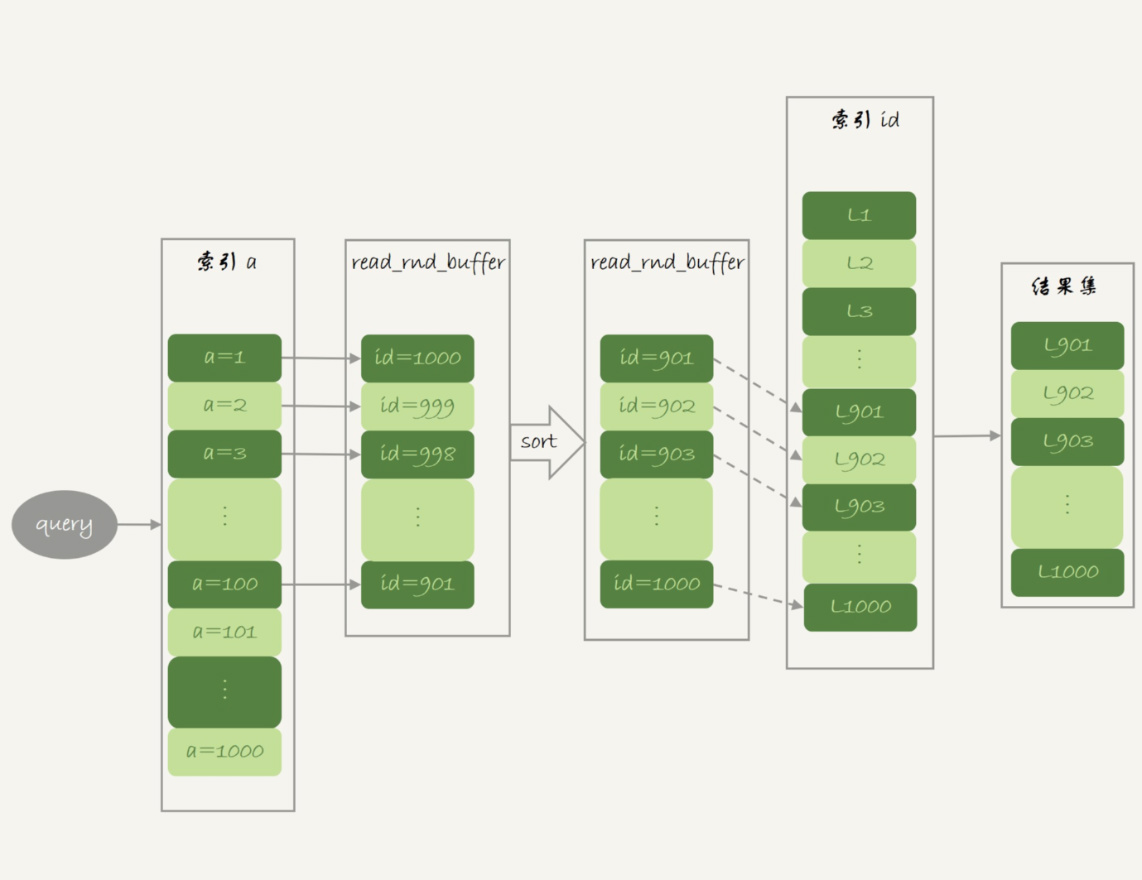
开启:
设置:SET @@optimizer_switch='mrr=on,mrr_cost_based=on';
相关参数:
当mrr=on,mrr_cost_based=on,则表示cost base的方式还选择启用MRR优化,当发现优化后的代价过高时就会不使用该项优化
当mrr=on,mrr_cost_based=off(官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。),则表示总是开启MRR优化。
如果查询使用了 MRR 优化,那么使用 explain 解析就会出现 Using MRR 的提示

BKA
使用 BKA 的过程:
还是以上面的 select * from t1 straight_join t2 on (t1.a=t2.b); 为例
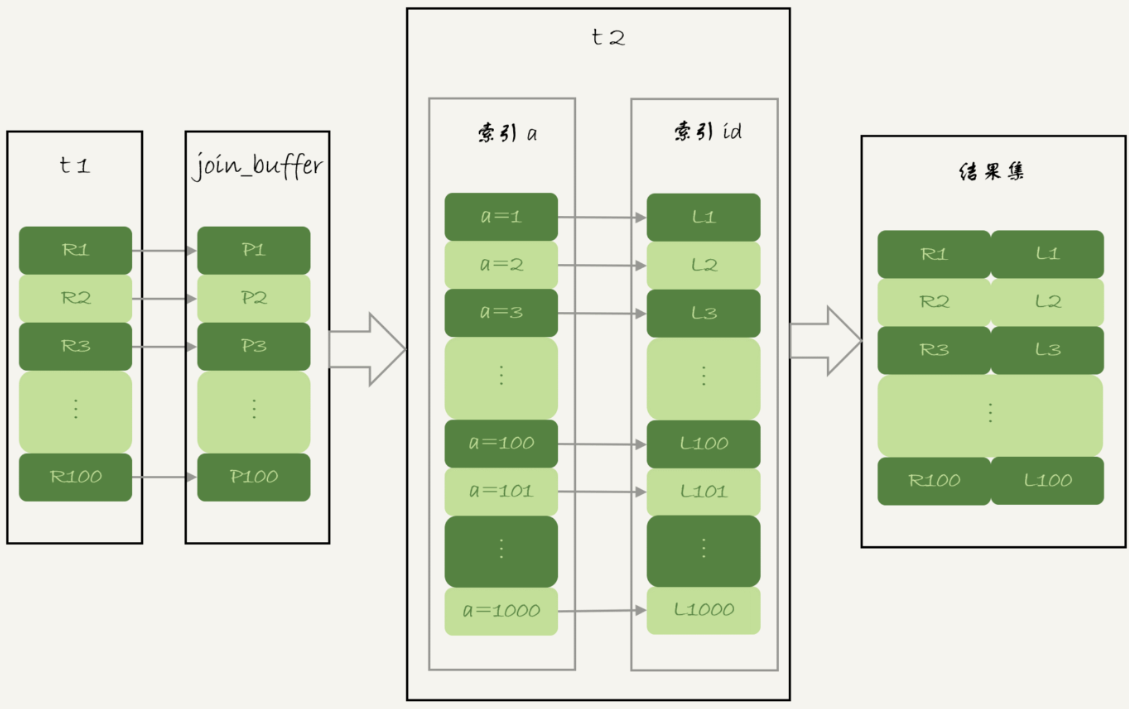
首先将 t1 的筛选字段存入 join_buffer(如果存不下就分多次执行),然后将存储的字段值批量去 t2 上匹配,得到匹配的主键,然后进行主键排序,再去依次查询对应的记录返回。
Block Nested-Loop Join(BNJ)
BNJ 造成性能损失很高,主要原因有以下三个方面:
1、可能会多次扫描被驱动表,占用磁盘 IO 资源;
2、判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源;
3、可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率(影响严重)。通过 InnoDB 中的缓冲池(Buffer Pool) 可以知道缓冲池是使用了 LRU 算法来对热点数据进行了优化的,但是在某些情况下还是会出现热点数据被挤掉的场景,使用 BNJ 进行多次的查询就是其中一种,因为 BNJ 操作如果涉及的表数据量比较大,那么用到的数据也很多,那么如果在使用到后面某一时刻某个会话也查询了某个冷门数据,那么因为之前 BNJ 也查询了,并且中间的时间间隔达到了最大老年时间,所以这个冷门数据就会进入老年代头部,挤掉其他热点数据。大表 join 操作虽然对 IO 有影响,但是在语句执行结束后,对 IO 的影响也就结束了。但是,对 Buffer Pool 的影响就是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率。
优化思路1:减少 BNJ 的循环次数,上面说到,多次的扫描被驱动表会长时间占用磁盘 IO 资源,造成系统整体性能下降。
方法:增大 join_buffer_size 的值,减少对被驱动表的扫描次数。
优化思路2:将 BNJ 优化成 NLJ。
方法1:在筛选条件字段使用率比较高时,可以考虑为其创建一个索引,这样在执行时因为有索引就会变成 NLJ 了。
方法2:如果筛选字段使用率很低,为其创建索引会提高维护的成本,做到得不偿失,那么该如何优化?答案是可以使用临时表,从 MySQL 中的临时表 可以知道,临时表会随着会话的结束而自动销毁,省去了维护的成本;同时不同会话可以创建同名的临时表,不会产生冲突。这使得临时表成为优化筛选字段使用率低的 BNJ 查询的绝佳方法。
例:假设有表 t1、t2,表 t1 里,插入了 1000 行数据, t2 中插入了 100 万行数据 。执行 select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000; b 列使用率很低
未优化前执行:
1、把表 t1 的所有字段取出来,存入 join_buffer 中。这个表只有 1000 行,join_buffer_size 默认值是 256k,可以完全存入。
2、扫描表 t2,取出每一行数据跟 join_buffer 中的数据进行对比,
1)如果不满足 t1.b=t2.b,则跳过;
2)如果满足 t1.b=t2.b, 再判断其他条件,也就是是否满足 t2.b 处于[1,2000]的条件,如果是,就作为结果集的一部分返回,否则跳过。整个筛选过程一共扫描了 1000*1000000 = 10亿行。
优化思路:
1、把表 t2 中满足条件的数据放在临时表 tmp_t 中;
2、为了让 join 使用 BKA 算法,给临时表 tmp_t 的字段 b 加上索引;
3、让表 t1 和 tmp_t 做 join 操作。
实现:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
过程消耗:
1、执行 insert 语句构造 temp_t 表并插入数据的过程中,对表 t2 做了全表扫描,这里扫描行数是 100 万。
2、之后的 join 语句,扫描表 t1,这里的扫描行数是 1000;join 比较过程中,做了 1000 次带索引的查询(因为t1 1000行,作为驱动表,t2作为被驱动表)。相比于优化前的 join 语句需要做 10 亿次条件判断来说,这个优化效果还是很明显的。
进一步优化:
临时表又分为磁盘临时表和内存临时表,使用内存临时表效率比磁盘临时表高,上面的引擎是 innodb,也就是磁盘临时表,如果换成 Memory 引擎就是内存临时表。但是相对的内存临时表只能存储2000行数据,所以在数据量特别大时还是应该使用磁盘临时表。
三张表优化
表结构:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
create table t2 like t1;
create table t3 like t2;
insert into ... //初始化三张表的数据
如何优化语句:select * from t1 join t2 on(t1.a=t2.a) join t3 on (t2.b=t3.b) where t1.c>=X and t2.c>=Y and t3.c>=Z;
答:首先根据where 三个条件来判断哪个表符合条件的返回的字段长度最小,将最小的作为驱动表。
1、第一种情况,如果选出来是表 t1 或者 t3,那剩下的部分就固定了。(因为 join 顺序是 t1、t2、t3,确定小表直接向另一个方向驱动就可以了)
1)如果驱动表是 t1,则连接顺序是 t1->t2->t3,要在被驱动表字段创建上索引,也就是 t2.a 和 t3.b 上创建索引;
2)如果驱动表是 t3,则连接顺序是 t3->t2->t1,需要在 t2.b 和 t1.a 上创建索引。
同时,我们还需要在第一个驱动表的字段 c 上创建索引。
2、第二种情况是,如果选出来的第一个驱动表是表 t2 的话,则需要评估另外两个条件的过滤效果。
总之,整体的思路就是,尽量让每一次参与 join 的驱动表的数据集,越小越好,因为这样我们的驱动表就会越小。
总结
NLJ 原本是不需要用到 join_buffer 的,但是可以通过 BKA 优化使用 join_buffer ,此时方向是使用在 join_buffer 中的驱动表数据去被驱动表上匹配,然后得到主键,排序、回表返回结果,如果 read_rnd_buffer 或者 join_buffer 空间不够就分多次进行。
BNL 原本没有用到索引,所以必须使用 join_buffer 来帮助查询,方向是被驱动表到 join_buffer 上的驱动表数据进行匹配,优化后变成 BKA 算法的 NLJ,所以方向也就变成了使用在 join_buffer 中的驱动表数据去被驱动表上匹配。所以在 BNL 优化前的思路就是减少被驱动表的遍历次数,也就是增大 join_buffer 的大小;而优化后就需要在被驱动表上创建索引,来优化查询。
join 的 on 条件与 where 条件的关联
表结构:
create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb;
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
on 条件写在 where 中可能会使外连接失效
以上面的表结构,执行:
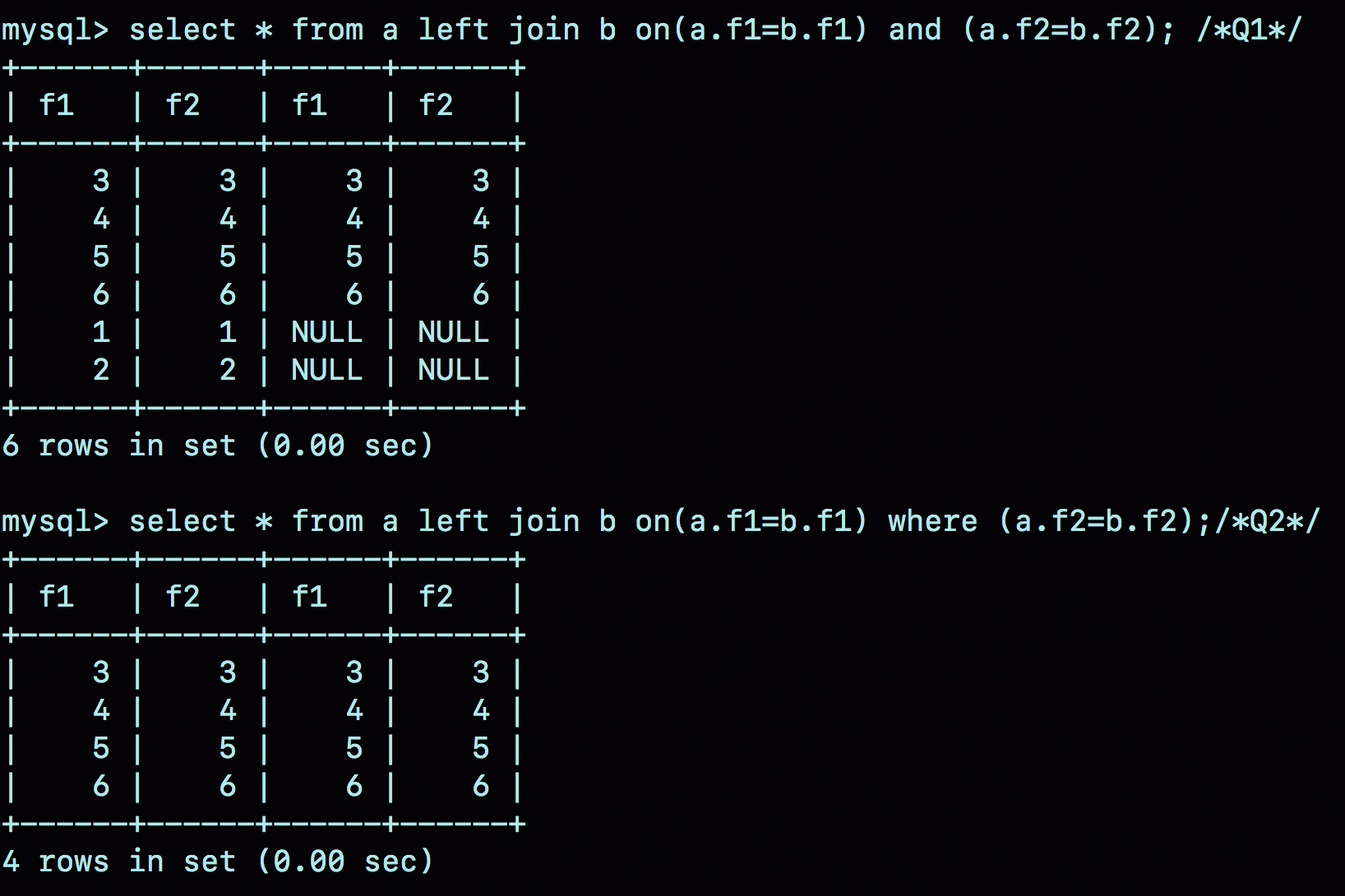
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q1*/
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
执行结果:
分析
Q1:
解析:

因为是以 a 作为驱动表,而 a 的 f1有索引,f2没有索引,所以会用到临时表来筛选,也就出现 using join buffer(Block hested Loop)
过程:
1、把表 a 的内容读入 join_buffer 中。因为是 select * ,所以字段 f1 和 f2 都被放入 join_buffer 了。
2、顺序扫描表 b,对于每一行数据,判断 join 条件(也就是 (a.f1=b.f1) and (a.f1=1))是否满足,满足条件的记录, 作为结果集的一行返回。如果语句中有 where 子句,需要先判断 where 部分满足条件后,再返回。
3、表 b 扫描完成后,对于没有被匹配的表 a 的行(在这个例子中就是 (1,1)、(2,2) 这两行),把剩余字段补上 NULL,再放入结果集中。
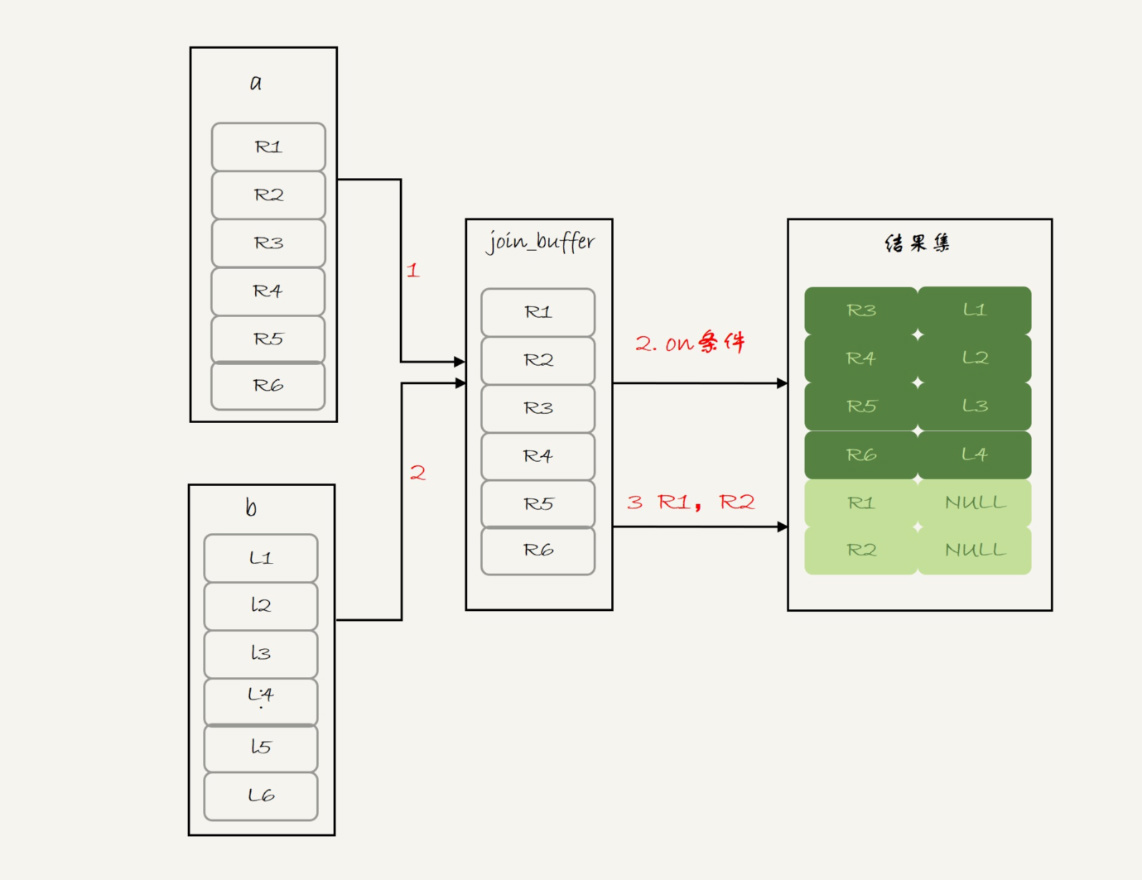
Q2:
解析:

为什么Q2执行会把 null 值部分过滤掉了?
这是因为在 where 条件中,NULL 跟任何值执行等值判断和不等值判断的结果,都是 NULL。这里包括, select NULL = NULL 的结果,也是返回 NULL。所以在筛选时,先通过 on 判断带 null 的记录,但是因为 where 条件的作用,会筛掉其中为 null 的记录,导致 left join 失效,所以优化器在实际执行时会将这条语句优化成 inner join,并把筛选条件移到 where 条件后面。整个语句就会被优化成下面的语句执行:

也就是 select a.f1, a.f2, b.f1, b.f2 from a join b where a.f1 = b.f1 and a.f2=b.f2
所以过程就变成:
顺序扫描表 b,每一行用 b.f1 到表 a 中去查,匹配到记录后判断 a.f2=b.f2 是否满足(索引下推),满足条件的话就作为结果集的一部分返回。
所以,如果想要执行外连接查询,筛选条件就不能写在 where 中。
内连接可能会将on条件优化成 where 条件
执行:
select * from a join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q3*/
select * from a join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q4*/
解析:
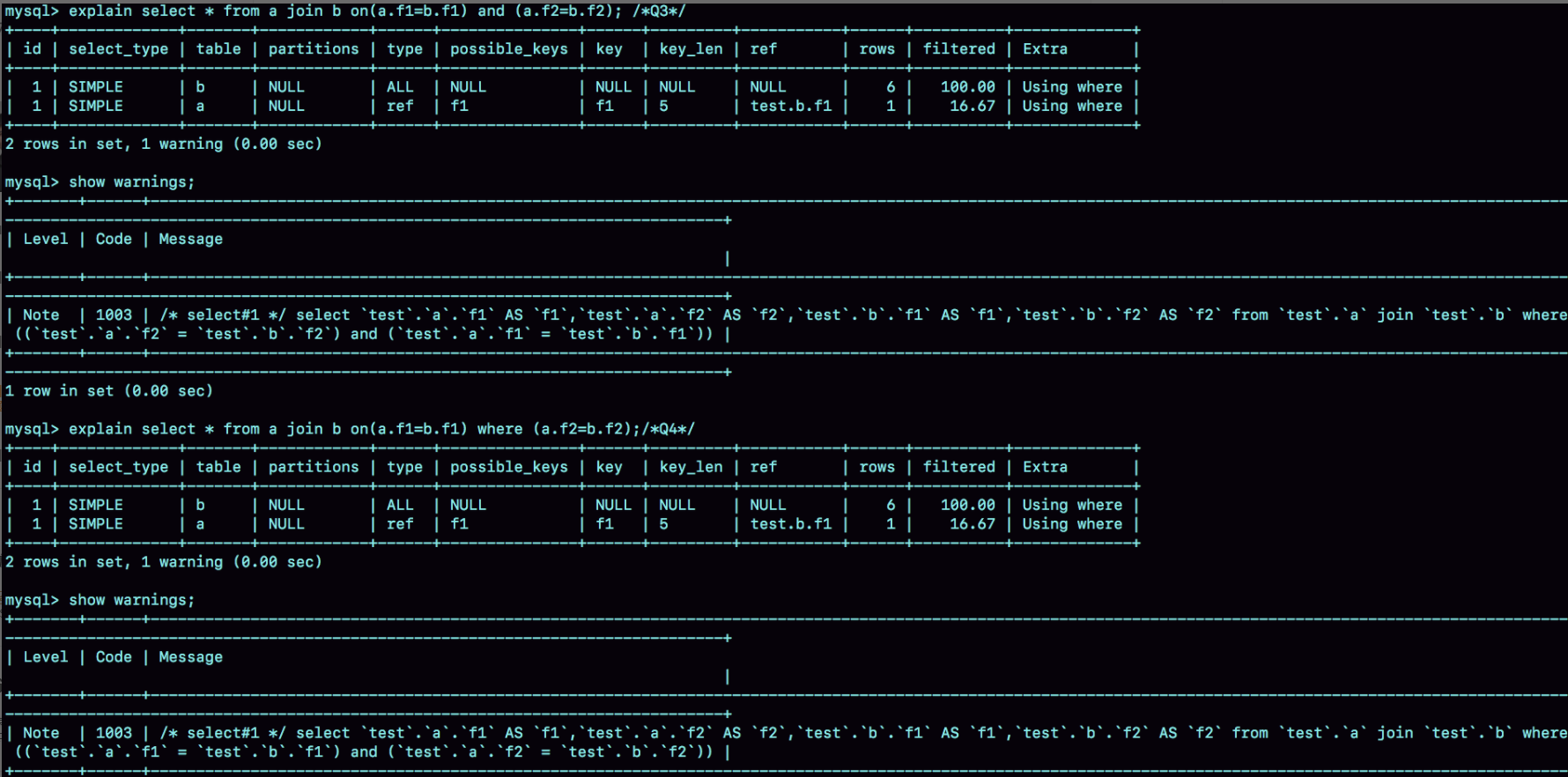
可以看到两条语句解析结果是一模一样的,并且执行语句也与这两条语句都不一样,都被优化成 select * from a join b where a.f1=b.f1 and a.f2=b.f2 。执行过程和上面的 Q2 一样。这是因为如果放在 on 中就会用到临时表,效率会低一些,所以优化器直接优化放在 where 中配合索引下推通过索引一并完成判断。
join 查询优化的更多相关文章
- join查询优化
更新使用过滤条件中包括自身的表 此方法不能无法在mysql中使用 `UPDATE user1 SET over='齐天大圣' WHERE user1.user_name IN ( SELECT b.u ...
- Presto上使用SQL遇到的一些坑
本文转载自:https://segmentfault.com/a/1190000013120454?utm_source=tag-newest 最近换了新工作,在数据处理方面,公司是用Presto连接 ...
- 性能优化之永恒之道(实时sql优化vs业务字段冗余vs离线计算)
在项目中,随着时间的推移,数据量越来越大,程序的某些功能性能也可能会随之下降,那么此时我们不得不需要对之前的功能进行性能优化.如果优化方案不得当,或者说不优雅,那可能将对整个系统产生不可逆的严重影响. ...
- MySQL优化之路
一.Mysql的存储原理 索引相关 本质 索引是帮助MySQL高效获取数据的排好序的数据结构 建索引,提高数据检索的效率,降低数据库的IO成本: 通过索引列对数据进行排序,降低数据排序的成本, ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- SQL查询优化 LEFT JOIN和INNER JOIN
作者:VerySky 推荐:陈敬(Cathy) SQL查询优化 LEFT JOIN和INNER JOIN 1,连接了八个数据库表,而且全部使用LEFT JOIN,如下所示: Resource_Reso ...
- Mysql查询优化器之关于JOIN的优化
连接查询应该是比较常用的查询方式,连接查询大致分为:内连接.外连接(左连接和右连接).自然连接 下图展示了 LEFT JOIN.RIGHT JOIN.INNER JOIN.OUTER JOIN 相关的 ...
- mysql 查询优化~join算法
一简介:参考了几位师兄,尤其是M哥大神的博客,让我恍然大悟,赶紧记录下二 原理: mysql的三种算法 1 Simple Nested-Loop Join 将驱动表/外部表的结果集作为循环基础数据,然 ...
- MySql left join 多表连接查询优化语句
先过滤条件然后再根据表连接 同时在表中建立相关查询字段的索引这样在大数据多表联合查询的情况下速度相当快 创建索引: create index ix_register_year ON dbo.selec ...
随机推荐
- C# 并发编程 (异步编程与多线程)
并发:同时做多件事情 多线程:并发的一种形式,它采用多个线程来执行程序. 并行处理:把正在执行的大量的任务分割成小块,分配给多个同时运行的线程.并行处理是多线程的一种,而多线程是并发的一种. 异步编程 ...
- Unity UI适配 之 GridLayoutGroup组件下的内容适配(进度条适配)
好久没有更新博客了,蓝廋啊. 今天写一写关于GripLayoutGroup组件的屏幕适配问题,以在ARPG游戏中常用的经验条适配来举例子,以此来加深自己的记忆,以便在下次需要制作该功能时能够快速完成. ...
- Qt学习笔记-更高级的文本编辑器-完善第一版-gif动画
现在的浏览器大多都有动作图标,现在我们也为浏览器加上图标. 在网上搜索到了几个ico的图标.现在直接拿来用. 首先创建资源文件. 在工程名上鼠标右键,选择add new 然后再选择 Qt Resour ...
- JQuery特点:
轻量级 强大的选择器 出色的DOM封装 可靠的事件处理机制 完善的Ajax 出色的浏览器兼容性 丰富的插件支持 完善的文档 支持链式操作
- HTML颜色
- Mono for android 访问Webservice和WebApi以及获取和解析JSON
先看效果,注意:(1)这里由于我的模拟器不支持中文输入,所以,对于这张效果图,我是直接在代码中写死了我的查询城市,在下面的代码中我是没有把要查询的城市写死的. (2)读者要想成功使用本示例的所有代码的 ...
- 如何在Elasticsearch中解析未分配的分片(unassigned shards)
一.精确定位到有问题的shards 1.查看哪些分片未被分配 curl -XGET localhost:9200/_cat/shards?h=index,shard,prirep,state,unas ...
- “==”和equals的区别
区别: (1)比较基本数据类型时 只能采用"==",比较的是数值; (2)当比较引用数据类型时 "==" 比较的是引用对象的内存地址; 而equals分两种情况 ...
- strings包
http://docscn.studygolang.com/pkg/strings/ Golang官方对strings包的介绍,strings包都是关于字符串的操作 常用的函数: 判断s1中是否包含字 ...
- C语言指针的大小
C语言指针的大小 今天看到一道题目是这样的,写出以下变量在32位设备上的大小(占多少个字节) 然后其中就有一些指针类型的数据,那么我们知道在C语言中指针的大小都是一样的,不管是有数据类型的还是void ...