爬虫-使用lxml解析html数据
使用lxml之前,我们首先要会使用XPath。利用XPath,就可以将html文档当做xml文档去进行处理解析了。
一、XPath的简单使用:
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
1.开发工具的安装
Chrome浏览器,可以安装Xpath Helper插件。如果从网上下载插件,得到的文件以.crx结尾,不能直接添加到浏览器扩展程序里,我们需要将这个文件改为.zip结尾,然后新建一个文件夹,将.zip文件解压到新建的文件夹内。通过浏览器的扩展程序-加载已解压的扩展程序-选择该文件夹就可以安装好插件了。
2.语法
XPath使用路径表达式来选取XML文档中的节点或者节点集。节点是通过沿着路径(path)或步(steps)来选取的。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
XML实例文档
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore>下面的例子中都使用这个文档进行演示。
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常见路径表达式:
| 表达式 | 描述 |
| 节点名 | 必须是根节点,选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
示例:
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
示例:
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点和属性
XPath 通配符可用来选取未知的 XML 元素和属性。
通配符:
| 通配符 | 描述 |
| * | 匹配任何节点。 |
| @* | 匹配任何属性 |
示例:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径
示例:
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
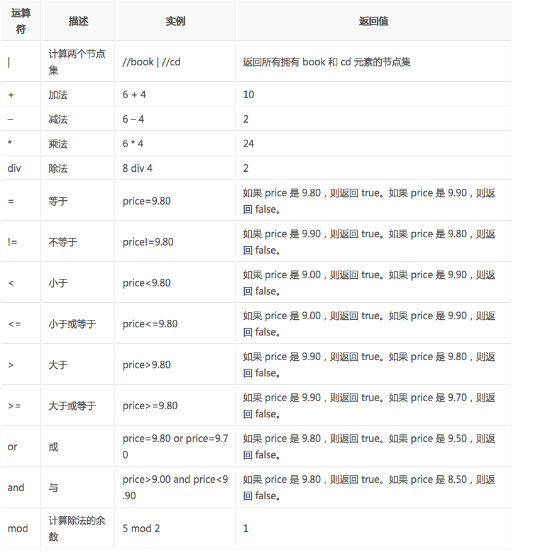
3.运算符
下面列出了可用在 XPath 表达式中的运算符:
二、lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用C实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath语法,来快速的定位特定元素以及节点信息。
1.安装
- 需要安装C语言库,可使用 pip 安装
sudo pip3 install lxml
2.简单使用(仅列出常见的一些操作)
etree
- 解析html数据,主要就是用到lxml库中的etree
etree.HTML()
- 参数为字符串,读取字符串,返回html元素,并且会自动修正html代码,比如缺少html标签和body标签,则会自动添上
etree.parse()
- 参数为文件名,从文件读取内容,返回_ElementTree
etree.tostring()
- 参数为元素或者元素树,序列化成字节类型
Element.xpath()或者_ElementTree.xpath()
- 参数是xpath表达式字符串,返回的是列表。如果表达式选取的是元素,则列表由元素组成,如果表达式选取的是属性,则列表由属性的值组成
Element.tag
- 元素tag属性,返回元素标签名
Element.text
- 元素text属性,返回元素内容
示例:
In [1]: from lxml import etree #导入etree In [2]: text = '''
...: <div>
...: <ul>
...: <li class="item-0"><a href="link1.html">first item</a></li>
...: <li class="item-1"><a href="link2.html">second item</a></li>
...: <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
...: <li class="item-1"><a href="link4.html">fourth item</a></li>
...: <li class="item-0"><a href="link5.html">fifth item</a></li>
...: </ul>
...: </div>
...: ''' In [3]: html = etree.HTML(text) #读取字符串 In [4]: html #返回html元素
Out[4]: <Element html at 0x7f3ad0bb8340> In [5]: etree.tostring(html)#序列化成字节类型,并自动添上了html标签和body标签
Out[5]: b'<html><body><div>\n <ul>\n <li class="item-0"><a href="link1.html">first item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a></li>\n </ul>\n</div>\n</body></html>' In [6]: html2 = etree.parse('./test.html')#从文件读取 In [7]: html2 #返回元素树
Out[7]: <lxml.etree._ElementTree at 0x7fc54d818d00> In [8]: etree.tostring(html2)
Out[8]: b'<body>\n <div>\n <ul>\n <li class="item-0"><a href="link1.html">first item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a></li>\n </ul>\n </div>\n</body>' In [9]: element_list = html.xpath('//a')#调用元素的xpath方法,选取文档中的所有a元素 In [10]: element_list #返回所有a元素组成的列表
Out[10]:
[<Element a at 0x7fc54d849ec0>,
<Element a at 0x7fc54d91b080>,
<Element a at 0x7fc54d86fc80>,
<Element a at 0x7fc54d878e40>,
<Element a at 0x7fc54d878040>] In [11]: element_list[0].tag #元素tag属性,返回标签名
Out[11]: 'a' In [12]: element_list[0].text #元素text属性,返回元素内容
Out[12]: 'first item' In [13]: attr_value_list = html.xpath('//a/@href') #调用元素的xpath方法,选取文档中所有a元素的href属性 In [14]: attr_value_list #返回href属性值组成的列表
Out[14]: ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
爬虫-使用lxml解析html数据的更多相关文章
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- python简单爬虫 用lxml解析页面中的表格
目标:爬取湖南大学2018年在各省的录取分数线,存储在txt文件中 部分表格如图: 部分html代码: <table cellspacing="0" cellpadding= ...
- 第二节:web爬虫之lxml解析库
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高.
- 网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇! 一.介绍: selenium最初是一 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- pytho爬虫使用bs4 解析页面和提取数据
页面解析和数据提取 关注公众号"轻松学编程"了解更多. 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的 ...
- 爬虫(6) - 网页数据解析(2) | BeautifulSoup4在爬虫中的使用
什么是Beautiful Soup库 Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简 ...
- Python爬虫10-页面解析数据提取思路方法与简单正则应用
GitHub代码练习地址:正则1:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac15_RE1.py 正则2:match. ...
- pyspider示例代码:解析JSON数据
pyspider示例代码官方网站是http://demo.pyspider.org/.上面的示例代码太多,无从下手.因此本人找出一下比较经典的示例进行简单讲解,希望对新手有一些帮助. 示例说明: py ...
随机推荐
- 小兔子有颗玻璃心A版【转】
作者:诸君平身链接:https://www.zhihu.com/question/49179166/answer/116926446来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- js下 Day15、正则表达式
一.正则表达式简介 什么是正则表达式 正则表达式,也叫规则表达式, 是对字符串操作的一种逻辑公式. 为什么要使用正则? 1.使用极简单的方式,去匹配字符串 2.速度快,代码少 3.在复杂的字符串中快速 ...
- 多任务-python实现-多线程共享全局变量(2.1.3)
@ 目录 1.全局变量的修改 2.全局变量在多线程中的共享 3.多线程可能遇到的问题 1.全局变量的修改 代码实现 num = 100 nums = [11,22] def test(): globa ...
- 推荐一款最强Python自动化神器!再也不用写代码了!
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 搞过自动化测试的小伙伴,相信都知道,在Web自动化测试中,有一款自动化测试神器工具: seleniu ...
- Python -- 修改、添加和删除元素
大多数列表将是动态的,这意味着列表创建后,将随着程序的运行增删元素. 修改列表元素 修改列表元素的语法与访问列表元素的语法类似.要修改列表元素,可指定表名和要修改的元素指引,再指定该元素的新值. #代 ...
- CSS鼠标指针cursor样式
参考来源:W3SCHOOL 有时我们需要在CSS布局时设定特定的鼠标指针样式,这时可以通过设定cursor来实现: url: 需使用的自定义光标的 URL. 注释:请在此列表的末端始终定义一种普通的光 ...
- Spring Cloud 2020.0.0正式发布,再见了Netflix
目录 ✍前言 版本约定 ✍正文 Spring Cloud版本管理 与Spring Boot版本对应关系 当前支持的版本 阻断式升级(不向下兼容) 1.再见了,Netflix Netflix组件替代方案 ...
- Django中关于“CSRF verification failed. Request aborted”的问题
遇到该问题的情境 在Django中采用Ajax提交表单,涉及到跨域问题. 解决措施 在html页面中的表单内添加如下代码: {% csrf_token %} 在视图函数所在的py文件中添加如下代码: ...
- java.lang.NoSuchMethodError的解决办法
开发一个知识图谱在线服务(基于springcloud+vue)构建中医理论的知识图谱构建帕金森的知识图谱提供免费的知识图谱服务,希望能为朋友们的生活.学习.工作提供帮助(敬请期待)PS:关注后,点击头 ...
- easyui中设置开始日期只能选择比结束日期小的日期,js代码获取日期的值
$("#start_date").datebox({ onSelect: function (beginDate) { $('#end_date').datebox().dateb ...