hbase读写优化
一、hbase读优化
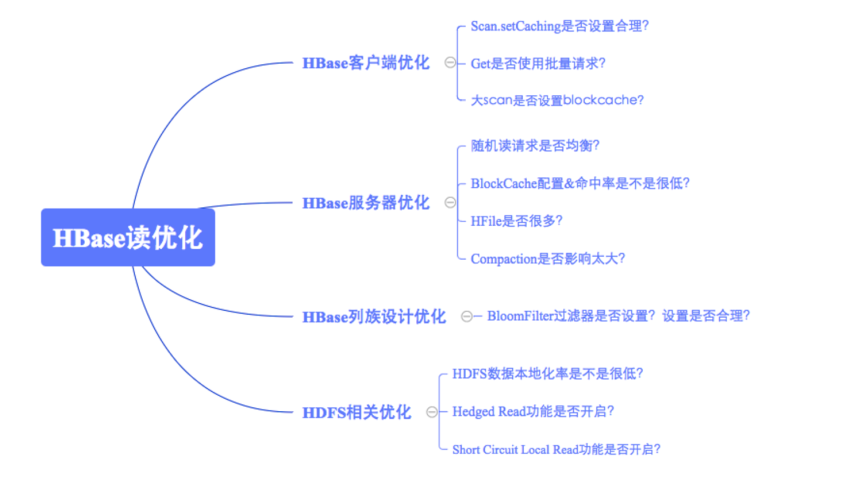
客户端优化
1、scan缓存是否设置合理?
优化原理:一次scan请求,实际并不会一次就将所有数据加载到本地,而是多次RPC请求进行加载。默认100条数据大小。
优化建议:大scan场景下将scan缓存从100增大到500或者1000,以减少RPC次数
2、get请求是否可以使用批量请求?
优化原理:Hbase分别提供了单条get以及批量get的API接口,使用批量get接口可以减少客户端到RegionServer之间的PRC连接数,提高读取性能。
3、请求是否可以显示指定列族或者列?
优化原理:同一列族的数据存储在一起,不同列族的数据分开存储在不同的目录下。如果一个表有多个列族,只是根据Rowkey而不指定列族进行检索的话不同列族的数需要独立进行检索,很多情况下甚至会有2倍~3倍的性能损失。
优化建议:可以指定列族或者列进行精确查找的尽量指定查找
4、离线批量读取请求是否设置禁止缓存?
优化原理:大量数据进入缓存必将其他实时业务热点数据挤出,其他业务不得不从HDFS加载,进而会造成明细的读延迟毛刺。
优化建议:离线批量读取请求设置禁用缓存,scan.setBlockCache(false)
服务端优化
1、读请求是否均衡?
优化原理:读请求不均衡不仅会造成本身业务性能很差,还会严重影响其他业务
观察确认:观察所有RegionServer的读请求QPS曲线,确认是否存在读请求不均衡现象
优化建议:RowKey必须进行散列话处理(比如MD5散列),同时建表时必须进行预分区处理
2、BlockCache是否设置合理?
优化原理:默认情况下BlockCache和Memstore的配置相对比较均衡(各占40%),可以根据集群业务进行修正,比如读多写少可以将BlockCache占比调大。
优化建议:JVM内存配置量<20G,BlockCache策略选择LRUBlockCache;否则选择BucketCache策略的offheap模式
3、HFile文件是否太多?
优化原理:文件越多,检索所需的IO次数必然越多,读取延迟也就越高。文件数量通常取决于Compaction的执行策略,一般和两个参数有关:
hbase.hstore.compactionThreshold和hbase.hstore.compaction.max.size,前者表示一个store中的文件数超过多少就应该进行合并,后者表示参数合并的文件大小最大是多少,超过此大小的文件不能参与合并。
观察确认:观察RegionServer级别以及Region级别的storefile数,确认HFile文件是否过多
优化建议:hbase.store.compactionThreshold设置不能太大,默认是3个;设置需要根据Region大小确定,通常可以简单的认为:
hbase.hstore.compaction.max.size=RegionSize / hbase.hstore.compactionThreshold
4、Compaction是否消耗系统资源过多?
优化原理:Compaction是将小文件合并为大文件,提高后续业务随机读性能,但是也会带来IO放大以及带宽消耗问题,问题主要产生于配置不合理导致Minor Compaction太过频繁,或者Region设置太大情况下发生Major Compaction。
观察确认:观察系统IO资源以及带宽资源使用情况,再观察Compaction队列长度,确认是否由于Compaction导致系统资源消耗过多。
优化建议:
a、Minor Compaction设置:hbase.hstore.compactionThreshold设置不能太小,又不能设置太大,因此建议设置为5~6;hbase.hstore.compaction.max.size=RegionSize / hbase.hstore.compactionThreshold
b、Major Compaction设置:大Region读延迟敏感业务(100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量
Hbase列族设计优化
1、Bloomfilter是否设置?是否设置合理?
优化原理:过滤不存在待检索Rowkey或者Row-Col的HFile文件,避免无用的IO操作。它会告诉你在这个HFile文件中是否存在待检索的key-value,如果不存在,就可以不用消耗IO打开文件进行seek,可以提升随机读写的性能。
Bloomfiler取值有两个,Row以及RowCol ;如果业务大多数随机查询仅仅使用Row作为查询条件,Bloomfiler一定要设置为Row;如果大多数随机查询使用Row+cf作为查询条件,Bloomfilter要设置为RowCol。
优化建议:任何业务都应该设置Bloomfilter,通常设置为Row就可以,除非确认业务随机查询类型为Row+cf,可以设置为RowCol
HDFS相关优化
1、Short-Circuit Local Read功能是否开启?
优化原理:当前HDFS读取数据都需要经过DataNode,客户端会向DataNode发送读取数据的请求,DataNode接受请求之后从硬盘中将文件读出来发送给客户端。Short Circuit策略允许客户端绕过DataNode直接读取本地数据。
优化建议:开启Short Circuit Local Read功能
2、Hedged Read功能是否开启?
优化原理:优先会通过Short-Circuit Local Read功能尝试本地读。某些特殊情况下,有可能会出现因为磁盘问题或者网络问题引起的短时间本地读取失败。补偿重试机制-Hedged Read的基本工作原理为:客户端发起一个本地读,一旦一段时间之后还没有返回,客户端将会向其他DataNode发送相同数据的请求。哪一个请求先返回,另一个就会被丢弃。
优化建议:开启Hedged Read功能
3、数据本地率是否太低?
优化原理:本地化率低会产生大量的跨网络IO请求,必然会导致读请求延迟较高,原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等),因此一方面可以通过避免Region无故迁移来保持数据本地率,另一方面如果数据本地率很低,也可以通过执行major_compact提升数据本地率。
优化建议:避免Region无故迁移,比如关闭自动balance、RegionServer宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率
二、Hbase写优化
1、是否需要写WAL?WAL是否需要同步写入?
优化原理:
a、WAL机制一方面是为了确保数据即使写入缓存丢失也可以恢复,另一方面是为了集群之间异步复制
b、默认开启
c、对于部分业务可能并不特别关心异常情况下部分数据的丢失,而更关心数据写入吞吐量,比如某些推荐业务,这类业务即使丢失一部分用户行为数据可能对推荐结果并不构成很大影响,但是对于写入吞吐量要求很高,不能造成数据队列阻塞。这种场景下可以考虑关闭WAL写入,写入吞吐量可以提升2x~3x,然而有些业务不能接受不写WAL,但是可以接受WAL异步写入,也是可以考虑优化的,通常也会带来1x~2x的性能提升。
优化建议:根据业务关注点在WAL机制与写入吞吐量直接作出选择
2、Put是否可以同步批量提交
优化原理:Hbase分别提供了单条put以及批量put的API接口,使用批量put接口可以减少客户端到RegionServer之间的RPC连接数,提高写入性能。另外需要注意的是批量put请求要么全部成功返回,要么抛出异常。
优化建议:使用批量put进行写入请求
3、Put是否可以一步批量提交?
优化原理:业务如果可以接受异常情况下少了数据丢失的话,还可以使用异步批量提交的方式提交请求。提交分为两个阶段执行:用户提交写请求之后,数据会写入客户端缓存,并返回用户写入成功;当客户端缓存达到阈值(默认2M)之后批量提交给RegionServer。需要注意的是,在某些情况下客户端异常的情况下缓存数据有可能丢失。
优化建议:在业务可以接受的情况下开启异步批量提交
使用方式:setAutoFlush(false)
4、Region是否太少?
优化原理:当前集群中表的Region个数如果小于RegionServer个数,即Num(Region of Table )< Num(RegionServer),可以考虑切分Region并尽可能分布到不同RegionServer来提高系统请求并发度
优化建议:在Num(Region of Tale)<Num(RegionServer)的场景下切分部分请求负载高的Region并迁移到其他RegionServer;
5、写入请求是否不均衡?
优化原理:如果不均衡,一方面会导致系统并发度较低,另一方面也有可能造成部分节点负载很高,进而影响其他业务。
优化建议:检查Rowkey设计以及预分区策略,保证写入请求均衡。
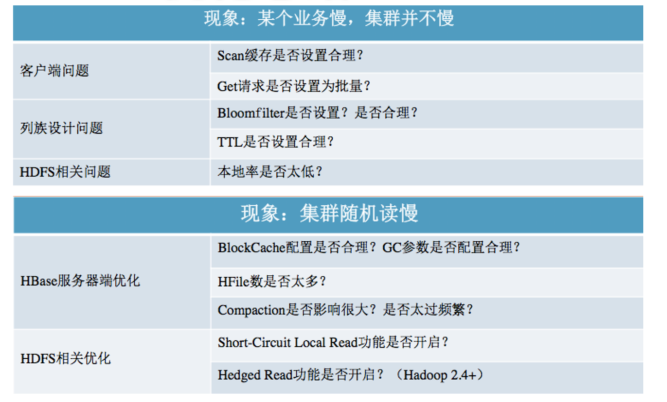
三、Hbase优化总结

hbase读写优化的更多相关文章
- 万字长文详解HBase读写性能优化
一.HBase 读优化 1. HBase客户端优化 和大多数系统一样,客户端作为业务读写的入口,姿势使用不正确通常会导致本业务读延迟较高实际上存在一些使用姿势的推荐用法,这里一般需要关注四个问题: 1 ...
- hbase性能优化总结
hbase性能优化总结 1. 表的设计 1.1 Pre-Creating Regions 默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都 ...
- HBase参数优化
zookeeper.session.timeout默认值:3分钟(180000ms)说明:RegionServer与Zookeeper间的连接超时时间.当超时时间到后,ReigonServer会被Zo ...
- HBASE的优化、hadoop通用优化,Linux优化,zookeeper优化,基础优化
HBase 的优化3.1.高可用在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果Hmaster 挂掉了,那么整个 HBa ...
- HBase的优化
HBase的优化 高可用 在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- HBase读写的几种方式(一)java篇
1.HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一种 ...
- Hadoop生态圈-HBase性能优化
Hadoop生态圈-HBase性能优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- HBase性能优化方法总结(转)
原文链接:HBase性能优化方法总结(一):表的设计 本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,可参考:淘宝Ken Wu同学的博客. ...
随机推荐
- PyQt(Python+Qt)学习随笔:信号签名(signature of the signal)是什么?
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 1.概念解释 函数签名:由函数的参数个数与其类型组成.函数在重载时,利用函数签名的不同即参数个数与类 ...
- XSS挑战赛(3)
查看关键代码: <?php ini_set("display_errors", 0); $str = $_GET["keyword"]; $str00 = ...
- Nginx 转发时的一个坑,运维居然让我背锅!!
最近遇到一个 Nginx 转发的坑,一个请求转发到 Tomcat 时发现有几个 http header 始终获取不到,导致线上出现 bug,运维说不是他的问题,这个锅我背了. 新增的几个 header ...
- Spark3.0中Dates和Timestamps
Spark3.0使用的是预公历,而之前都是儒略历和公历的混合(即1582年之前的日期使用儒略历,1582年之后使用公历,java.sql.Date这个API用的就是这种,而Java8里使用java.t ...
- redis学习之——在分布式数据库中CAP原理CAP+BASE
分布式系统 分布式系统(distributed system) 由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成.分布式系统是建立在网络之上的软件系统.正是因为软件的特性,所以分 ...
- do{}while(false)的用法
do{}while(false): 在工作中我们能经常发现有人写 do{}while(false) 这样的代码,初看时让人迷惑不解,按照上面的语法 do{}while(false) 这样 do{} ...
- mysql创建表分区
MySQL创建表分区 create table erp_bill_index( id int primary key auto_increment, addtime datetime ); inser ...
- Jwt令牌创建
添加依赖 <dependencies> <!-- jwt --> <dependency> <groupId>io.jsonwebtoken</g ...
- ADF 第四篇:管道的执行和触发器
Azure Data Factory 系列博客: ADF 第一篇:Azure Data Factory介绍 ADF 第二篇:使用UI创建数据工厂 ADF 第三篇:Integration runtime ...
- Redis存储对象(序列化和反序列化)
代码以及实例: package com.hp.test; import redis.clients.jedis.Jedis; import java.io.*; public class Test3 ...