深度学习---1cycle策略:实践中的学习率设定应该是先增再降
深度学习---1cycle策略:实践中的学习率设定应该是先增再降
本文转载自机器之心Pro,以作为该段时间的学习记录
深度模型中的学习率及其相关参数是最重要也是最难控制的超参数,本文将介绍 Leslie Smith 在设置超参数(学习率、动量和权重衰减率)问题上第一阶段的研究成果。具体而言,Leslie Smith 提出的 1cycle 策略可以令复杂模型的训练迅速完成。它表示在 cifar10 上训练 resnet-56 时,通过使用 1cycle,能够在更少的迭代次数下,得到和原论文相比相同、甚至更高的精度。
通过采用大学习率,我们可以在 70 个 epoch、不到 7000 次的迭代中,训练出准确率达到 93% 的模型(作为对比,原论文的训练共有约为 360 个 epoch、64000 次迭代)。
Jupyter Notebook记录了所有的相关实验。实验中使用了和原论文相同的数据扩张:我们对图片进行了随机水平翻转;除此之外,我们在图片每边加入了4像素的填充,并进行随机裁剪。这里我们做出了一点小调整:我们没有使用黑色的填充像素,而是使用了反射填充(reflection padding),因为fastai支持实现这种方式。 这个调整也许能解释为什么我们在使用和 Leslie 相同的超参数进行实验时,得到了比他稍好的结果。
大学习率
可以通过这篇文章学习如何实现Learning Rate Finder,这里简述如下:在开始训练模型的同时,从低到高地设置 学习率,直到损失(loss)变得失控为止。然后将损失和学习率画在一张图中,在损失持续下降、即将达到最小值前的范围上取一个值作为学习率。下例中,可以在 10^-2 到 3×10^-2 之间任意取一个值。
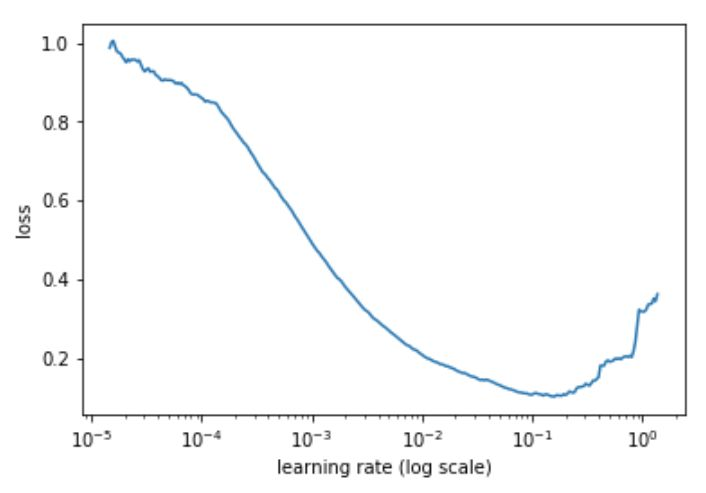
这里的思想和 Leslie 是一致的,他在论文中提出了一个很好的训练方法。
Leslie 建议,用两个等长的步骤组成一个 cycle:从很小的学习率开始,慢慢增大学习率,然后再慢慢降低回最小值。最大学习率应该根据 Learning Rate Finder 来确定,最小值则可以取最大值的十分之一。这个 cycle 的长度应该比总的 epoch 次数略小,在训练的最后阶段,可以将学习率降低到最小值以下几个数量级。
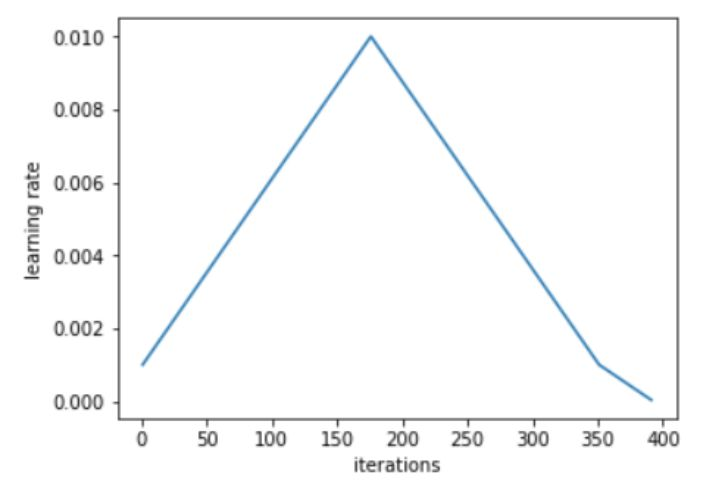
从小学习率开始训练模型并不新颖:使用较小的学习率来预热训练是一种常用的方法,这也正是 Leslie 第一阶段的研究目标。Leslie 并不建议直接从大学习率开始,相反,他认为应该从低到高,缓慢地线性提升学习率,然后再用相同的时间缓慢地降低回来。
Leslie 在实验中发现,在这个 cycle 的中间阶段,大学习率的效果类似于正则方法,可以抑制神经网络的过拟合。这是因为大学习率更偏好损失函数上相对平缓的极小值,而防止模型收敛到一个陡峭区域上。在 Leslie 的另一篇论文中,他通过使用 1cycle,发现近似 Hessian 的方法会有更小的学习率,这意味着 SGD 搜索的是一个更平坦的区域。
在训练的最后阶段,通过降低学习率直到彻底消失,可以得到损失函数平滑区域中相对陡峭的局部极小值。
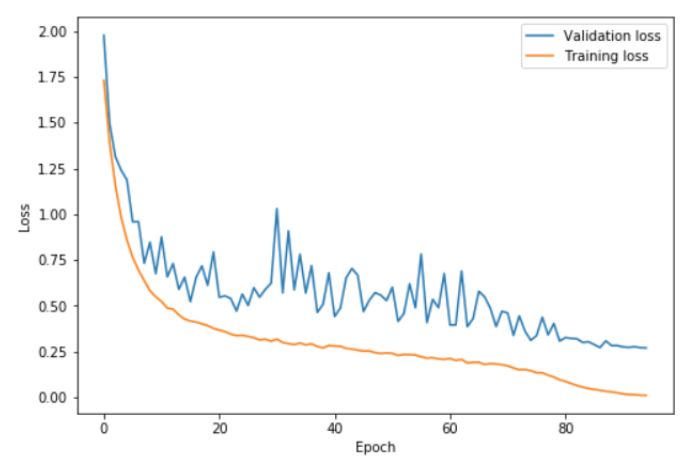
上图中,在 0 ~ 41 个 epoch 中,学习率从 0.08 提升到 0.8,在随后的 41 ~ 82 个 epoch 中,学习率降回 0.08,在最后的几次 epoch 中,学习率降低到 0.08 的百分之一。可以看到,在高学习率阶段(基本是 20 ~ 60 个 epoch),验证损失表现得相对不稳定。但重要的是,平均而言,训练误差和验证误差之间的距离并没有增大。只有在 cycle 的最后阶段,学习率接近为 0 时,才真正的出现了过拟合。
令人惊讶的是,通过 1cycle,我们甚至可以使用更高的最大学习率,即在根据 Learning Rate Finder 得到的图中,更接近曲线最低点。这种训练会相对更加危险,因为损失可能会骗你太远,以至于出现严重的偏差;这时,在采用更低的学习率前,可以尝试使用更长的 cycle:更长的预热过程应该会有所帮助。
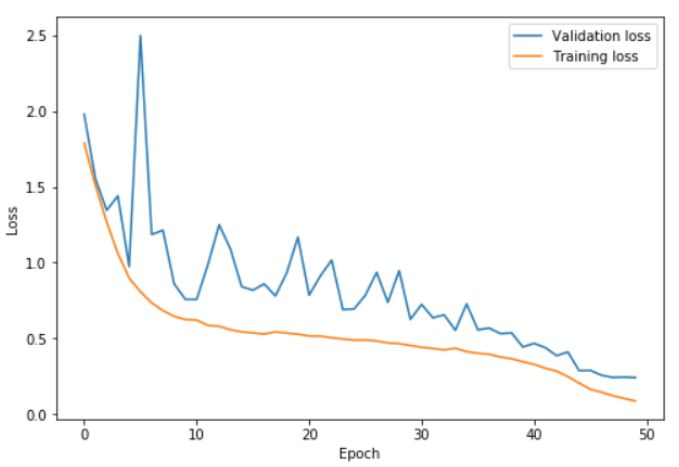
上图中,在 0 ~ 22.5 个 epoch 中,学习率从 0.15 增加到 3;在 22.5~45 个 epoch 中降回到 0.15,在最后的几次 epoch 中,学习率降低到 0.15 的百分之一。通过使用这些非常高的学习率,学习完成得更快,同时也防止了过拟合。训练误差和验证误差之间的差距一直保持在很低的水平,直到学习率接近为 0。通过使用 1cycle 策略,可以仅仅经过 50 次 epoch,就在 cifar10 上训练出一个准确率 92.3% 的 resnet-56;我们可以利用包含 70 个 epoch 的 cycle 得到 93% 的准确率。
作为对比,下图展示了使用更小的 cycle 以及更长收敛阶段的结果:
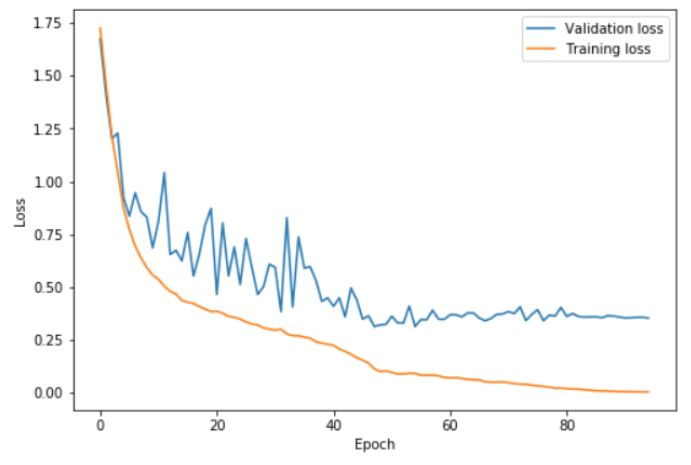
在这里,学习率变化的两个步骤在 42 个 epoch 中结束,剩下的训练过程中使用缓慢递减的学习率。这时验证误差不再下降,进而出现了越来越严重的过拟合现象,同时,准确率基本没有提升。
周期性动量
Leslie 在实验中还发现,在增大学习率的同时降低动量,可以得到更好的训练结果。这也印证了一个直觉:在训练中,我们希望 SGD 可以迅速调整到搜索平坦区域的方向上,因此就应该对新的梯度赋予更大的权重。Leslie 建议,在真实场景中,可以选取如 0.85 和 0.95 的两个值,在增大学习率的时候,将动量从 0.95 降到 0.85,在降低学习率的时候,再将动量重新从 0.85 提升回 0.95。
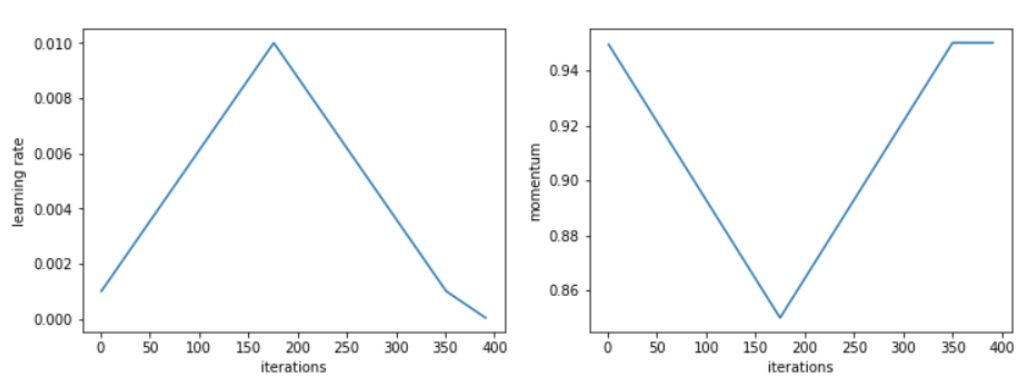
据 Leslie 表示,使用根据完整训练选取的最优动量,也可以得到相同的最终结果;但使用周期性动量时,我们不需要浪费时间去设立多个动量参数,然后进行多次完整训练来寻找最优值。
虽然使用周期性动量确实能得到稍好的训练结果,但我并没有复现出 Leslie 论文中使用常动量值和使用周期性动量时的差异。
其他参数的影响
在训练中,调节模型其他超参数的方式也会影响最优学习率。因此在使用 Learning Rate Finder 时,一定要保证训练是在相同条件下完成的。例:不同的 batch 大小或权重衰减对结果的影响如下。

可以利用这个性质来设置一些超参数,如去做那种衰减率:Leslie 建议,可以在几组权重衰减率上运行 Learning Rate Finder,在能够接受使用高最大学习率进行训练的结果中,选择最大的一个。我们实验中选择的是 10^-4。
Leslie 认为,在内存可接受范围内,batch 越大越好。而其他可能包含的超参数(如 drop-out)则可以通过和权重衰减相同的方法来调节,或者直接根据一次 cycle 的结果来判断效果。但无论如何——尤其是当你决定采用一个接近最大可能值的激进学习率时——一定要记住重跑 Learning Rate Finder。
高学习率的 1cycle 策略本身就是一种正则方法,所以在使用 1cycle 时,自然需要减少一些其他形式的常用正则项。但同它们相比,1cycle 的效率相对更高,因为在相当长的训练中,我们都使用了高学习率。
摘要:尽管近年以来,深度学习已经在图像、语音、视频处理的应用场景中取得了令人瞩目的成功,但绝大部分训练所使用的超参数都是非最优的,因此不必要的延长了训练时间。时至今日,超参数设置依然像一种魔法,需要依赖多年经验来完成。本文提出了一些设置超参数的高效方法,可以显著减少所需的训练时间,并提升模型的表现效果。具体而言,本文展示了如何检测出训练在验证/测试损失函数上轻微的欠拟合或过拟合,并给出了逼近最优平衡点的指导建议。在接下来的部分,本文讨论了如何通过增加/减少学习率/动量来加速训练过程。试验结果表明,在每个数据集和架构上平衡正则的各个方面极其重要。我们以权重衰减作为正则项为例,展示了其最优值和学习率及动量间的紧密联系。
深度学习---1cycle策略:实践中的学习率设定应该是先增再降的更多相关文章
- <深度学习优化策略-3> 深度学习网络加速器Weight Normalization_WN
前面我们学习过深度学习中用于加速网络训练.提升网络泛化能力的两种策略:Batch Normalization(Batch Normalization)和Layer Normalization(LN). ...
- Video Target Tracking Based on Online Learning—深度学习在目标跟踪中的应用
摘要 近年来,深度学习方法在物体跟踪领域有不少成功应用,并逐渐在性能上超越传统方法.本文先对现有基于深度学习的目标跟踪算法进行了分类梳理,后续会分篇对各个算法进行详细描述. 看上方给出的3张图片,它们 ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 【神经网络与深度学习】Caffe部署中的几个train-test-solver-prototxt-deploy等说明
1:神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正 ...
- 【深度学习篇】--神经网络中的调优一,超参数调优和Early_Stopping
一.前述 调优对于模型训练速度,准确率方面至关重要,所以本文对神经网络中的调优做一个总结. 二.神经网络超参数调优 1.适当调整隐藏层数对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比 ...
- 【动手学深度学习】Jupyter notebook中 import mxnet出错
问题描述 打开d2l-zh目录,使用jupyter notebook打开文件运行,import mxnet 出现无法导入mxnet模块的问题, 但是命令行运行是可以导入mxnet模块的. 原因: 激活 ...
- 动手学深度学习17-kaggle竞赛实践小项目房价预测
kaggle竞赛 获取和读取数据集 数据预处理 找出所有数值型的特征,然后标准化 处理离散值特征 转化为DNArray后续训练 训练模型 k折交叉验证 预测样本,并提交结果 kaggle竞赛 本节将动 ...
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- 5 TensorFlow实战Google深度学习框架一书中的错误两处(交叉熵定义有误)
第一处: 书中62页定义的交叉熵函数定义有误,虽然这个所谓交叉熵的数值能够减少,但是是不能提升预测性能的,因为定义就错了. 我已经将预测过程可视化,直接将交叉熵改为我的,或者用原书的,就可以看到预测结 ...
随机推荐
- Jenkins Ansible GitLab 自动化部署
Jenkins Ansible GitLab 自动化部署 DevOps https://www.cnblogs.com/yangjianbo/articles/10393765.html https: ...
- 安装 Angular Material UI
文档 调色板 安装 ng add @angular/material ? Choose a prebuilt theme name, or "custom" for a custo ...
- JavaScript高级-类的使用
1.面向过程与面向对象 1.1面向过程 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候再一个一个的依次调用就可以了. 1.2面向对象 面向对象是把事务分解成为一个 ...
- 深入解析 HTTP 缓存控制
缓存(Cache)是计算机领域里的一个重要概念,是优化系统性能的利器. 由于链路漫长,网络时延不可控,浏览器使用 HTTP 获取资源的成本较高.所以,非常有必要把"来之不易"的数据 ...
- Elasticsearch CRUD基本操作
前言 本次我们聊一聊Elasticsearch的基本操作CRUD,他跟我们常用的关系型数据库的操作又有什么不一样的地方呢?今天我们就来好好讲解一番. 说明 本次演示用的版本是7.11. 工具可以使用K ...
- Django Admin 图片路径设置显示为图片(imageField显示方法设置)
一 使用环境 开发系统: windows IDE: pycharm 数据库: msyql,navicat 编程语言: python3.7 (Windows x86-64 executable in ...
- 搭建Elasticsearch可视化界面 Kibana
前言 每一个版本的es都有一个对应的Kibana版本,建议和es相同版本,官网地址: 点击进入下载地址 步骤 1.解压 tar -zxvf kibana-7.2.0-linux-x86_64 2.修改 ...
- 关于C++中构造函数的常见疑问
基本概念 我们已经知道在定义一个对象时,该对象会根据你传入的参数来调用类中对应的构造函数.同时,在释放这个对象时,会调用类中的析构函数.其中,构造函数有三种,分别是默认构造函数,有参构造函数和拷贝构造 ...
- c++ vector对象
下面随笔讲解c++ vector对象. vector对象 为什么需要vector? 封装任何类型的动态数组,自动创建和删除. 数组下标越界检查. 封装的如ArrayOfPoints也提供了类似功能,但 ...
- Salesforce LWC学习(三十一) Quick Action适配
本篇参考:https://www.lightningdesignsystem.com/components/modals/ 随着salesforce lwc的优化,越来越多的项目从aura转到了lwc ...