开启算法之路,还原题目,用debug调试搞懂每一道题
文章简述
大家好,本篇是个人的第 3 篇文章。
承接第一篇文章《手写单链表基础之增,删,查!附赠一道链表题》,在第一篇文章中提过,在刷算法题之前先将基础知识过一遍,这样对后面的做算法题是很有帮助的。
在本次的文章中,按照个人的刷题计划,会分享关于链表的 3 道简单级别的算法题(可是依然感觉不简单)

但是不要紧,从本篇文章开始分享的算法题个人都会把关于这道题的全部代码写出来,并用debug的形式,分解每一步来整理出来。
通过还原题目场景,用 debug 调试的方式去分析,印象更加深刻些。

本篇文章中共有 3 道题目。

一,合并两个有序链表
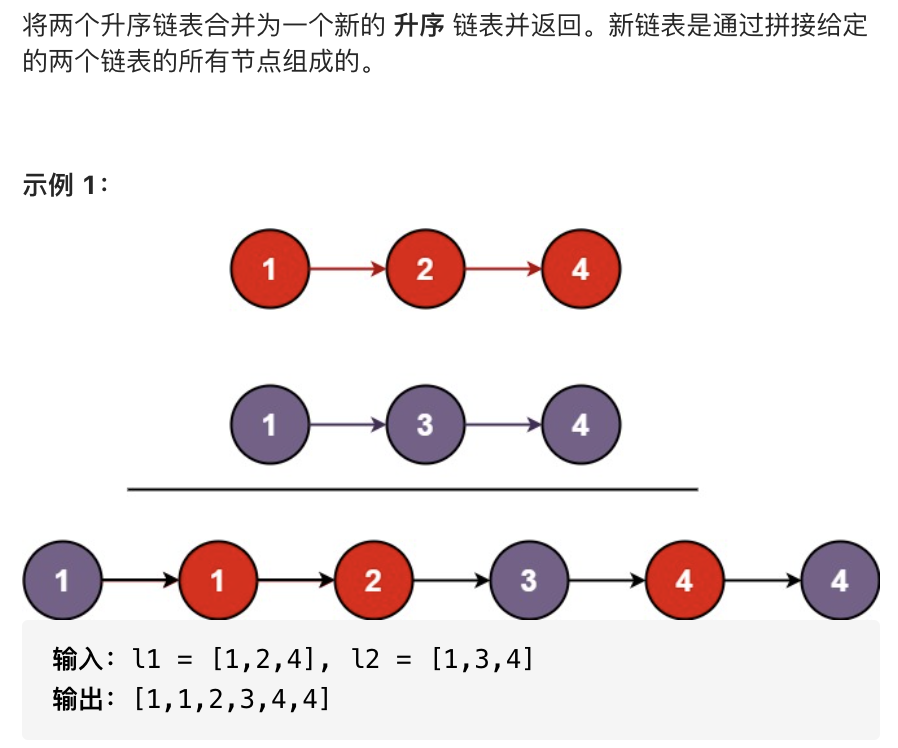
1.1 题目分析
看到这道题的时候,第一反应就是先将两个链表合并,然后再排序。嗯。。。不用想,绝对的暴力写法。
或者是循环两个链表,然后两两相比较,就像:
for(){
for(){
if(){}
}
}
好吧,其实这道题精华在于可以使用递归,这个。。。来个草图简单描述下。
第一步:
两个链表的首节点进行比较
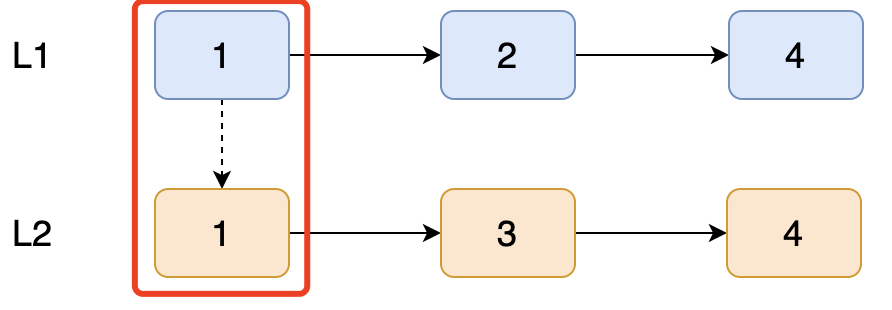
两个节点相等,则使 L2 链表【1】,和 L1 链表的【2】进行比较
注意:
L1节点【1】和L2节点【1】比较完成后,需要修改1.next指针,以指向它的下个节点。
第二步:
现在我们获取到了 L2 链表【1】,那它的 next 指向谁?也就是 L2 链表【1】去和 L1 链表的【2】进行比较。
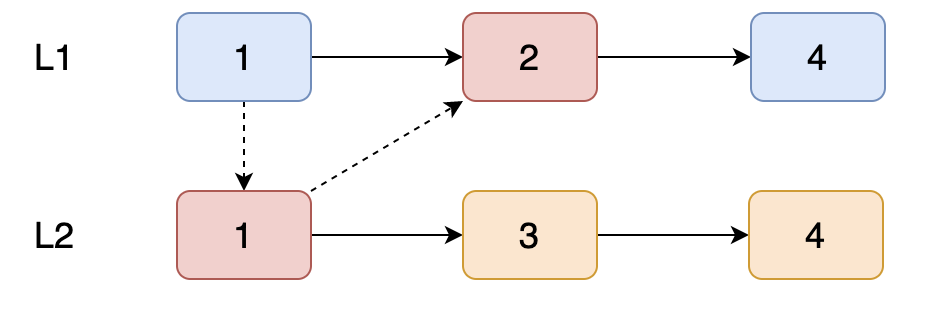
比较完成后,L2 链表【1】的 next 就指向了 L1 链表【2】,接着以此类推。
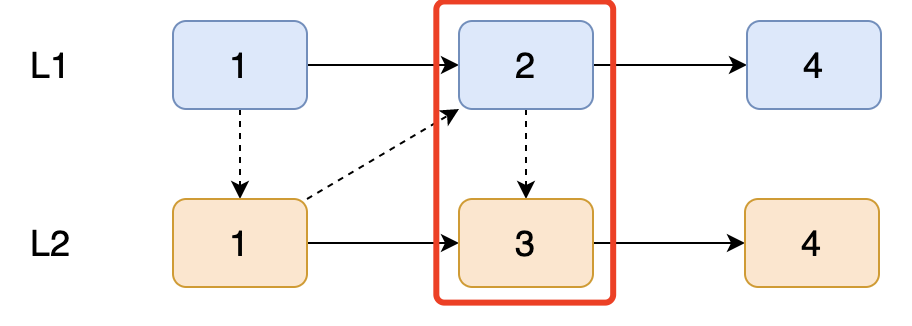
L2 链表【3】去和 L1 链表【4】比较。
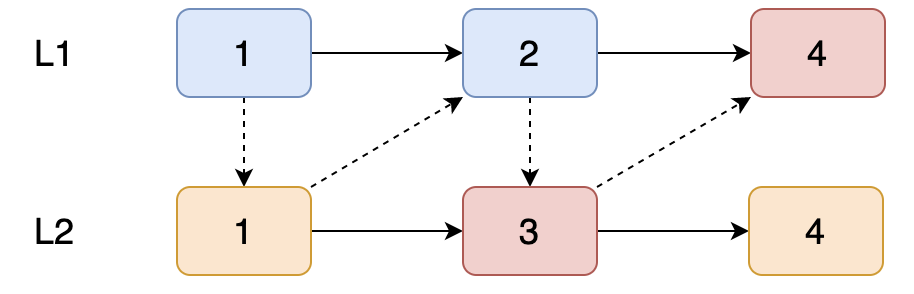
最后 L1 链表【4】和 L2 链表【4】比较。
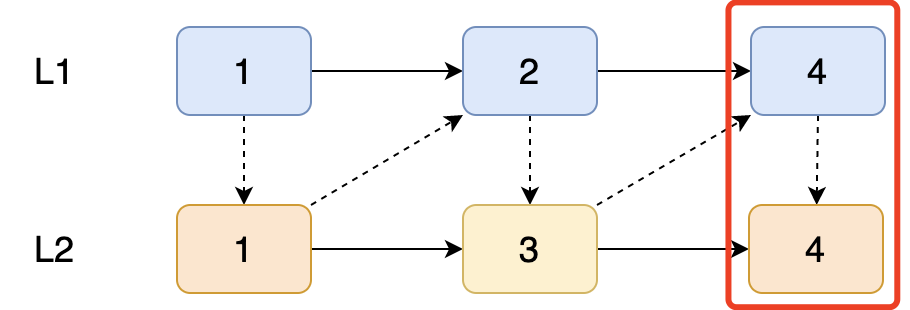
全部比较完成后,整个链表就已经排序完成了。
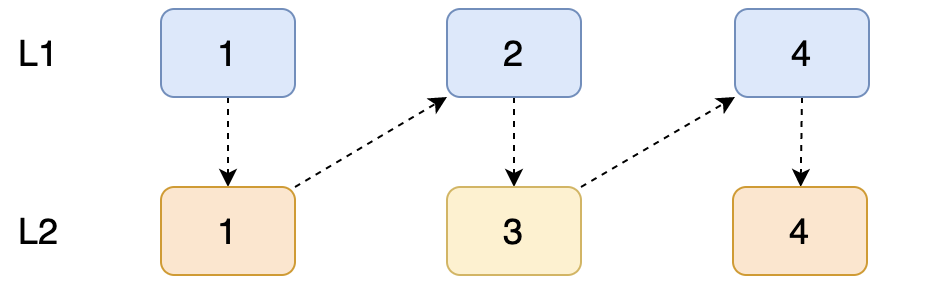
递归的方式就在于,两两节点进行比较,当有一个链表为null时,表示其中一个链表已经遍历完成,那就需要终止递归,并将比较结果进行返回。
可能只是单纯的画图并不好理解,下面用代码 debug 的方式去分析,还请耐心往下看。

1.2 代码分析
按照题意需要先创建 2 个单链表,具体的创建方式可以参考本人的第一篇文章《手写单链表基础之增,删,查!附赠一道链表题》。不多说,先初始化节点对象。
class ListNode {
/**
* 数据域
*/
int val;
/**
* 下一个节点指针
*/
ListNode next;
ListNode() {
}
ListNode(int val) {
this.val = val;
}
ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
@Override
public String toString() {
return "ListNode{" +
"val=" + val +
'}';
}
}
定义新增链表方法。
public ListNode add(ListNode node) {
// 1,定义辅助指针
ListNode temp = nodeHead;
// 2,首先判断当前节点是否为最后节点
if (null == temp.next) {
// 当前节点为最后节点
temp.next = node;
return nodeHead;
}
// 3,循环遍历节点,如果当前节点的下个节点不为空,表示还有后续节点
while (null != temp.next) {
// 否则将指针后移
temp = temp.next;
}
// 4,遍历结束,将最后节点的指针指向新添加的节点
temp.next = node;
return nodeHead.next;
}
接着创建 2 个链表。
/**
* 定义L1链表
*/
ListNode l11 = new ListNode(1);
ListNode l12 = new ListNode(2);
ListNode l13 = new ListNode(4);
MergeLinkedList l1 = new MergeLinkedList();
l1.add(l11);
l1.add(l12);
/**
* 返回新增完的L1链表
*/
ListNode add1 = l1.add(l13);
/**
* 定义L2链表
*/
ListNode l21 = new ListNode(1);
ListNode l22 = new ListNode(3);
ListNode l23 = new ListNode(4);
MergeLinkedList l2 = new MergeLinkedList();
l2.add(l21);
l2.add(l22);
/**
* 返回L2链表
*/
ListNode add2 = l2.add(l23);
我们先把上述图中使用递归的代码贴出来。
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
/**
* 如果L1链表为null,终止递归
*/
if (l1 == null) {
return l2;
}
if (l2 == null) {
return l1;
}
/**
* 按照图中的描述,两两比较链表的节点
*/
if (l1.val <= l2.val) {
/**
* L1的节点比L2的小,按照图中就是需要比较L1链表的下个节点
* l1.next 就是指当比较出节点大小后,需要修改指针的指引,将整个链表全部串联起来
*/
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
/**
* 同理,与上个if判断一样
*/
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
}
1.3 debug 调试
1.3.1 L1 链表已经创建完成,同理 L2 也被创建完成。
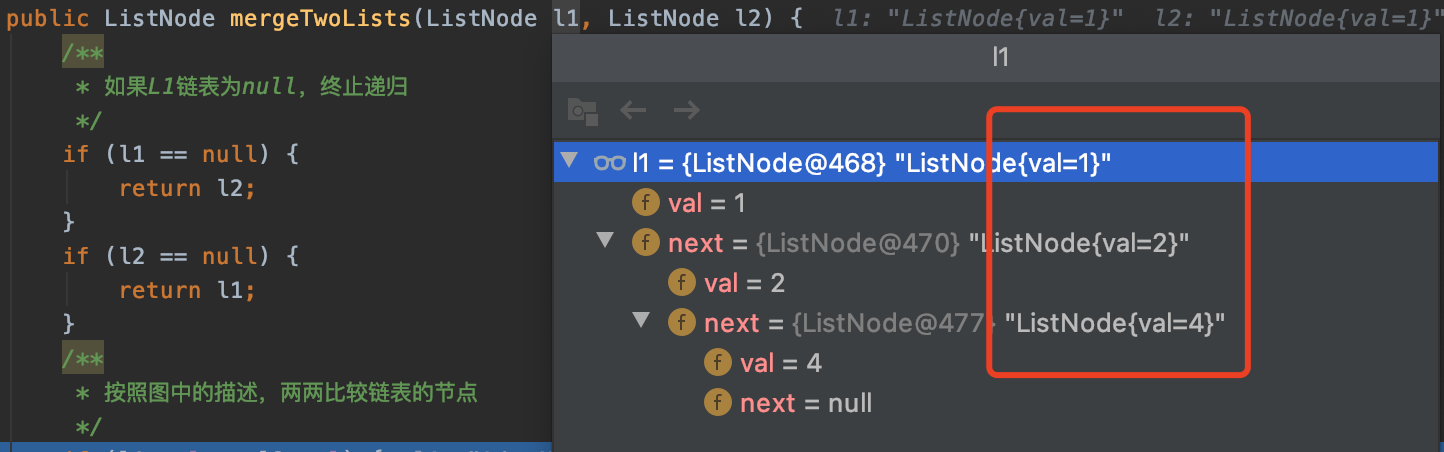
1.3.2 比较两个链表的首节点

注意:
l1.next是指向递归方法的,也就是上图中我们描述的l1链表【1】指向了l2链表【1】,但是L2链表【1】又指向谁?开始进入递归
1.3.3 如上图,开始比较 L2 链表【1】与 L1 链表的【2】

1.3.4 比较 L1 链表【2】与 L2 链表【3】

1.3.5 后面操作是一样的,下面就直接展示最后两个节点比较

这里已经到最后两个节点的比较。
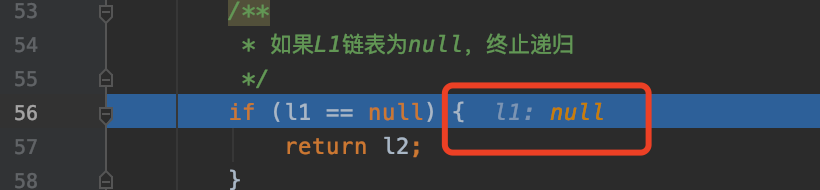
这个时候 L1 链表先遍历完成,需要终止递归,返回 L2 链表。为什么返回 L2 链表?直接看图。
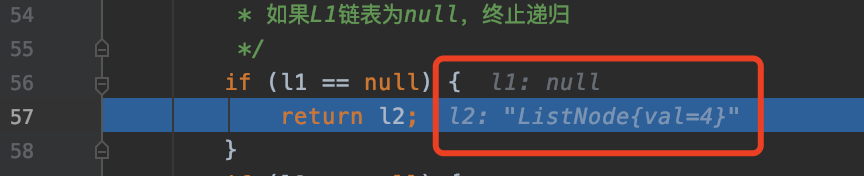
因为最后一步比较的是 L1 链表【4】和 L2 链表【4】,也就是说 L2 链表【4】是最后的节点,如果返回 L1 链表,那 L2 链表【4】就会被丢弃,可参考上面图解的最后一张。
重点来了!!!
重点来了!!!
重点来了!!!
L1 链表已经遍历完成,开始触发递归将比较的结果逐次返回。
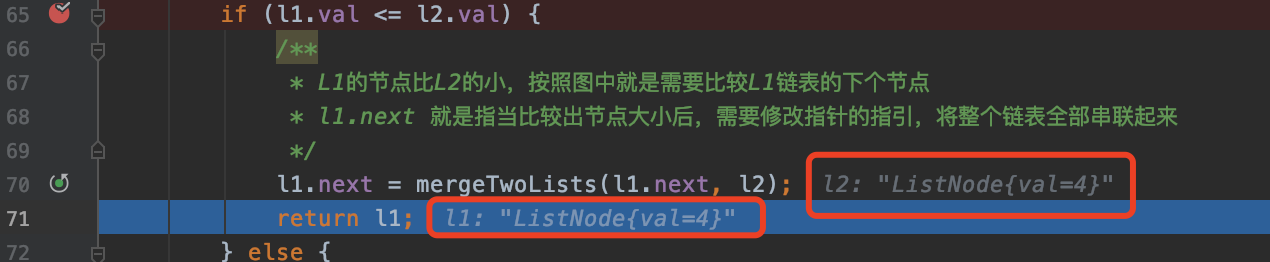
这是不是我们最后 L1 链表【4】和 L2 链表【4】比较的那一步,是不是很明显,l1.next 指向了 l1 的节点【4】,而 L1 节点也就是它最后的节点【4】,和我们那上面图解中最后的结论一样。
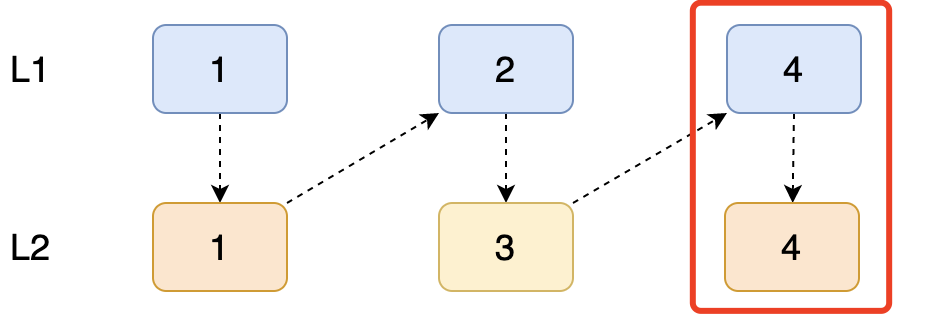
再接着执行下一步返回。

L2 链表的【3】指向了 L1 链表的【4】
同理,按照之前递归的结果以此返回就可以了,那我们来看下最终的排序结果。
二,删除排序链表中的重复元素

2.1 题目分析
初次看这道题好像挺简单的,这不就是个人之前写的第一篇文章里面,删除链表节点吗!
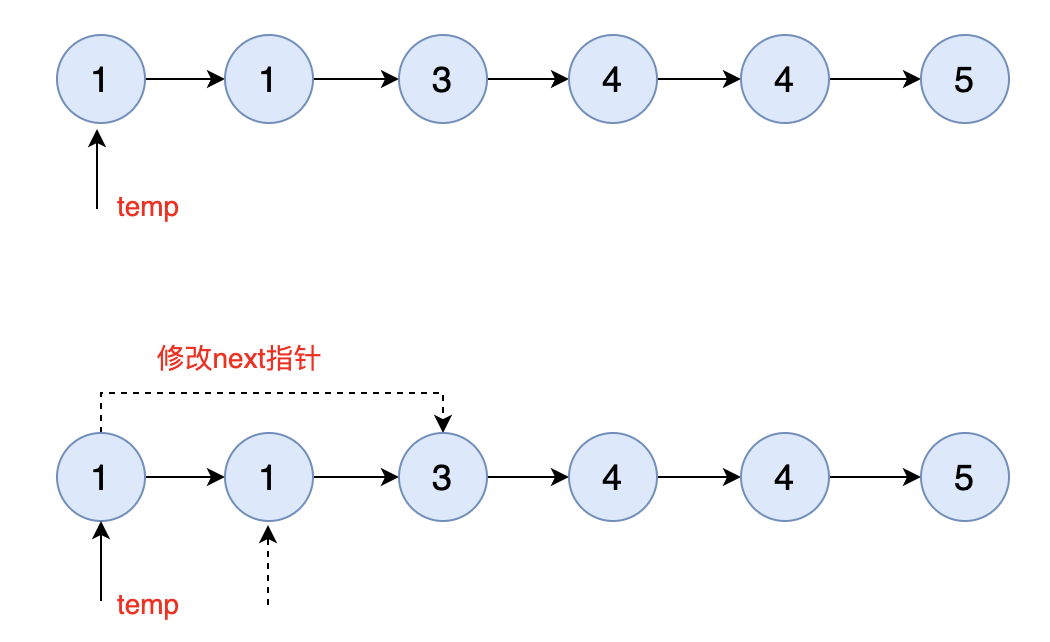
仔细审题其实这道题要更简单些,因为题中已说明是一个排序链表,因此我们只需要将当前节点与下一个节点进行比较,如果相等则直接修改 next 指针即可。
2.1 代码分析
同样是链表的定义,与上面第一题中的创建是一样的,只不过我们是需要再重新创建一个单链表。
ListNode l1 = new ListNode(1);
ListNode l2 = new ListNode(1);
ListNode l3 = new ListNode(3);
ListNode l4 = new ListNode(4);
ListNode l5 = new ListNode(4);
ListNode l6 = new ListNode(5);
NodeFun nodeFun = new NodeFun();
nodeFun.add(l1);
nodeFun.add(l2);
nodeFun.add(l3);
nodeFun.add(l4);
nodeFun.add(l5);
ListNode listNode = nodeFun.add(l6);
创建完成后,接着看去重复的代码。
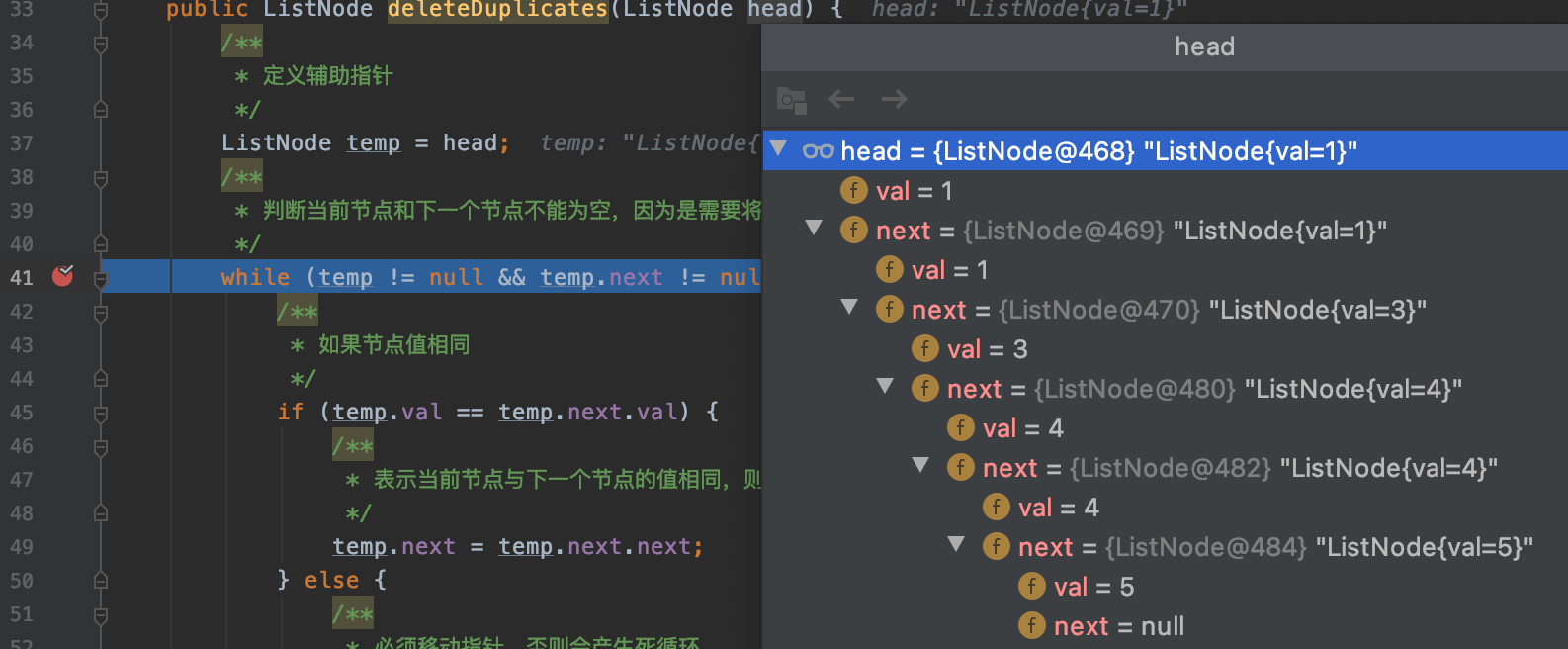
public ListNode deleteDuplicates(ListNode head) {
/**
* 定义辅助指针
*/
ListNode temp = head;
/**
* 判断当前节点和下一个节点不能为空,因为是需要将当前节点和下一个节点进行比较的
*/
while (temp != null && temp.next != null) {
/**
* 如果节点值相同
*/
if (temp.val == temp.next.val) {
/**
* 表示当前节点与下一个节点的值相同,则移动指针
*/
temp.next = temp.next.next;
} else {
/**
* 必须移动指针,否则会产生死循环
*/
temp = temp.next;
}
}
return head;
}
}
2.2 debug 调试
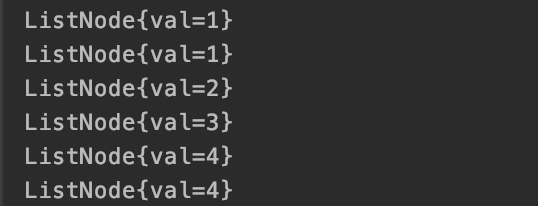
2.2.1 按照初始化的链表,应该是首节点【1】和第二个节点【1】进行比较。

不用说两个节点是相等的,那下一步进入 if 判断,就是修改指针的指向。

此时第二个节点【1】已经没有被 next 指引了,就会被 GC 回收掉。
2.2.2 下一步就是节点【1】和节点【3】进行比较
两个节点不相等,进入 else 将辅助指针移动到下个节点。

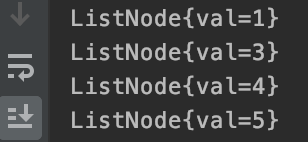
那么剩下的节点判断也都是一样的,我们最后看下打印的结果。
三,环形链表

3.1 题目分析
如果这个链表里面有环,其中一个节点必然是被指针指引了一次或者多次(如果有多个环的话)。因此个人当时简单的做法就是遍历链表,把遍历过的节点对象保存到 HashSet 中,每遍历下一个节点时去 HashSet 中比对,存在就表示有环。
而这道题没有设置过多的要求,只要有环返回 boolean 就好。
还有一种巧妙的写法,使用快慢指针的思想。
这种方式大致意思就是说,快慢指针比作龟兔赛跑,兔子跑的快,如果存在环那么兔子就会比乌龟先跑进环中。那么它们就会在某个节点上相遇,相遇了也就说明链表是有环的。
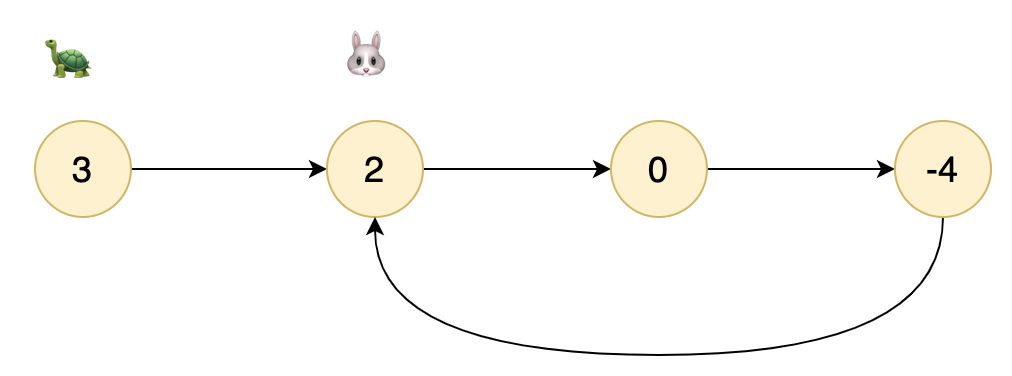
那么,你们问题是不是来了?这不公平啊,【兔子】本来就比【乌龟】跑的快,那咋兔子还先跑了。
试想,如果它俩都在一个节点上跑,那它们从开始不就是相遇了,因为我们我们是设定如果在一个节点上相遇,表示链表是有环的。所以,这不是“不打自招“了!
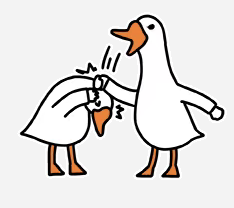
比赛开始,这【兔子大哥】有点猛啊,一下跑两个节点。


果然,有情人终成眷属,它们相遇了。
3.2 代码分析
这次创建链表的时候,就不能单纯是个单链表了,还得加个环。

ListNode l1 = new ListNode(3);
ListNode l2 = new ListNode(2);
ListNode l3 = new ListNode(0);
ListNode l4 = new ListNode(-4);
/**
* 给主角加个环
*/
l4.next = l2;
NodeFun nodeFun = new NodeFun();
nodeFun.add(l1);
nodeFun.add(l2);
nodeFun.add(l3);
ListNode listNode = nodeFun.add(l4);
那就一起来找环吧。
public boolean hasCycle(ListNode head) {
ListNode temp = head;
if(null == head){
// 为空表示没有环
return false;
}
// 1,set集合保存遍历过的节点,如果新的节点已经在set中,表示存在环
// 2,使用快慢指针的思想
// 定义慢指针
ListNode slow = head;
// 定义快指针
ListNode fast = head.next;
// 循环,只要2个指针不重合,就一直循环
while(slow != fast){
// 如果2个指针都到达尾节点,表示没有环
if(fast == null || fast.next == null){
return false;
}
// 否则就移动指针
slow = slow.next;
fast = fast.next.next;
}
return true;
}
3.3 debug 调试
所以,尴尬的事情来了,这玩意 debug 不了啊。如果存在环,那么 while 循环是不会进来的。

那就直接看下结果吧。
如果把环去掉就是?
那还用猜?没有光环了肯定。。。
四,总结
本次分享总结的题目都是简单的题,因为也是按照个人制定的刷题计划开始的,后面我会把个人的刷题计划整理分享出来。
关于文章中完整的代码,关注公众号回复【获取源码】,目前所有代码都是一个工程,也是方便后面的代码更新,可以自己亲自调试。
期待与大家共勉!
最后,求关注
原创不易,每一篇都是用心在写。如果对您有帮助,就请一键三连(关注,点赞,再转发)
我是杨小鑫,坚持写作,分享更多有意义的文章。
感谢您的阅读,期待与您相识!

开启算法之路,还原题目,用debug调试搞懂每一道题的更多相关文章
- 链表算法题二,还原题目,用debug调试搞懂每一道题
文章简述 大家好,本篇是个人的第4篇文章. 承接第3篇文章<开启算法之路,还原题目,用debug调试搞懂每一道题>,本篇文章继续分享关于链表的算法题目. 本篇文章共有5道题目 一,反转链表 ...
- 链表算法题之中等级别,debug调试更简单
文章简述 大家好,本篇是个人的第 5 篇文章 从本篇文章开始,分享关于链表的题目为中等难度,本次共有 3 道题目. 一,两数相加 1.1 题目分析 题中写到数字是按照逆序的方式存储,从进位的角度看,两 ...
- [4] 算法之路 - 插入排序之Shell间隔与Sedgewick间隔
题目 插入排序法由未排序的后半部前端取出一个值.插入已排序前半部的适当位置.概念简单但速度不快. 排序要加快的基本原则之中的一个: 是让后一次的排序进行时,尽量利用前一次排序后的结果,以加快排序的速度 ...
- 小白算法之路-非确定性多项式(non-deterministic polynomial,缩写NP)
前端小白的算法之路 时隔多日终于解决了埋在心头的一道难题,霎时云开雾散,今天把一路而来碰到的疑惑和心得都记录下来,也算是开启了自己探索算法的大门. 问题背景 曾经有一个年少轻狂的职场小白,在前端圈 ...
- u-boot 2011.09 开启debug 调试
以前做过,现在刚才又想不起来了,这个错误非常的严重. 在这里记一下. debug 调试信息的开启在 include/common.h 有如下宏定义: #ifdef DEBUG #define debu ...
- Android ROM开发(三)——精简官方ROM并且内置ROOT权限,开启Romer之路
Android ROM开发(三)--精简官方ROM并且内置ROOT权限,开启Romer之路 相信ROM的相关信息大家通过前几篇的学习都是有所了解了,这里就不在一一提示了,这里我们下载一个官方包,我们还 ...
- 算法之路 level 01 problem set
2992.357000 1000 A+B Problem1214.840000 1002 487-32791070.603000 1004 Financial Management880.192000 ...
- z-albert之开启博文之路
其实注册博客园已经蛮久的了,一直都只是停留在看,却没有自己动手一篇属于自己的技术博文.之所以以前一直没写,以前没有工作,一直都是小白.然而今天为什么感写了呢,并不是自己比以前懂得多多少,而是希望将自己 ...
- 栈 队列 hash表 堆 算法模板和相关题目
什么是栈(Stack)? 栈(stack)是一种采用后进先出(LIFO,last in first out)策略的抽象数据结构.比如物流装车,后装的货物先卸,先转的货物后卸.栈在数据结构中的地位很重要 ...
随机推荐
- PHP版本Non Thread Safe和Thread Safe如何选择?区别是什么?
PHP版本分为Non Thread Safe和Thread Safe,Non Thread Safe是指非线程安全,Thread Safe是指线程安全,区别是什么?如何选择? Non Thread S ...
- Pytest(12)pytest缓存
前言 pytest 运行完用例之后会生成一个 .pytest_cache 的缓存文件夹,用于记录用例的ids和上一次失败的用例. 方便我们在运行用例的时候加上--lf 和 --ff 参数,快速运行上一 ...
- Java初体验
参考书籍「Java语言程序设计基础篇」 比特与字节 计算机中只有0和1,二进制,即比特(bit,二进制数): 字节(byte)是最小的存储单元,每个字节有8个比特组成 即:1byte=8bit 各种数 ...
- PTA 乙 1001
1001 害死人不偿命的(3n+1)猜想 题目描述 卡拉兹(Callatz)猜想: 对任何一个正整数 n,如果它是偶数,那么把它砍掉一半:如果它是奇数,那么把 (3n+1) 砍掉一半.这样一直反复砍下 ...
- MySQL常用SQL语句2
-- 1创建student和score表 CREATE TABLE Student( Id INT(10) PRIMARY KEY auto_increment, Name VARCHAR(20) N ...
- 2019 ccpc秦皇岛
1006 (dfs) #include <bits/stdc++.h> using namespace std; const int inf = 0x3f3f3f3f; const dou ...
- AtCoder Beginner Contest 176 E - Bomber (思维)
题意:有一张\(H\)x\(W\)的图,给你\(M\)个目标的位置,你可以在图中放置一枚炸弹,炸弹可以摧毁所在的那一行和一列,问最多可以摧毁多少目标. 题解:首先我们记录某一行和某一列目标最多的数目, ...
- CodeForces 630Q Pyramids(数学公式)
IT City administration has no rest because of the fame of the Pyramids in Egypt. There is a project ...
- Codeforces Round #645 (Div. 2) D、The Best Vacation
题目链接:The Best Vacation 题意: 给你n个月份,每一个月份有di天.你可以呆在那里x天(x天要连续),如果你在某月的第y天呆在这.那么你的拥抱值就加y 1<=n<=2e ...
- VMX - block by NMI和 NMI unblockinig due to IRET 之间的关系
相关SDM章节: 27.2.3- Information About NMI Unblocking Due to IRET 最近收到同事发来的一个问题,即: VMCS 中的 Guest Interru ...