graph attention network(ICLR2018)官方代码详解(te4nsorflow)
论文地址:https://arxiv.org/abs/1710.10903
代码地址: https://github.com/Diego999/pyGAT
我并没有完整看过这篇论文,但是在大致了解其原理之后就直接看了代码= =。
接下来我将从代码的整个流程开始讲解,首先解析的是不用稀疏矩阵存储的:
使用的数据集:Cora dataset
Cora数据集简要介绍:
图节点数:2708
每个节点的特征维度:1433
邻接矩阵:(2708,2708),关系表示的是论文之间的引用关系
类别数:7
目录结构:

相关的包:
import numpy as np
import pickle as pkl
import networkx as nx
import scipy.sparse as sp
from scipy.sparse.linalg.eigen.arpack import eigsh
import sys
import time
import numpy as np
import tensorflow as tf
网络需要的数据是什么?
在utils文件下的process.py中:
def load_data(dataset_str): # {'pubmed', 'citeseer', 'cora'}
"""Load data."""
names = ['x', 'y', 'tx', 'ty', 'allx', 'ally', 'graph']
objects = []
for i in range(len(names)):
with open("data/ind.{}.{}".format(dataset_str, names[i]), 'rb') as f:
if sys.version_info > (3, 0):
objects.append(pkl.load(f, encoding='latin1'))
else:
objects.append(pkl.load(f))
x, y, tx, ty, allx, ally, graph = tuple(objects)
test_idx_reorder = parse_index_file("data/ind.{}.test.index".format(dataset_str))
test_idx_range = np.sort(test_idx_reorder)
if dataset_str == 'citeseer':
# Fix citeseer dataset (there are some isolated nodes in the graph)
# Find isolated nodes, add them as zero-vecs into the right position
test_idx_range_full = range(min(test_idx_reorder), max(test_idx_reorder)+1)
tx_extended = sp.lil_matrix((len(test_idx_range_full), x.shape[1]))
tx_extended[test_idx_range-min(test_idx_range), :] = tx
tx = tx_extended
ty_extended = np.zeros((len(test_idx_range_full), y.shape[1]))
ty_extended[test_idx_range-min(test_idx_range), :] = ty
ty = ty_extended
features = sp.vstack((allx, tx)).tolil()
features[test_idx_reorder, :] = features[test_idx_range, :]
adj = nx.adjacency_matrix(nx.from_dict_of_lists(graph))
labels = np.vstack((ally, ty))
labels[test_idx_reorder, :] = labels[test_idx_range, :]
idx_test = test_idx_range.tolist()
idx_train = range(len(y))
idx_val = range(len(y), len(y)+500)
train_mask = sample_mask(idx_train, labels.shape[0])
val_mask = sample_mask(idx_val, labels.shape[0])
test_mask = sample_mask(idx_test, labels.shape[0])
y_train = np.zeros(labels.shape)
y_val = np.zeros(labels.shape)
y_test = np.zeros(labels.shape)
y_train[train_mask, :] = labels[train_mask, :]
y_val[val_mask, :] = labels[val_mask, :]
y_test[test_mask, :] = labels[test_mask, :]
print(adj.shape)
print(features.shape)
return adj, features, y_train, y_val, y_test, train_mask, val_mask, test_mask
不管怎么变化,我们需要得到的是:
邻接矩阵:(2708,2708),需要注意的是邻接矩阵是由nx.adjacency_matrix(nx.from_dict_of_lists(graph))获得,其中graph是引用关系组成的字典,比如:
{
1:[2,3],
4:[6,7,8],
}
还需要注意的是该函数返回的稀疏矩阵的存储,是一个coc_matrix:
(0, 1) 1
(0, 30) 1
(0, 33) 1
(0, 99) 1
第一个元组表示不为0的值在数组中出现的(行、列),第二个值表示具体的值。看一个例子:

三要素:数据、行,列索引、形状。
特征:(2708,1433)
训练集、验证集、测试集标签:维度都是(2708,7).。注意:tensorflow中的标签需要进行one-hot编码,才能够使用交叉熵进行计算,而pytorch中是不用的。
掩码:掩码的作用就是选取部分节点进行训练、测试和验证,具体操作是:
idx_test = test_idx_range.tolist()
idx_train = range(len(y))
idx_val = range(len(y), len(y)+500) train_mask = sample_mask(idx_train, labels.shape[0])
val_mask = sample_mask(idx_val, labels.shape[0])
test_mask = sample_mask(idx_test, labels.shape[0])
其中sample_mask函数代码,位于process.py中:
def sample_mask(idx, l):
"""Create mask."""
mask = np.zeros(l)
mask[idx] = 1
return np.array(mask, dtype=np.bool)
也就是先根据l的大小生成一个形状相同的数组,然后根据Idx的值将指定行的值变为True。请看以下例子:
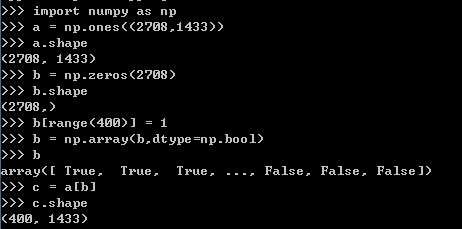
如何对初始数据进行处理?
adj, features, y_train, y_val, y_test, train_mask, val_mask, test_mask = process.load_data(dataset)
features, spars = process.preprocess_features(features) nb_nodes = features.shape[0] #节点数
ft_size = features.shape[1] #特征维度
nb_classes = y_train.shape[1] #类别数 adj = adj.todense() features = features[np.newaxis]
adj = adj[np.newaxis]
y_train = y_train[np.newaxis]
y_val = y_val[np.newaxis]
y_test = y_test[np.newaxis]
train_mask = train_mask[np.newaxis]
val_mask = val_mask[np.newaxis]
test_mask = test_mask[np.newaxis] biases = process.adj_to_bias(adj, [nb_nodes], nhood=1)
使用process.preprocess_features(features)对特征进行处理:
def preprocess_features(features):
"""Row-normalize feature matrix and convert to tuple representation"""
rowsum = np.array(features.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
features = r_mat_inv.dot(features)
return features.todense(), sparse_to_tuple(features)
我们获得的features是由:sp.vstack((allx, tx)).tolil()得到的,也就是一个lil_matrix。lil_matrix基于行连接存储的稀疏矩阵,看以下例子:
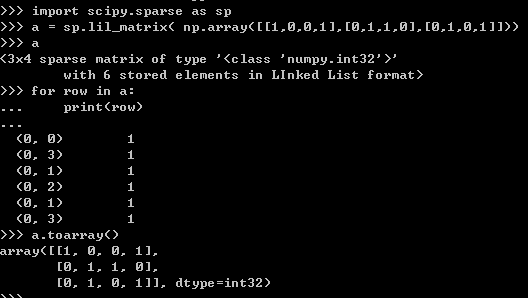
回到上面对特征进行处理的函数,具体步骤为:
- 对每一行求和
- 计算每个值的倒数,然后展开成一维数组
- 将inf类型的值置为0
- 生成一个对角矩阵,对角的值为一维数组的值,其余的为0
- 最后与特征进行np.matmul
- 使用todense()函数lil_matrix还原为原始矩阵
接下来我们同样将adj转换为原始的矩阵,并且使用np.newaxis新增一个维度:
features;(2708,1433) ->(1,2708,1433)
adj:(2708,2708) -> (1,2708,2708)
y_train:(2708,7) -> (1,2708,7)
y_val:(2708,7) -> (1,2708,7)
y_test:(2708,7) -> (1,2708,7)
train_mask:(2708,.) -> (1,2708)
val_mask:(2708,.) -> (1,2708)
test_mask:(2708,.) -> (1,2708)
最后是:biases = process.adj_to_bias(adj, [nb_nodes], nhood=1)
看一下adj_to_bias(adj, [nb_nodes], nhood=1)函数:感觉是
def adj_to_bias(adj, sizes, nhood=1):
nb_graphs = adj.shape[0] #1
mt = np.empty(adj.shape) #(1,2708,2708)
for g in range(nb_graphs): #range(1)
mt[g] = np.eye(adj.shape[1]) #mt[0] = np.eye(2708) -> (2708,2708)
for _ in range(nhood): #range(1)
mt[g] = np.matmul(mt[g], (adj[g] + np.eye(adj.shape[1]))) #np.matmul((2708,2708),((2708,2708)+(2708,2708)))->(2708,2708)
for i in range(sizes[g]): #range(2078)
for j in range(sizes[g]): #range(2078)
if mt[g][i][j] > 0.0:
mt[g][i][j] = 1.0
return -1e9 * (1.0 - mt)
np.eye():生成一个对角矩阵,对角的值为1,其余地方为0。
这里要注意np.matmul的用法,看一个例子:
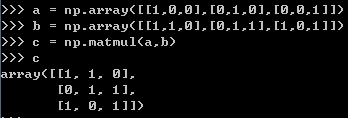
对应步骤:
- 生成一个空(1,2708,2708)的矩阵mt
- 将mt[0],也就是(2708,2708)变为对角值为1的对角矩阵
- 该对角矩阵和(adj[g] + np.eye(adj.shape[1]))进行np.matmul
- 然后将mt中大于0的元素置为1
- 最后返回-1e9*(1-mt),形状为(1,2708,2708)
可以看出该函数的作用就是为不相邻的两个节点间添加一个偏置项。
GAT模型是怎么建立的?
多头注意力:
在models文件夹下的gat.py中:
import numpy as np
import tensorflow as tf from utils import layers
from models.base_gattn import BaseGAttN class GAT(BaseGAttN):
def inference(inputs, nb_classes, nb_nodes, training, attn_drop, ffd_drop,
bias_mat, hid_units, n_heads, activation=tf.nn.elu, residual=False):
attns = []
for _ in range(n_heads[0]):
attns.append(layers.attn_head(inputs, bias_mat=bias_mat,
out_sz=hid_units[0], activation=activation,
in_drop=ffd_drop, coef_drop=attn_drop, residual=False))
h_1 = tf.concat(attns, axis=-1)
for i in range(1, len(hid_units)):
h_old = h_1
attns = []
for _ in range(n_heads[i]):
attns.append(layers.attn_head(h_1, bias_mat=bias_mat,
out_sz=hid_units[i], activation=activation,
in_drop=ffd_drop, coef_drop=attn_drop, residual=residual))
h_1 = tf.concat(attns, axis=-1)
out = []
for i in range(n_heads[-1]):
out.append(layers.attn_head(h_1, bias_mat=bias_mat,
out_sz=nb_classes, activation=lambda x: x,
in_drop=ffd_drop, coef_drop=attn_drop, residual=False))
logits = tf.add_n(out) / n_heads[-1] return logits
相关参数:
hid_units=[8]
n_heads=[8,1]
每个注意力头的输出为:(1,2708,8),h_1将每个注意头(共8个)的输出进行拼接得到:(1,2708,64)。
根据len(hid_units)=1,因此第2个for循环是没有被执行的,然后再进行一次多头注意力(1个注意力头)得到的输出out就是:(1,2708,7)
每一个注意力头:attn_head
接下来是重头,具体的注意力的实现,论文的核心也就是在这里了。
在utils文件夹下的layers.py中:
def attn_head(seq, out_sz, bias_mat, activation, in_drop=0.0, coef_drop=0.0, residual=False):
with tf.name_scope('my_attn'):
if in_drop != 0.0:
seq = tf.nn.dropout(seq, 1.0 - in_drop) seq_fts = tf.layers.conv1d(seq, out_sz, 1, use_bias=False) # simplest self-attention possible
f_1 = tf.layers.conv1d(seq_fts, 1, 1)
f_2 = tf.layers.conv1d(seq_fts, 1, 1)
logits = f_1 + tf.transpose(f_2, [0, 2, 1])
coefs = tf.nn.softmax(tf.nn.leaky_relu(logits) + bias_mat) if coef_drop != 0.0:
coefs = tf.nn.dropout(coefs, 1.0 - coef_drop)
if in_drop != 0.0:
seq_fts = tf.nn.dropout(seq_fts, 1.0 - in_drop) vals = tf.matmul(coefs, seq_fts)
ret = tf.contrib.layers.bias_add(vals) # residual connection
if residual:
if seq.shape[-1] != ret.shape[-1]:
ret = ret + conv1d(seq, ret.shape[-1], 1) # activation
else:
ret = ret + seq return activation(ret) # activation
有关于dropout和残差连接就不细讲了,一个是为了缓解过拟合问题,一个是为了缓解梯度消失问题。
步骤如下:
- 输入features:(1,2708,1433)
- 第一步对特征features卷积,得到seq_fts:(1,2708,8)
- 第二步分别对seq_fts进行卷积,得到f_1:(1,2708,1),f_2:(1,2708,1)
- 第三步将f_2调整形状为:(1,1,2708),利用广播机制与f_1相加得到logits:(1,2708,2708)
- 第四步加上偏置项biases_mat,我们注意到偏置项的值很小,是为了过滤掉和该节点不相邻的节点,因为考虑的是某节点和其邻居节点之间的注意力。并使用leakyrelu进行激活,最后经过softmax生成注意力得分coefs:(1,2708,2708)
- 第五步将注意力得分与seq_fts进行np.matmul得到带注意力得分的vals:(1,2708,8)
- 第六步:ret = tf.contrib.layers.bias_add(vals),这里我运行时是报错的,说没有什么TPU之类的,我将其注释掉了才运行成功(tensorflow1.14)
- 最后将ret进行激活:tf.nn.elu
那么为什么要这么做呢?
主要是如何对注意力进行建模,实际上f_1+f_2也就是(1,2708,1) * (1,1,2708),这里就计算了每个节点和其它节点之间的得分。
其它的一些相关?
GAT类继承了BasicAttn,我们看下BasicAttn类:
class BaseGAttN:
def loss(logits, labels, nb_classes, class_weights):
sample_wts = tf.reduce_sum(tf.multiply(tf.one_hot(labels, nb_classes), class_weights), axis=-1)
xentropy = tf.multiply(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels, logits=logits), sample_wts)
return tf.reduce_mean(xentropy, name='xentropy_mean') def training(loss, lr, l2_coef):
# weight decay
vars = tf.trainable_variables()
lossL2 = tf.add_n([tf.nn.l2_loss(v) for v in vars if v.name not
in ['bias', 'gamma', 'b', 'g', 'beta']]) * l2_coef # optimizer
opt = tf.train.AdamOptimizer(learning_rate=lr) # training op
train_op = opt.minimize(loss+lossL2) return train_op def preshape(logits, labels, nb_classes):
new_sh_lab = [-1]
new_sh_log = [-1, nb_classes]
log_resh = tf.reshape(logits, new_sh_log)
lab_resh = tf.reshape(labels, new_sh_lab)
return log_resh, lab_resh def confmat(logits, labels):
preds = tf.argmax(logits, axis=1)
return tf.confusion_matrix(labels, preds) ##########################
# Adapted from tkipf/gcn #
########################## def masked_softmax_cross_entropy(logits, labels, mask):
"""Softmax cross-entropy loss with masking."""
loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels)
mask = tf.cast(mask, dtype=tf.float32)
mask /= tf.reduce_mean(mask)
loss *= mask
return tf.reduce_mean(loss) def masked_sigmoid_cross_entropy(logits, labels, mask):
"""Softmax cross-entropy loss with masking."""
labels = tf.cast(labels, dtype=tf.float32)
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)
loss=tf.reduce_mean(loss,axis=1)
mask = tf.cast(mask, dtype=tf.float32)
mask /= tf.reduce_mean(mask)
loss *= mask
return tf.reduce_mean(loss) def masked_accuracy(logits, labels, mask):
"""Accuracy with masking."""
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy_all = tf.cast(correct_prediction, tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
mask /= tf.reduce_mean(mask)
accuracy_all *= mask
return tf.reduce_mean(accuracy_all) def micro_f1(logits, labels, mask):
"""Accuracy with masking."""
predicted = tf.round(tf.nn.sigmoid(logits)) # Use integers to avoid any nasty FP behaviour
predicted = tf.cast(predicted, dtype=tf.int32)
labels = tf.cast(labels, dtype=tf.int32)
mask = tf.cast(mask, dtype=tf.int32) # expand the mask so that broadcasting works ([nb_nodes, 1])
mask = tf.expand_dims(mask, -1) # Count true positives, true negatives, false positives and false negatives.
tp = tf.count_nonzero(predicted * labels * mask)
tn = tf.count_nonzero((predicted - 1) * (labels - 1) * mask)
fp = tf.count_nonzero(predicted * (labels - 1) * mask)
fn = tf.count_nonzero((predicted - 1) * labels * mask) # Calculate accuracy, precision, recall and F1 score.
precision = tp / (tp + fp)
recall = tp / (tp + fn)
fmeasure = (2 * precision * recall) / (precision + recall)
fmeasure = tf.cast(fmeasure, tf.float32)
return fmeasure
这里面定义了训练循环,损失计算,模型评价指标等等。
最后是计算图以及session:
with tf.Graph().as_default():
with tf.name_scope('input'):
ftr_in = tf.placeholder(dtype=tf.float32, shape=(batch_size, nb_nodes, ft_size))
bias_in = tf.placeholder(dtype=tf.float32, shape=(batch_size, nb_nodes, nb_nodes))
lbl_in = tf.placeholder(dtype=tf.int32, shape=(batch_size, nb_nodes, nb_classes))
msk_in = tf.placeholder(dtype=tf.int32, shape=(batch_size, nb_nodes))
attn_drop = tf.placeholder(dtype=tf.float32, shape=())
ffd_drop = tf.placeholder(dtype=tf.float32, shape=())
is_train = tf.placeholder(dtype=tf.bool, shape=()) logits = model.inference(ftr_in, nb_classes, nb_nodes, is_train,
attn_drop, ffd_drop,
bias_mat=bias_in,
hid_units=hid_units, n_heads=n_heads,
residual=residual, activation=nonlinearity)
log_resh = tf.reshape(logits, [-1, nb_classes])
lab_resh = tf.reshape(lbl_in, [-1, nb_classes])
msk_resh = tf.reshape(msk_in, [-1])
loss = model.masked_softmax_cross_entropy(log_resh, lab_resh, msk_resh)
accuracy = model.masked_accuracy(log_resh, lab_resh, msk_resh) train_op = model.training(loss, lr, l2_coef) saver = tf.train.Saver() init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) vlss_mn = np.inf
vacc_mx = 0.0
curr_step = 0 with tf.Session() as sess:
sess.run(init_op) train_loss_avg = 0
train_acc_avg = 0
val_loss_avg = 0
val_acc_avg = 0 for epoch in range(nb_epochs):
tr_step = 0
tr_size = features.shape[0] while tr_step * batch_size < tr_size:
_, loss_value_tr, acc_tr = sess.run([train_op, loss, accuracy],
feed_dict={
ftr_in: features[tr_step*batch_size:(tr_step+1)*batch_size],
bias_in: biases[tr_step*batch_size:(tr_step+1)*batch_size],
lbl_in: y_train[tr_step*batch_size:(tr_step+1)*batch_size],
msk_in: train_mask[tr_step*batch_size:(tr_step+1)*batch_size],
is_train: True,
attn_drop: 0.6, ffd_drop: 0.6})
train_loss_avg += loss_value_tr
train_acc_avg += acc_tr
tr_step += 1 vl_step = 0
vl_size = features.shape[0] while vl_step * batch_size < vl_size:
loss_value_vl, acc_vl = sess.run([loss, accuracy],
feed_dict={
ftr_in: features[vl_step*batch_size:(vl_step+1)*batch_size],
bias_in: biases[vl_step*batch_size:(vl_step+1)*batch_size],
lbl_in: y_val[vl_step*batch_size:(vl_step+1)*batch_size],
msk_in: val_mask[vl_step*batch_size:(vl_step+1)*batch_size],
is_train: False,
attn_drop: 0.0, ffd_drop: 0.0})
val_loss_avg += loss_value_vl
val_acc_avg += acc_vl
vl_step += 1 print('Training: loss = %.5f, acc = %.5f | Val: loss = %.5f, acc = %.5f' %
(train_loss_avg/tr_step, train_acc_avg/tr_step,
val_loss_avg/vl_step, val_acc_avg/vl_step)) if val_acc_avg/vl_step >= vacc_mx or val_loss_avg/vl_step <= vlss_mn:
if val_acc_avg/vl_step >= vacc_mx and val_loss_avg/vl_step <= vlss_mn:
vacc_early_model = val_acc_avg/vl_step
vlss_early_model = val_loss_avg/vl_step
saver.save(sess, checkpt_file)
vacc_mx = np.max((val_acc_avg/vl_step, vacc_mx))
vlss_mn = np.min((val_loss_avg/vl_step, vlss_mn))
curr_step = 0
else:
curr_step += 1
if curr_step == patience:
print('Early stop! Min loss: ', vlss_mn, ', Max accuracy: ', vacc_mx)
print('Early stop model validation loss: ', vlss_early_model, ', accuracy: ', vacc_early_model)
break train_loss_avg = 0
train_acc_avg = 0
val_loss_avg = 0
val_acc_avg = 0 saver.restore(sess, checkpt_file) ts_size = features.shape[0]
ts_step = 0
ts_loss = 0.0
ts_acc = 0.0 while ts_step * batch_size < ts_size:
loss_value_ts, acc_ts = sess.run([loss, accuracy],
feed_dict={
ftr_in: features[ts_step*batch_size:(ts_step+1)*batch_size],
bias_in: biases[ts_step*batch_size:(ts_step+1)*batch_size],
lbl_in: y_test[ts_step*batch_size:(ts_step+1)*batch_size],
msk_in: test_mask[ts_step*batch_size:(ts_step+1)*batch_size],
is_train: False,
attn_drop: 0.0, ffd_drop: 0.0})
ts_loss += loss_value_ts
ts_acc += acc_ts
ts_step += 1 print('Test loss:', ts_loss/ts_step, '; Test accuracy:', ts_acc/ts_step) sess.close()
这里需要注意的是,虽然目前tensorflow出了2.x版本之后就简化了很多,但是之前1.x版本还是需要了解的。以上代码就是1.x版本,1.x版本的tensorflow的一般分为以下步骤:
(1)利用类似python的上下文管理器定义计算图;
(2)为计算图中的一些变量定义占位符;
(3)定义损失、模型、评价指标、训练循环、初始化参数、保存模型等;
(4)将训练流程放入到session中,然后在相关的位置喂入实际的数据;
总结:
最后还是做个总结吧。能看到这里相信你对GAT的整个脉络已经了解的很清楚了,顺带还了解了其它的一些库的用法。如何才能真正的去弄懂一篇论文,每个人都有其自己的方式,包括去看原论文,去网上找相应的博客,其实在有大致了解之后去看源代码不失为一种好的办法。对于代码量比较少而言,可以像我这样一步一步的去剖析每行代码的作用,但是对于庞大的代码而言,还是要根据功能点划分代码块,针对于不同功能的代码块花不同的精力去研究。
由于我的水平有限,其中难免有理解不正确的地方,欢迎指出。
graph attention network(ICLR2018)官方代码详解(te4nsorflow)的更多相关文章
- graph attention network(ICLR2018)官方代码详解(tensorflow)-稀疏矩阵版
论文地址:https://arxiv.org/abs/1710.10903 代码地址: https://github.com/Diego999/pyGAT 之前非稀疏矩阵版的解读:https://ww ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解
本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Multilayer Perceptron,如果你想详细了解多层感知机算法,可以参考:UFLDL教程,或者参 ...
- ARM Cortex-M底层技术(2)—启动代码详解
杂谈 工作了一天,脑袋比较乱.一直想把底层的知识写成一个系列,希望可以坚持下去.为什么要写底层的东西呢?首先,工作用到了这部分内容,最近和内部Flash打交道比较多,自然而然会接触到一些底层的东西:第 ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- ASP.NET MVC 5 学习教程:生成的代码详解
原文 ASP.NET MVC 5 学习教程:生成的代码详解 起飞网 ASP.NET MVC 5 学习教程目录: 添加控制器 添加视图 修改视图和布局页 控制器传递数据给视图 添加模型 创建连接字符串 ...
- Github-karpathy/char-rnn代码详解
Github-karpathy/char-rnn代码详解 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2016-1-10 ...
- JAVA类与类之间的全部关系简述+代码详解
本文转自: https://blog.csdn.net/wq6ylg08/article/details/81092056类和类之间关系包括了 is a,has a, use a三种关系(1)is a ...
随机推荐
- python5.3二进制文件的读写
fh=open(r"C:\1.png","rb")#转换成二进制数据data=fh.read()#对二进制数据进行读取 fh1=open(r"C:\2 ...
- 标星7000+,这个 Python 艺术二维码生成器厉害了!
微信二维码,相信大家也并不陌生,为了生成美观的二维码,许多用户都会利用一些二维码生成工具. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手 ...
- 搞大数据,Java 工程师需要掌握哪些知识?
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我的 ...
- 通过java程序(JSch)运行远程linux主机上的shell脚本
如果您看完文章之后,觉得对您有帮助,请帮我点个赞,您的支持是我不竭的创作动力! 如果您看完文章之后,觉得对您有帮助,请帮我点个赞,您的支持是我不竭的创作动力! 如果您看完文章之后,觉得对您有帮助,请帮 ...
- ACL权限管理 学习
#查看权限 getfacl 文件名 例子:getfacl test 结果:# file: test# owner: root# group: rootuser::rw-group::r-xother: ...
- Web组件的三种关联关系
Web应用程序如此强大的原因之一是它们能彼此链接和聚合信息资源.Web组件之间存在三种关联关系: ● 请求转发 ● URL重定向 ● 包含 存在以上关联关系的Web组件可以是JSP或Servle ...
- AlgorithmMan,一套免费的算法演示神器
概述 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/971 访问. 文章末尾附带GitHub开源下载地址. 0.概述 ...
- 注意STL的小细节 2009-05-18 22:18
STL分容器,算法,跌代器,配置器,适配器,函数对象等. 容器好学好理解.就是vector,list等,这些是常用的,还有些不常用的deque等.算法可以说是STL的精华了,它的功能强大种类繁多,可根 ...
- JDK1.8源码学习-LinkedList
JDK1.8源码学习-LinkedList 目录 一.LinkedList简介 LinkedList是一个继承于AbstractSequentialList的双向链表,是可以在任意位置进行插入和移除操 ...
- linux线程控制-2(线程控制函数)
记录肖堃老师讲解的linux线程 1. 创建线程 int pthread_create( (pthread_t *thread, pthread_attr_t *attr, void *(*start ...