python利用爬虫获取百度翻译,爱词霸翻译结果,制作翻译小工具
先看效果展示(仅作学习使用,非商业)
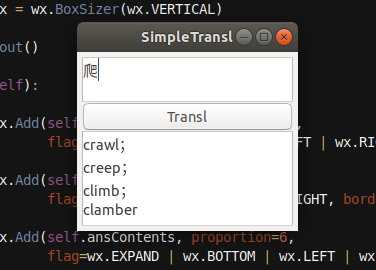
效果图是采用的 爱词霸 翻译,百度翻译 也实现了,只不过被注释了。
学计算机很多时候碰到生词,每次打开手机/浏览器翻译总觉得很麻烦,就想着自己写一个软件,自己去实现字典又太麻烦了,就想借着网上的翻译网站,做个爬虫。于是就学了下python,开始了爬虫之旅。
代码开始部分:
# -*- encoding: utf-8 -*- import wx
import requests
import re
import bs4
import json
import time
from requests import Session # 界面与逻辑分离
本着面向对象的编程思想,就把 界面实现,和 逻辑部分给分开了
定义了两个类,一个处理 爬虫请求(Handler),一个处理界面部分(Window)
接下来是 Handler 类:
class Handler():
def __init__(self): # self.armUrl = r'https://fanyi.baidu.com/transapi' # 爱词霸
self.mainUrl = r'http://www.iciba.com/'
# 爱词霸
self.armUrl = "" self.headers = {
'User-Agent':
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0',
} # self.data = {
# 'transtype': 'ente'
# } self.session = Session() # self.__initial()
#
# def __initial(self):
#
# r = requests.get(url = self.mainUrl, headers = self.headers)
# self.session.cookies = r.cookies # def setData(self, dict):
# self.data.update(dict) # 爱词霸
def mendUrl(self, query):
self.armUrl = self.mainUrl + query def requestText(self):
r = self.session.get(url = self.armUrl) soup = bs4.BeautifulSoup(r.content, 'lxml') try:
p = soup.find_all('p')[0] ans = ""
for span in p.find_all('span'):
ans += span.string + '\n' return ans except:
return "you fuck it up !!!" @property
def text(self):
return self.requestText()
Window 类部分:
class Window():
def __init__(self, handler):
self.win = wx.Frame(None, title = 'SimpleTransl', size = (200, 150))
self.bkg = wx.Panel(self.win)
self.handler = handler self.translBtn = wx.Button(self.bkg, label = 'Transl')
self.waitContents = wx.TextCtrl(self.bkg, style = wx.TE_MULTILINE)
self.ansContents = wx.TextCtrl(self.bkg, style = wx.TE_MULTILINE) self.vbox = wx.BoxSizer(wx.VERTICAL) self.layout() def layout(self): self.vbox.Add(self.waitContents, proportion=3,
flag=wx.EXPAND | wx.TOP | wx.LEFT | wx.RIGHT, border=5) self.vbox.Add(self.translBtn, proportion=1,
flag=wx.EXPAND | wx.LEFT | wx.RIGHT, border=5) self.vbox.Add(self.ansContents, proportion=6,
flag=wx.EXPAND | wx.BOTTOM | wx.LEFT | wx.RIGHT, border=5) self.translBtn.Bind(wx.EVT_BUTTON, self.transl) self.bkg.SetSizer(self.vbox) def transl(self, event):
# f, t = self.checkLang()
#
# data = {
# 'from' : f,
# 'to' : t,
# 'query' : self.waitContents.GetValue()
# } # self.handler.setData(dict = data) # 爱词霸
self.handler.mendUrl(self.waitContents.GetValue()) self.ansContents.SetValue(self.handler.text) # def checkLang(self):
#
# txt = self.waitContents.GetValue()
#
# if not txt:
# return ('error', 'error')
#
# else:
# if 'a' <= txt[0] <= 'z' or 'A' <= txt[0] <= 'Z':
# return ('en', 'zh')
#
# else:
# return ('zh', 'en')
# def show(self): self.win.Show()
以上注释的部分是 百度翻译实现,取消注释,并且把 有 ‘爱词霸’ 标注部分注释就可以使用百度翻译实现了(但,requestsText 函数 提取信息要自己实现)
Window 类就是实现界面,定义了一个Button,两个 TextCrtl,并且给 翻译按钮绑定了一个事件,用于翻译。通过 构造函数,和 layout 函数 实现。
下面是 主函数:
if __name__ == '__main__':
app = wx.App()
handler = Handler()
window = Window(handler = handler)
window.show()
app.MainLoop()
PS.功能比较简单,后期可以拓展,比如 读音,界面美化等。。
这里用爱词霸展示是有原因的, 在百度翻译里,只能提取出一个非常简单的意思,没办法提供丰富的翻译(有那位小伙伴解决了这个问题,可以告诉我)
比如 :下面是 百度翻译 返回的信息

你可以获取 data 下的 { src :爬 }
但却获取不了 { word_means [... ] } 里面的更加详细、有用的信息。
解决了这个问题的小伙伴麻烦告知下(我再去补一下 web 的知识看看能不能解决)。
python利用爬虫获取百度翻译,爱词霸翻译结果,制作翻译小工具的更多相关文章
- python 利用爬虫获取页面上下拉框里的所有国家
前段时间,领导说列一下某页面上的所有国家信息,话说这个国家下拉框里的国家有两三百个,是第三方模块导入的,手动从页面拷贝,不切实际,于是想着用爬虫去获取这个国家信息,并保存到文件里. 下面是具体的代码, ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- Python实现将爱词霸每日一句定时推送至微信
前言 前几天在网上看到一篇文章<教你用微信每天给女票说晚安>,感觉很神奇的样子,随后研究了一下,构思的确是巧妙.好,那就开始动工吧!服务器有了,Python环境有了,IDE打开了...然而 ...
- python爬虫获取百度图片(没有精华,只为娱乐)
python3.7,爬虫技术,获取百度图片资源,msg为查询内容,cnt为查询的页数,大家快点来爬起来.注:现在只能爬取到百度的小图片,以后有大图片的方法,我会陆续发贴. #!/usr/bin/env ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- Selenium2+python自动化34-获取百度输入联想词
前言 最近有小伙伴问百度输入后,输入框下方的联想词如何定位到,这个其实难度不大,用前面所讲的元素定位完全可以定位到的. 本篇以百度输入框输入关键字匹配后,打印出联想词汇. 一.定位输入框联想词 1.首 ...
- Selenium2+python自动化34-获取百度输入联想词【转载】
前言 最近有小伙伴问百度输入后,输入框下方的联想词如何定位到,这个其实难度不大,用前面所讲的元素定位完全可以定位到的. 本篇以百度输入框输入关键字匹配后,打印出联想词汇. 一.定位输入框联想词 1.首 ...
- 手把手教你用Python网络爬虫获取网易云音乐歌曲
前天给大家分享了用Python网络爬虫爬取了网易云歌词,在文尾说要爬取网易云歌曲,今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将 ...
- Python爬虫获取百度贴吧图片
#!/usr/bin/python# -*- coding: UTF-8 -*-import urllibimport re文章来源:https://www.cnblogs.com/Axi8/p/57 ...
随机推荐
- 谁能告诉我如何通过Jenkins完成分布式环境搭建并执行自动化脚本
今天我们接着昨天的内容,看一看如何完成Jenkins分布式环境的搭建和使用,因为我之前也是自己一个人摸索的,如果有不对的地方,请各位看官私信指出. 新增分布式部署节点 在系统管理/节点管理中点击新建 ...
- scrapy分布式浅谈+京东示例
scrapy分布式浅谈+京东示例: 学习目标: 分布式概念与使用场景 浅谈去重 浅谈断点续爬 分布式爬虫编写流程 基于scrapy_redis的分布式爬虫(阳关院务与京东图书案例) 环境准备: 下载r ...
- amazeui 验证按钮扩展
做一个发送验证码按钮,点击后要60秒之后才能再次点击,利用原有的amazeui样式做的一些扩展,当然主题功能的代码全都是自己写的,也可以脱离amazeUi 自己完成这个功能按钮 代码如下: <! ...
- 巩固复习(Hany驿站原创)_python的礼物
Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https://www ...
- 将"089,0760,009"变为 89,760,9
remove_zeros = lambda s: ','.join(map(lambda sub: str(int(sub)), s.split(','))) remove_zeros("0 ...
- PHP is_float()、 is_double()、is_real()函数
is_float() 函数用于检测变量是否是浮点型. 别名函数:is_double(),is_real().高佣联盟 www.cgewang.com 注意: 若想测试一个变量是否是数字或数字字符串(如 ...
- PDOStatement::bindParam
PDOStatement::bindParam — 绑定一个参数到指定的变量名(PHP 5 >= 5.1.0, PECL pdo >= 0.1.0) 说明 语法 bool PDOState ...
- CF R 632 div2 1333D Challenges in school №41
LINK:Challenges in school №41 考试的时候读错题了+代码UB了 所以wa到自闭 然后放弃治疗. 赛后发现UB的原因是 scanf读int类型的时候 宏定义里面是lld的类型 ...
- Linux发行版-Manjaro
Manjaro是什么? 一个基于Arch系列,开源的linux发行版 Mnajrao官网了解更多,这里不做更多阐述内容 为什么使用Manjaro 第一点,为了方便自己隔离腾讯网游 第二点,更方便的学习 ...
- Docker之Ubuntu上使用Docker的简易教程
Ubuntu上使用Docker的简易教程 原始文档:https://www.yuque.com/lart/linux/fp6cla 说在开头 在天池的比赛中涉及到了docker的使用.经过多番探究,大 ...