(数据科学学习手札99)掌握pandas中的时序数据分组运算
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
我们在使用pandas分析处理时间序列数据时,经常需要对原始时间粒度下的数据,按照不同的时间粒度进行分组聚合运算,譬如基于每个交易日的股票收盘价,计算每个月的最低和最高收盘价。
而在pandas中,针对不同的应用场景,我们可以使用resample()、groupby()以及Grouper()来非常高效快捷地完成此类任务。
 图1
图1
2 在pandas中进行时间分组聚合
在pandas中根据具体任务场景的不同,对时间序列进行分组聚合可通过以下两类方式实现:
2.1 利用resample()对时序数据进行分组聚合
resample原始的意思是重采样,可分为上采样与下采样,而我们通常情况下使用的都是下采样,也就是从高频的数据中按照一定规则计算出更低频的数据,就像我们一开始说的对每日数据按月汇总那样。
如果你熟悉pandas中的groupby()分组运算,那么你就可以很快地理解resample()的使用方式,它本质上就是在对时间序列数据进行“分组”,最基础的参数为rule,用于设置按照何种方式进行重采样,就像下面的例子那样:
import pandas as pd
# 记录了2013-02-08到2018-02-07之间每个交易日苹果公司的股价
AAPL = pd.read_csv('AAPL.csv', parse_dates=['date'])
# 以月为统计窗口计算每月股票最高收盘价
(
AAPL
.set_index('date') # 设置date为index
.resample('M') # 以月为单位
.agg({
'close': ['max', 'min']
})
)
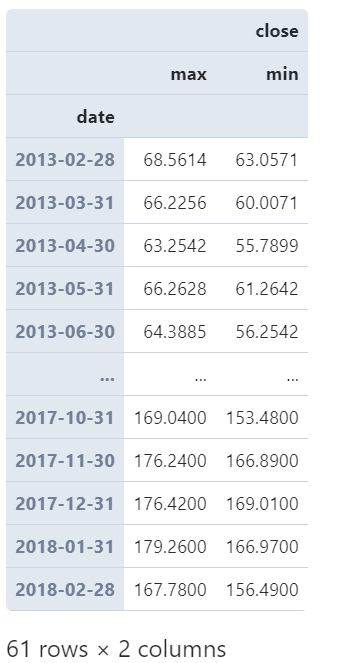 图2
图2
可以看到,在上面的例子中,我们对index为日期时间类型的DataFrame应用resample()方法,传入的参数'M'是resample第一个位置上的参数rule,用于确定时间窗口的规则,譬如这里的字符串'M'就代表月且聚合结果中显示对应月的最后一天,常用的固化的时间窗口规则如下表所示:
| 规则 | 说明 |
|---|---|
| W | 星期 |
| M | 月,显示为当月最后一天 |
| MS | 月,显示为当月第一天 |
| Q | 季度,显示为当季最后一天 |
| QS | 季度,显示为当季第一天 |
| A | 年,显示为当年最后一天 |
| AS | 年,显示为当年第一天 |
| D | 日 |
| H | 小时T |
| T或min | 分钟 |
| S | 秒 |
| L或 ms | 毫秒 |
且这些规则都可以在前面添加数字实现倍数效果:
# 以6个月为统计窗口计算每月股票平均收盘价且显示为当月第一天
(
AAPL
.set_index('date') # 设置date为index
.resample('6MS') # 以6个月为单位
.agg({
'close': 'mean'
})
)
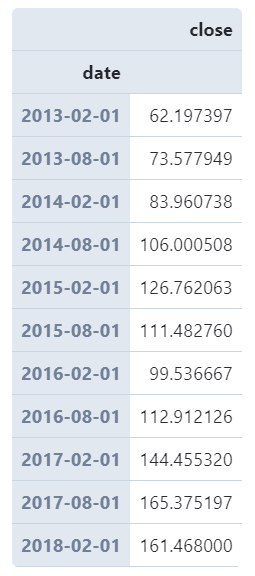 图3
图3
且resample()非常贴心之处在于它会自动帮你对齐到规整的时间单位上,譬如我们这里只有交易日才会有记录,如果我们设置的时间单位下无对应记录,也会为你保留带有缺失值记录的时间点:
(
AAPL
.set_index('date') # 设置date为index
.resample('1D') # 以1日为单位
.agg({
'close': 'mean'
})
)
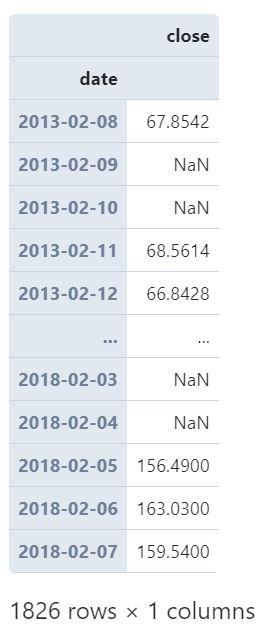 图4
图4
而通过参数closed我们可以为细粒度的时间单位设置区间闭合方式,譬如我们以2日为单位,将closed设置为'right'时,从第一行记录开始计算所落入的时间窗口时,其对应为时间窗口的右边界,从而影响后续所有时间单元的划分方式:
(
AAPL
.set_index('date') # 设置date为index
.resample('2D', closed='right')
.agg({
'close': 'mean'
})
)
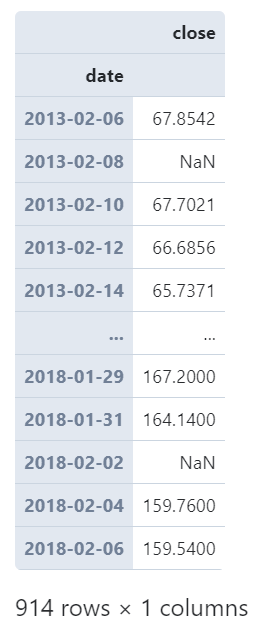 图5
图5
而即使你的数据框index不是日期时间类型,也可以使用参数on来传入日期时间列名实现同样的效果。
2.2 利用groupby()+Grouper()实现混合分组
有些情况下,我们不仅仅需要利用时间类型列来分组,也可能需要包含时间类型在内的多个列共同进行分组,这种情况下我们就可以使用到Grouper()。
它通过参数freq传入等价于resample()中rule的参数,并利用参数key指定对应的时间类型列名称,但是可以帮助我们创建分组规则后传入groupby()中:
# 分别对苹果与微软每月平均收盘价进行统计
(
pd
.read_csv('AAPL&MSFT.csv', parse_dates=['date'])
.groupby(['Name', pd.Grouper(freq='MS', key='date')])
.agg({
'close': 'mean'
})
)
 图6
图6
且在此种混合分组模式下,我们可以非常方便的配合apply、transform等操作,这里就不再赘述。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札99)掌握pandas中的时序数据分组运算的更多相关文章
- (数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常开展数据分析的过程中,我们经常需要对 ...
- (数据科学学习手札52)pandas中的ExcelWriter和ExcelFile
一.简介 pandas中的ExcelFile()和ExcelWriter(),是pandas中对excel表格文件进行读写相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控 ...
- (数据科学学习手札68)pandas中的categorical类型及应用
一.简介 categorical是pandas中对应分类变量的一种数据类型,与R中的因子型变量比较相似,例如性别.血型等等用于表征类别的变量都可以用其来表示,本文就将针对categorical的相关内 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札19)R中基本统计分析技巧总结
在获取数据,并且完成数据的清洗之后,首要的事就是对整个数据集进行探索性的研究,这个过程中会利用到各种描述性统计量和推断性统计量来初探变量间和变量内部的基本关系,本篇笔者便基于R,对一些常用的数据探索方 ...
- (数据科学学习手札124)pandas 1.3版本主要更新内容一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,pandas发布了其1.3版本 ...
- (数据科学学习手札126)Python中JSON结构数据的高效增删改操作
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一期文章中我们一起学习了在Python ...
- (数据科学学习手札81)conda+jupyter玩转数据科学环境搭建
本文示例yaml文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用Python进行数据分析时,很 ...
随机推荐
- 第14章——高级IO函数
1.套接字超时 套接字IO函数设置超时的方法有三种: (1)调用alarm. (2)select (3)使用SO_RECTIMEO和 SO_SNDTIMEO 选项 上面三种方法适用于输入输出操作(re ...
- linux文件的3个时间和7种文件类型
linux文件的三个时间: atime: access time --最近访问时间. ctime: change time --最近改变时间. mtime:modify time --最近修改时间. ...
- Ceph Bluestore首测
Bluestore 作为 Ceph Jewel 版本推出的一个重大的更新,提供了一种之前没有的存储形式,一直以来ceph的存储方式一直是以filestore的方式存储的,也就是对象是以文件方式存储在o ...
- istio in kubernetes (一) --原理篇
背景 微服务是什么 • 服务之间有轻量级的通讯机制,通常为REST API • 去中心化的管理机制 • 每个服务可以使用不同的编程语言实现,使用不同的数据存储技术 • 应用按业务拆分成服务,一个大型应 ...
- HBuilderX SVN地址更改(SVN服务器IP地址变更)
HBuilderX编辑器中无法修改SVN地址,需要手动在SVN工具中修改 修改步骤: 1.右键编辑器中的SVN项目,选择打开文件所在目录 2.目录中空白处右键,选择TortoiseSVN --> ...
- Netty源码解析 -- 内存对齐类SizeClasses
在学习Netty内存池之前,我们先了解一下Netty的内存对齐类SizeClasses,它为Netty内存池中的内存块提供大小对齐,索引计算等服务方法. 源码分析基于Netty 4.1.52 Nett ...
- Hbase启动报java异常
在conf文件夹下的hbase-env.sh文件中的j添加ava_home的环境变量, ******************************************************** ...
- C++中内存布局 以及自由存储区和堆的理解
文章搬运自https://www.cnblogs.com/QG-whz/p/5060894.html,如有侵权请告知删除 当我问你C++的内存布局时,你大概会回答: "在C++中,内存区分为 ...
- 宕机了,Redis数据丢了怎么办?
持续原创输出,点击上方蓝字关注我 目录 前言 什么是AOF? 三种写回策略 日志文件太大怎么办? AOF重写会阻塞主线程吗? AOF的缺点 总结 什么是RDB? 给哪些数据做快照? 快照时能够修改数据 ...
- FL Studio通道预设之采样预览
FL Studio采样预览栏在采样设置窗口的最底端,它能很好地显示 出载入采样的波形也可以将波形显示改为频谱显示.它里面显示出的是经过预处理效果栏处理后的波形或频谱图.我们在波形显示器下面还可以看到波 ...