【源码】Python3使用Requests抓取和检测电光代理API,并查询ip代理是否成功
电光代理成立后,做一篇笔记,记录我使用Requests抓取和测试电光代理的方法
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
首先点击获取电光代理(需要支付少量费用,总体质量处于市面上开放代理第一梯队)
请获取一个属于您的代理API,如我的是 https://api.super.xyz/oNtl30618YdXol/1000-china-0-http-high_anonymous-json (测试链接,请以实际链接为准)
点击下载github仓库的源码
下载源码后,按照如下方法运行该程序
#使用方法(以没有安装Python3虚拟环境的Windows为例)
进入命令窗口
1.安装虚拟环境 pip install virtualenv(Linux和MacOS使用 pip3 install virtualenv)
2.在项目目录下创建虚拟环境 virtualenv venv
3.激活虚拟环境 venv\Scripts\activate(Linux和MacOS使用 . venv/bin/activate)
4.激活后安装所需依赖 pip install -r requirements.txt(Linux和MacOS使用 pip3 install -r requirements.txt)
5.编辑ip.py文件,将64行链接改为您获取的代理API地址(此处API为电光代理返回的JSON格式,如果您未修改代码,暂时只能用电光代理https://www.cyberlight.xyz/ip )(如果您是开发者,代码可自行编辑,支持请求任何类型的API)
6.运行该程序即可 python ip.py(Linux和MacOS使用 python3 ip.py)
7.运行程序后,如果您的API设置返回http代理,请选择1,如果设置返回https代理,请选择2
运行示例
操作完前5步后,运行该程序

由于我设置的代理类型为http,在此处输入1
程序将自动运行

前半部分显示了电光代理提取数、有效ip数
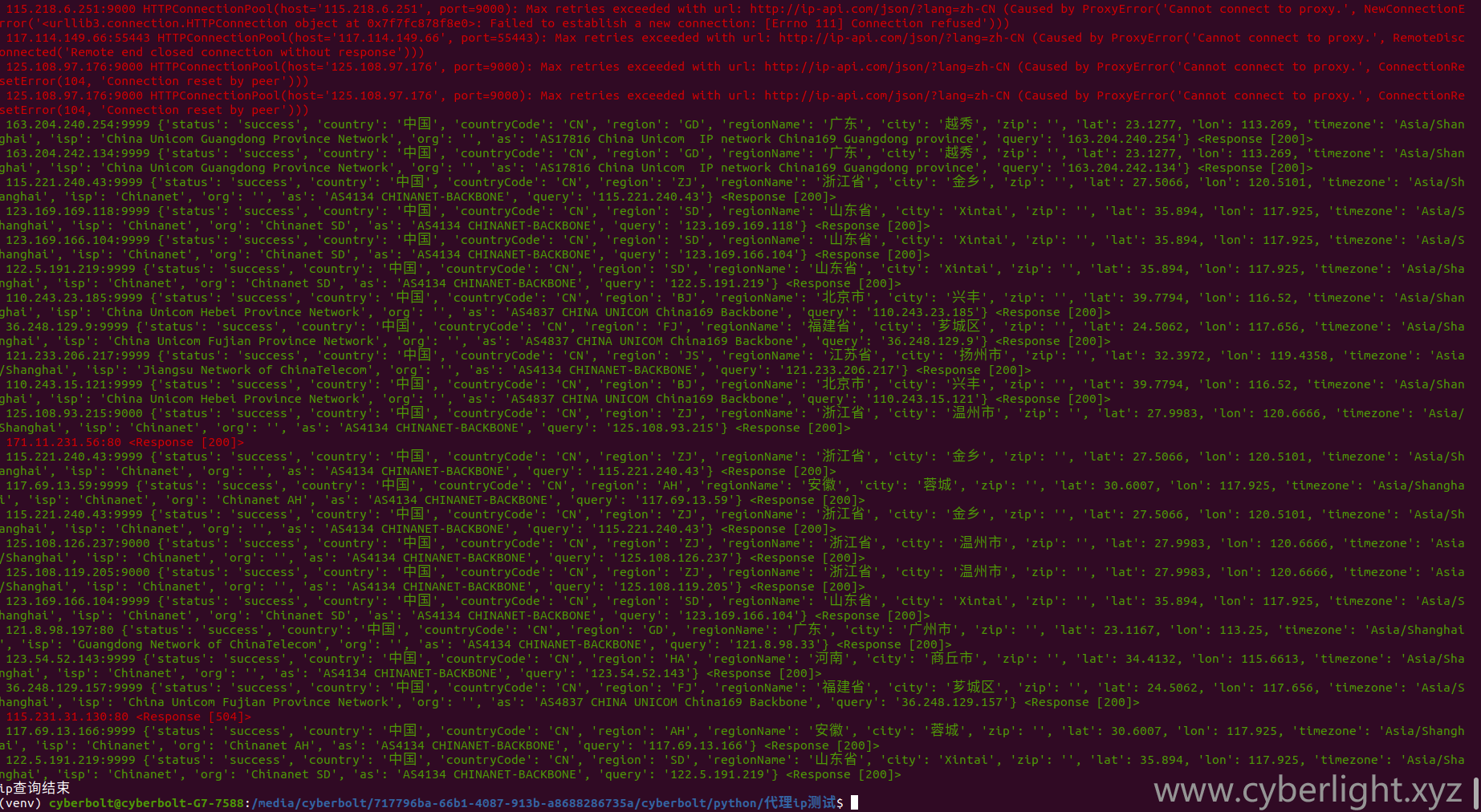
后半部分是随机测试30个ip是否代理成功,以及查询对应的地址(此处只能检测http代理的地址,若是https代理,请自行更换129行测试源地址为https可用的检测地址)
如果您使用该源码测试代理时有任何疑问,欢迎在评论区留言哦!
该项目源码
import requests
import random
import telnetlib
import threading
import time
#浏览器请求头,用于请求访问
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#多线程锁
lock=threading.Lock()
#arr是被分割的list,n是每个chunk中含n元素。
def chunks(arr, n):
return [arr[i:i+n] for i in range(0, len(arr), n)]
class Ip:
#构造方法
def __init__(self, proxy_type):
#初始化电光代理API(JSON格式) #此API仅为测试链接,需要输入实际有效API
self.api_json = 'https://api.super.xyz/oNtl30618YdXol/1000-china-0-http-high_anonymous-json'
self.ips = [] #储存有效ip的列表
self.proxy_type = proxy_type #代理类型
#抓取并测试ip的方法
def get_api(self):
temporary = requests.get(self.api_json).json()['proxy'] #获取API的ip
proxy_lists = chunks(temporary, 20) #将大列表分成小列表,每个列表含20个元素
#多线程检测ip
print('正在检测代理')
ts = [] #新建列表,用于存放所有线程
for proxy_list in proxy_lists: #遍历每个ip列表
t = threading.Thread(target=self.test, args=(proxy_list,)) #创建线程
t.start() #线程运行
ts.append(t) #将线程添加到ts
#等待线程结束
for t in ts: #遍历每个线程
t.join() #等待线程结束
print('代理检测结束,检测总数:' + str(len(temporary)) + ',有效数量:' + str(len(self.ips)))
#ip测试方法
def test(self, proxy_list):
#检测有效的ip
for ip in proxy_list: #遍历每个ip
address, port = ip.split(':') #分割ip和端口
try:
telnetlib.Telnet(address,port,timeout=0.4) #检测代理ip是否有效,0.4秒超时
print("\033[32m" + str(ip) + "\033[0m") #输出绿色字体 #仅Linux有效
self.ips.append(ip) #添加到列表
except:
print("\033[31m" + str(ip) + "\033[0m") #输出红色字体 #仅Linux有效
#多线程运行select_ip_imformation 方法
def select_start(self):
ts = [] #新建列表,用于存放所有线程
for i in range(30): #随机查询30个ip
t = threading.Thread(target=self.select_ip_imformation, args=()) #创建线程
t.start() #线程运行
ts.append(t) #将线程添加到ts
#等待线程结束
for t in ts: #遍历每个线程
t.join() #等待线程结束
print('ip查询结束')
#查询代理ip的地址 方法
def select_ip_imformation(self):
ip = random.choice(self.ips) #随机选取一个ip
#输出查询的ip信息,并删除超时ip
#proxies为代理ip, headers为随机请求头, timeout超时时间为10秒
try:
r = requests.get("http://ip-api.com/json/?lang=zh-CN",
proxies = { self.proxy_type : self.proxy_type + '://' + ip },
headers = {'User-Agent': random.choice(user_agent)}, timeout = 10 )
except Exception as e:
r = str(e)
pass
#输出 查询到的ip信息 和 查询失败的信息
if hasattr(r, 'status_code') and r.status_code == 200: #如果 r对象中有status_code 且 返回200
try: #检测r是否有json
print("\033[32m" + ' ' + str(ip) + ' ' + str(r.json()) + ' ' + str(r) + "\033[0m") #输出绿色字体 #仅Linux有效
except: #如果没有返回json
print("\033[31m" + ' ' + str(ip) + ' ' + str(r) + "\033[0m") #输出红色字体 #仅Linux有效
pass
else: #如果查询失败
print("\033[31m" + ' ' + str(ip) + ' ' + str(r) + "\033[0m") #输出红色字体 #仅Linux有效
def main():
print('代理API返回类型')
print('1.http')
print('2.https')
in_ = input('请输入序号选择API返回的代理类型:')
if in_ == '1':
proxy_type = 'http'
elif in_ == '2':
proxy_type = 'https'
else:
print('您的输入有误')
return main()
ip = Ip(proxy_type) #创建ip实例
ip.get_api() #获取 并 多线程检测ip
ip.select_start() #多线程查询ip地址
if __name__ == '__main__':
main()【源码】Python3使用Requests抓取和检测电光代理API,并查询ip代理是否成功的更多相关文章
- Python paramiko 修改源码实现用户命令抓取
paramiko 源码修改 paramiko主要用来实现ssh客户端.服务端链接,上一节我们说到了堡垒机,堡垒机内有一个需求是“用户行为审计”,在这里我们就可以通过修改paramiko内文件的源码来实 ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- Python3.x:抓取百事糗科段子
Python3.x:抓取百事糗科段子 实现代码: #Python3.6 获取糗事百科的段子 import urllib.request #导入各类要用到的包 import urllib import ...
- python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python3上运行通过的 selenium3 +firefox59.0.1(最新) BeautifulSoup requests 2.爬取目标网站,我的博客:https:/ ...
- python+requests抓取页面图片
前言: 学完requests库后,想到可以利用python+requests爬取页面图片,想到实战一下.依照现在所学只能爬取图片在html页面的而不能爬取由JavaScript生成的图片,所以我选取饿 ...
- 源码分析Kafka 消息拉取流程
目录 1.KafkaConsumer poll 详解 2.Fetcher 类详解 本节重点讨论 Kafka 的消息拉起流程. @(本节目录) 1.KafkaConsumer poll 详解 消息拉起主 ...
- Requests抓取有道翻译结果
Requests比urllib更加方便,抓取有道翻译非常的简单. import requests class YouDao(): def __init__(self,parm): ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- python3+beautifulSoup4.6抓取某网站小说(一)爬虫初探
本次学习重点: 1.使用urllib的request进行网页请求,获取当前url整版网页内容 2.对于多级抓取,先想好抓取思路,再动手 3.BeautifulSoup获取html网页中的指定内容 4. ...
随机推荐
- Spring @Value注解使用${}进行注入(转)
原文:http://my.oschina.net/js99st/blog/632104 spring3中新增的@value注解 http://bijian1013.iteye.com/blog/202 ...
- Scala 基础(六):Scala变量 (三) 标识符
1 标识符概念 1) Scala 对各种变量.方法.函数等命名时使用的字符序列称为标识符 2) 凡是自己可以起名字的地方都叫标识符 2 标识符的命名规则 Scala中的标识符声明,基本和Java是一致 ...
- SQLAlchemy02 /SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
- Python之常用模块学习(一)
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- hihoCoder 1114 小Hi小Ho的惊天大作战:扫雷·一 最详细的解题报告
题目来源:小Hi小Ho的惊天大作战:扫雷·一 解题思路:因为只要确定了第一个是否有地雷就可以推算出后面是否有地雷(要么为0,要么为1,如果不是这两个值就说明这个方案行不通),如果两种可能中有一种成功, ...
- Python基础-类与对象
类的基本使用 class Person(): def __init__(self,name,age): self.name = name self.age = age def info(self): ...
- 【软件测试】Python自动化软件测试算是程序员吗?
今天早上一觉醒来,突然萌生一个念头,[软件测试]软件测试算是程序员吗?左思右想,总感觉哪里不对.做了这么久的软件测试,还真没深究过这个问题. 基于,内事问百度的准则: 结果…… 我刚发 ...
- three.js 数学方法之Box3
从今天开始郭先生就会说一下three.js 的一些数学方法了,像Box3.Plane.Vector3.Matrix3.Matrix4当然还有欧拉角和四元数.今天说一说three.js的Box3方法(B ...
- 使用SQL语句进行数据复制
使用SQL语句对数据或者表进行复制,一般用于两张表结构相同的时候使用. SQL Server中,如果目标表存在: insert into 目标表 select * from 原表; SQL Serve ...
- C++语法小记---继承中的构造和析构顺序
继承中构造和析构的顺序 先父母,后客人,最后自己 静态变量和全局变量在最开始 析构和构造的顺序完全相反 #include <iostream> #include <string> ...