关于c语言单项链表尾添加
犹豫了几天,看了很多大牛写的关于c语言链表,感触很多,终于下定决心,把自己对于链表的理解随之附上,可用与否,自行裁夺。由于作者水平有限也是第一次写,不足之处,竭诚希望得到各位大神的批评指正。制作不易,不喜勿喷,谢谢!!!
在正文开始之前,我先对数组和链表进行简单的对比分析。
链表也是一种很常见的数据结构,不同于数组的是它是动态进行存储分配的一种结构。数组存放数据时,必须要事先知道元素的个数。举个例子,比如一个班有40个人,另一个班有100个人,如果要用同一个数组先后来存放这两个班的学生数据,那么必须得定义长度为100的数组。如果事先不确定一个班的人数,只能把数组定义的足够大,以能存放任何班级的学生数据。这样就很浪费内存,而且数组对于内存的要求必须是是连续的,数据小的话还好说,数据大的话内存分配就会失败,数组定义当然也就失败。还有数组对于插入以及删除元素的效率也很低这就不一一介绍了。然而链表就相对于比较完美,它很好的解决了数组存在的那些问题。它储存数据时就不需要分配连续的空间,对于元素的插入以及删除效率就很高。可以说链表对于内存就是随用随拿,不像数组要事先申请。当然,有优点就必然有缺点,就比如说链表里每一个元素里面都多包含一个地址,或者说多包含一个存放地址的指针变量,所以内存开销就很大。还有因为链表的内存空间不是连续的,所以想找到其中的某一个数据就没有数组那么方便,必须先得到该元素的上一个元素,根据上一个元素提供的下一元素地址去找到该元素。所以不提供“头指针”(下文中“头指针”为“PHead”),那么整个链表将无法访问。链表就相当于一条铁链一环扣一环(这个稍后会详细的说)。
链表
上面我提到过链表是动态进行存储分配的一种结构。链表中的每一个元素称为“结点”,每个结点都包括两部分:一部分为用户需要的实际数据,另一部分为下一结点的地址。链表有一个“头指针(PHead)”变量,存放着一个地址,该地址指向第一个结点,第一个结点里面存放着第二个结点的地址,第二个结点又存放着第三个结点地址。就这样头指针指向第一个结点,第一个结点又指向第二个......直到最后一个结点。最后一个结点不再指向其他结点,地址部分存放一个“NULL”。 见下图:(表中有一个尾指针(PEnd)其作用后面会解释)
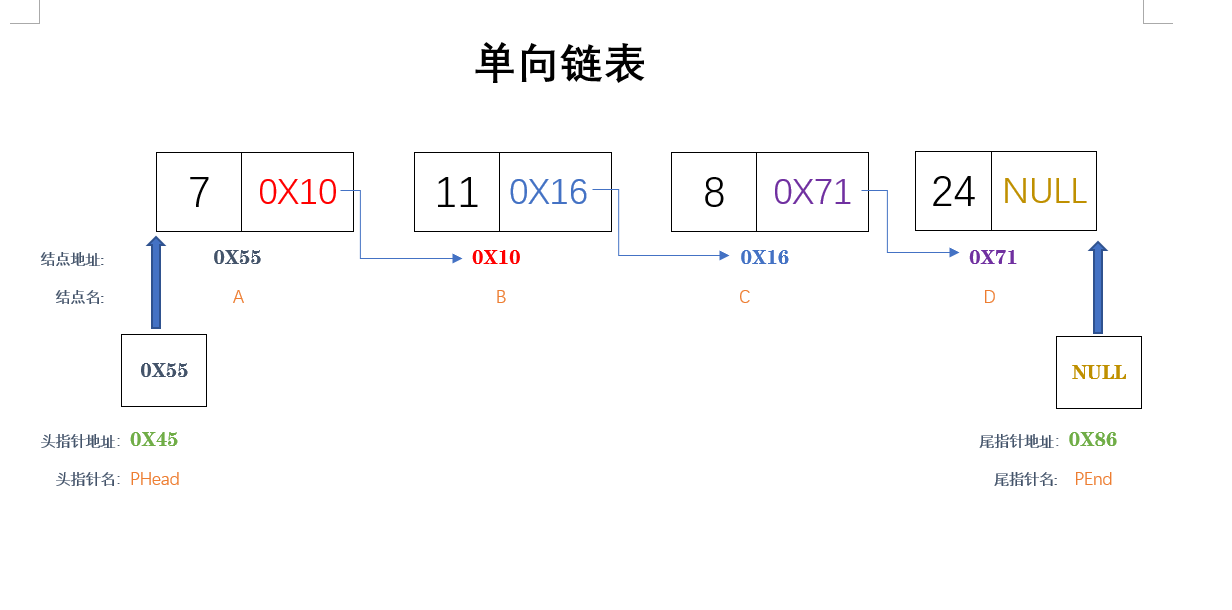
c语言单项链表尾添加整体代码如下:(详解附后)
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h> //函数声明
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int shu_ju);
//尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD, int shu_ju);
//释放链表
void shi_fang_lian_biao(struct NODE* PHEAD);
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd);
//输出链表
void shu_chu(struct NODE* PHEAD); //定义一个链表结构体
struct NODE
{
int shu_ju; //用户需要的实际数据
struct NODE* PNext; //下一结点的地址 }; int main(void)
{
//创建头尾指针
struct NODE* PHead = NULL;
struct NODE* PEnd = NULL; //尾添加
wei_tian_jia(&PHead, &PEnd, 17);
wei_tian_jia(&PHead, &PEnd, 21);
wei_tian_jia(&PHead, &PEnd, 34);
wei_tian_jia(&PHead, &PEnd, 8);
wei_tian_jia(&PHead, &PEnd, 24); //尾添加(没有尾指针)
//wei_tian_jia_(&PHead, 23);
//wei_tian_jia_(&PHead, 17);
//wei_tian_jia_(&PHead, 11); //输出链表
shu_chu(PHead); //释放链表
//shi_fang_lian_biao(PHead); //释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
shi_fang_lian_biao_free(&PHead, &PEnd); system("pause");
return 0;
}
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//节点赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL; //把结点连起来
if (NULL == *PHEAD) // 因为PHEAD如果是NULL的话 PEND也就是NULL 所以条件里面不必要写
{
*PHEAD = PTEMP;
*PEND = PTEMP;
}
else
{
(*PEND)->PNext = PTEMP;
*PEND = PTEMP; }
}
} //尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL)
{
//结点成员赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL; //把结点连一起
if (NULL == *PHEAD1)
{
*PHEAD1 = PTEMP;
}
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
} } } //输出链表
void shu_chu(struct NODE* PHEAD)
{
while (PHEAD != NULL)
{
printf("%d\n", PHEAD->shu_ju);
PHEAD = PHEAD->PNext; } } //释放链表
void shi_fang_lian_biao(struct NODE* PHEAD)
{
struct NODE* P = PHEAD;
while (PHEAD != NULL)
{
struct NODE* PTEMP = P;
P = P->PNext;
free(PTEMP);
}
free(PHEAD); }
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd)
{ while (*PHEAD != NULL)
{
struct NODE* PTEMP = *PHEAD;
*PHEAD = (*PHEAD)->PNext;
free(PTEMP);
}
*PHEAD = NULL;
*PHEAD = NULL; }
部分代码详解:
(再次申明:由于作者水平有限,所以有的变量名用的拼音。见笑,莫怪!!!为了简单明了,方便起见,我定义了一个实际数据。)

“头指针”(PHead)以及“尾指针”(PEnd):

头指针很好理解指向首结点用于遍历整个数组,而尾指针呢?我们先看下面两段代码一段是有尾指针的一段是没有尾指针的:
显然这是一段有尾指针的代码。这里的思想就是当写入第一个成员进链表的时候,此时链表就一个成员,即是头(PHEAD),也是尾(PEND),当写入第二个成员的时候,链表头(PHEALD)不动链表尾(PEND)向后移,指向最后一个结点。
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU)
{
//创建一个结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//节点成员赋值(一定要每个成员都要赋值)
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL; //把结点连起来
if (NULL == *PHEAD) // 因为PHEAD如果是NULL的话 PEND也就是NULL 所以条件里面不必要写
{
*PHEAD = PTEMP;
*PEND = PTEMP;
}
else
{
//把尾指针向后移
(*PEND)->PNext = PTEMP;
*PEND = PTEMP; } } }
那么下面这段代码是没有尾指针的。它的思想就是头指针一直指向第一个结点,然后通过遍历来找到最后一个结点,从而使最后一个结点里面的指针指向所要插入的元素。
//尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL)
{
//结点成员赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL; //把结点连一起
if (NULL == *PHEAD1)
{
*PHEAD1 = PTEMP; }
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
} } }
我把上面代码里面的一段摘出来说明一下。
这段代码里面可以看到我又定义了一个PTEMP2指针变量,为什么呢?前面我提到过没有尾指针的时候添加结点的思想就是要遍历数组,从而找到最后一个结点然后让它指向我们要插入的结点,如果没有这个PHEAD2,我们遍历完链表以后我们的头指针PHEAD1就已经指向了最后一个结点了,单项链表如果头指针移动了,数据就会找不到了。所以我定义了一个中间变量装着头指针然后去遍历链表,让头指针永远指向链表的头。
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
}
可以看到有尾指针的代码和没有尾指针的代码里面,有尾指针的链表里面我每次添加完数据都让尾指针指向最后一个结点,然后通过尾指针来添加数据。而没有尾指针的链表里面每次添加数据都要通过循环来遍历链表找到最后一个结点然后指向所添加的结点。如果一个链表里面有几万个结点,每次都通过循环遍历链表来添加数据,那么速度就相对于有尾指针的链表慢很多。总而言之,还是看个人爱好吧。不管黑猫还是白猫能抓到耗子都是好猫。
#include <stdio.h>#include <stdlib.h>#include <malloc.h>
//函数声明//尾添加void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int shu_ju);//尾添加(没有尾指针)void wei_tian_jia_(struct NODE** PHEAD, int shu_ju);//释放链表void shi_fang_lian_biao(struct NODE* PHEAD);//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd);//输出链表void shu_chu(struct NODE* PHEAD);
//定义一个链表结构体struct NODE{int shu_ju; //用户需要的实际数据struct NODE* PNext; //下一结点的地址
};
int main(void){//创建头尾指针struct NODE* PHead = NULL;struct NODE* PEnd = NULL;
//尾添加wei_tian_jia(&PHead, &PEnd, 17);wei_tian_jia(&PHead, &PEnd, 21);wei_tian_jia(&PHead, &PEnd, 34);wei_tian_jia(&PHead, &PEnd, 8);wei_tian_jia(&PHead, &PEnd, 24);
//尾添加(没有尾指针)//wei_tian_jia_(&PHead, 23);//wei_tian_jia_(&PHead, 17);//wei_tian_jia_(&PHead, 11);
//输出链表shu_chu(PHead);
//释放链表//shi_fang_lian_biao(PHead);
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)shi_fang_lian_biao_free(&PHead, &PEnd);
system("pause");return 0;}
//尾添加void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU){//创建一个结点struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));if (PTEMP != NULL){//节点赋值PTEMP->shu_ju = SHU_JU;PTEMP->PNext = NULL;
//把结点连起来if (NULL == *PHEAD) // 因为PHEAD如果是NULL的话 PEND也就是NULL 所以条件里面不必要写{*PHEAD = PTEMP;*PEND = PTEMP;}else{(*PEND)->PNext = PTEMP;*PEND = PTEMP;
}
}}
//尾添加(没有尾指针)void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU){//创建结点struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL){//结点成员赋值PTEMP->shu_ju = SHU_JU;PTEMP->PNext = NULL;
//把结点连一起if (NULL == *PHEAD1){*PHEAD1 = PTEMP;}else {struct NODE* PTEMP2 = *PHEAD1;while (PTEMP2->PNext != NULL){PTEMP2 = PTEMP2->PNext;}PTEMP2->PNext = PTEMP;}
}
}
//输出链表void shu_chu(struct NODE* PHEAD){while (PHEAD != NULL){printf("%d\n", PHEAD->shu_ju);PHEAD = PHEAD->PNext;
}
}
//释放链表void shi_fang_lian_biao(struct NODE* PHEAD){struct NODE* P = PHEAD;while (PHEAD != NULL){struct NODE* PTEMP = P;P = P->PNext;free(PTEMP);}free(PHEAD);
}//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd){while (*PHEAD != NULL){struct NODE* PTEMP = *PHEAD; *PHEAD = (*PHEAD)->PNext;free(PTEMP);}*PHEAD = NULL;*PHEAD = NULL;
}
关于c语言单项链表尾添加的更多相关文章
- C语言之链表
这两天在复习C语言的知识,为了给下个阶段学习OC做准备,以下的代码的编译运行环境是Xcode5.0版本,写篇博文把昨天复习的C语言有关链表的知识给大家分享一下,以下是小菜自己总结的内容,代码也是按照自 ...
- 2分钟 sublime设置自动行尾添加分号并换行:
18:03 2016/4/162分钟 sublime设置自动行尾添加分号并换行:注意:宏文件路径要用反斜杠/,2个\\会提示无法打开宏文件.不需要绝对路径很简单利用宏定义:1.录制宏:由于是录制动作宏 ...
- sed命令给文本文件的每行的行首或者行尾添加文字
在每行的头添加字符,比如"HEAD",命令如下: sed 's/^/HEAD&/g' test.file 在每行的行尾添加字符,比如“TAIL”,命令如下: sed 's/ ...
- C语言习题 链表建立,插入,删除,输出
Problem B: C语言习题 链表建立,插入,删除,输出 Time Limit: 1 Sec Memory Limit: 128 MB Submit: 222 Solved: 92 [Subm ...
- sed在行首或者行尾添加内容
原文地址:http://www.cnblogs.com/ITEagle/archive/2013/06/20/3145546.html 用sed命令在行首或行尾添加字符的命令有以下几种: 假设处理的文 ...
- 在C语言结构体中添加成员函数
我们在使用C语言的结构体时,经常都是只定义几个成员变量,而学过面向对象的人应该知道,我们定义类时,不只是定义了成员变量,还定义了成员方法,而类的结构和结构体非常的相似,所以,为什么不想想如何在C语言结 ...
- vim 在行首 行尾添加字符
在行首添加字符: %s/^/your_word/ 在行尾添加字符 %s/$/your_word/
- c++刷题(27/100)反转单项链表,链表的倒数第k个
题目1:调整数组顺序使奇数位于偶数前面 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位 ...
- notepad++ 行首行尾添加字符
有一次要处理SQL,拿到了脚本.但是要将其写入java 代码中,要在行首和行尾添加上引号.利用notepad++进行编辑. $表示行尾,^表示行首. 如上图,就这样.很高效. 如果只是在行尾添加字符, ...
随机推荐
- Java基础教程——结构化编程
结构化编程 各结构的图示请参见: https://www.cnblogs.com/tigerlion/p/10703926.html 选择结构 |-if:如果 |-else:其他:此外:否则. pub ...
- java base64加解密
接上篇java Base64算法. 根据之前过程使用base64加解密,所以写成了工具类. 代码示例; public class Base64Util { private static Logger ...
- [Python]环境配置之pip加速
背景 学习 Python 的话,仅掌握标准库是远不够的,有很多好用的第三方库我们也需要用到的,比如,由鼎鼎大名的 K 神开发的爬虫必不可少的 requests 库,一般都是必装的库吧.安装第三方库当然 ...
- 【线程池】toString
java.util.concurrent.RejectedExecutionException: Task com.personal.practice.jvm.Jstacktest$1@7d605a5 ...
- Beta冲刺随笔——Day_Five
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 Beta 冲刺 这个作业的目标 团队进行Beta冲刺 作业正文 正文 其他参考文献 无 今日事今日毕 林涛: ...
- 整理一下dedecms的相关知识
dedecms更改数据库连接 文件 data/common.inc.php ------------------------------------------------------------ ...
- angular中datetime-local属性使用ng-model报错
项目需求是将年月日格式更改为年月日时分的格式展示,翻遍了整个项目没找到符合的组件,自己现敲一个也来不及,只好直接使用原生自带的组件--datetime-local.之前都是用的vue写项目,第一次接触 ...
- PyQt学习随笔:QTableWidget项sizeHint的作用以及与QHeadView的sectionResizeMode、ResizeToContents的关系
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 在学习QTableWidgetItem的sizeHint()方法时,Qt自带材料中介绍sizeHin ...
- 刷题记录:[GWCTF 2019]枯燥的抽奖
目录 刷题记录:[GWCTF 2019]枯燥的抽奖 知识点 php伪随机性 刷题记录:[GWCTF 2019]枯燥的抽奖 题目复现链接:https://buuoj.cn/challenges 参考链接 ...
- SASRec 实践
SASRec--2018,ICDM,论文<Self-Attentive Sequential Recommendation> 源代码链接:https://github.com/kang20 ...