LWJGL3的内存管理,第二篇,栈上分配
LWJGL3的内存管理,第二篇,栈上分配
简介
为了讨论LWJGL在内存分配方面的设计,本文将作为该系列随笔中的第二篇,用来讨论在栈上进行内存分配的策略,该策略在 LWJGL3 中体现为以 MemoryStack 类为核心的一系列API,旨在为 “容量较小, 生命周期短,而又需要频繁分配” 的内存分配需求提供一个统一、易用、高性能的,优雅的解决方案。
预期
通过阅读本文,读者在查看LWJGL3 源代码时,能够看懂以下用户代码用到的API背后的逻辑和设计,以及从需求出发,站在设计者的角度,了解到为何需要如此设计,它的优点和局限性又在哪里,哪些场景适用哪些场景不适用。
// Dump the matrix into a float buffertry (MemoryStack stack = MemoryStack.stackPush()) {glUniformMatrix4fv(location, false, value.get(stack.mallocFloat(16)));}
LWJGL3 在内存分配方面需要解决的问题
在C语言的OpenGL编程中,如下这种内存分配和使用方式是非常常见的
GLuint vbo;glGenBuffers(1, &vbo);
上面这段代码,我们分配定义了一个变量vbo,这本质上是分配了一块内存, glGenBuffers函数执行结束后,&vbo指向的内存区域将被填充一个值,这个值将用于项目中后续的操作。
这本质上是“分配内存,写入数据,并将数据传递给 native 代码”。
首先,不能考虑堆内内存分配,否则数据将会在native heap 和 java heap 之间拷贝,存在性能损失。
其次,也不能滥用 ByteBuffer.allocateDirect ,因为:
- 慢,比原生的 malloc() 调用要慢得多
- 通常有默认的大小限制(-XX:MaxDirectMemorySize);
- 需要两个GC周期才能完成内存释放,第一个周期需要回收引用对象,第二个周期才能完成堆外内存的回收。这在高负载情况下使得OOM更容易发生。
因此势必要设计为“一次分配,多次使用”。
LWJGL1 和 LWJGL2,以及其他类似的绑定库,都是通过分配一次缓冲区,然后将这个缓冲区缓存起来,进行复用来解决的,这当然能够解决问题。但是又造成了其他问题:
- 将导致 ugly code;
- 对共享缓冲区的访问需要同步,而同步降低了性能。
而 LWJGL3 舍弃了这种全局缓存的做法。栈上分配内存的策略中,LWJGL3 每个线程只需要申请一次直接内存,并存放到ThreadLocal中,使用“栈”这种数据结构来管理,支持直接内存的分配和复用。下面我们开始介绍它具体是如何做到的。
MemoryStack
LWJGL3 的栈上内存分配策略,是以 MemoryStack 为核心的。从该类的名字就可以看出,这是一个内存栈。
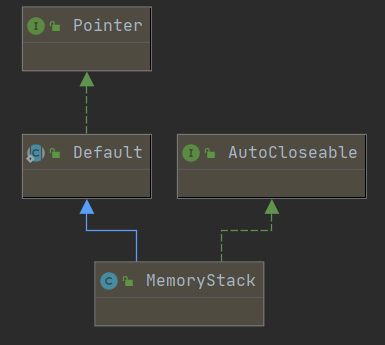
如上图所示:
它实现了 AutoClosable 接口,用于配合 try-with-resource 语法,在离开try-catch块后在close() 方法里执行自己的出栈操作,具体后面会介绍
它继承了 Pointer.Default 类,该类提供了wrap方法,用于构造特定类型的缓冲区引用对象,MemoryUtil::wrap是一样的作用
每个线程会在自己的ThreadLocal中持有一个 MemoryStack实例,该实例是第一次从ThreadLocal中get()时才延迟创建出来,创建时该实例会使用ByteBuffer.allocateDirect 创建一块 64K 大小的堆外内存。
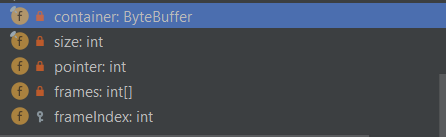
这块堆外内存的引用对象最后就由 container 字段持有;
而size记录了它的大小;
pointer 就是栈顶指针,初始值和size相同;
frame数组就是栈帧数组,默认最多支持8帧。
到此为止,栈的创建工作就完成了。由于该MemoryStack实例是在ThreadLocal里,既可以复用,又避免了线程安全问题。
下面我们看它是如何入栈出栈的。
入栈
对应到的就是 stackPush() 方法。该方法仅是记录一下入栈操作,保存该栈帧的栈顶位置,还没有真正对内存进行操作。
public MemoryStack push() {if (frameIndex == frames.length) {frameOverflow();}frames[frameIndex++] = pointer;return this;}
对内存的操作是由 stack.mallocFloat(16)完成的。mallocFloat实现如下
public FloatBuffer mallocFloat(int size) { return MemoryUtil.wrap(BUFFER_FLOAT, nmalloc(4, size << 2), size); }
而 wrap 方法实现如下,其实就是先创建一个 FloatBuffer的实例,该实例仅仅是一个引用对象,下面的一系列put操作就是对该对象的初始化,做好读写准备。该方法执行完后,就从64K的直接内存中,又划分出了 16个字节。达到了快速的内存分配。
static <T extends Buffer> T wrap(Class<? extends T> clazz, long address, int capacity) {T buffer;try {buffer = (T)UNSAFE.allocateInstance(clazz);} catch (InstantiationException e) {throw new UnsupportedOperationException(e);}UNSAFE.putLong(buffer, ADDRESS, address);UNSAFE.putInt(buffer, MARK, -1);UNSAFE.putInt(buffer, LIMIT, capacity);UNSAFE.putInt(buffer, CAPACITY, capacity);return buffer;}
这里要知道,上面进行栈上内存分配时用的 UNSAFE.allocateInstance(clazz) ,这种方式和 DirectByteBuffer不同,并不会被GC回收。这正好是符合我们的需求的,因为:
这块内存本就该由 MemoryStack管理,不能随意释放,还要留作复用;
在Java代码中竟然做到了无GC性能损耗的内存分配,这种感觉就像在写C一样。这也是 LWJGL3 最大的设计亮点。
出栈
出栈操作是借助于 try-with-resources 语法糖来自动完成的。通过将 MemoryStack 继承 AutoClosable,在离开try-catch块后,close() 方法将会被执行。
@Overridepublic void close() {pop();}
public MemoryStack pop() {pointer = frames[--frameIndex];return this;}
出栈操作如此简单。API的使用也相当优雅,到此,读者有没有体会到美呢。
本文似乎到此应该就结束了,但是,其实在实现中,有非常多的细节和难点。由于上面主要介绍主要思路和设计,所以忽略了细节。下面我们将仔细看看,为了完成该优雅设计,背后付出的努力和克服的困难。
获取堆外缓冲区的地址
这里的“堆外缓冲区”指的是 MemoryStack 持有的那个引用对象指向的堆外内存。为什么要获取它的地址呢?因为在栈上分配内存时,需要知道栈顶的位置,不然怎么分配。
可能出于读者的意料,这其实是一件比较困难的事情,虽然 Buffer类(ByteBuffer 类继承了 Buffer)内部有"address" 字段记录了地址信息(只有当Buffer引用指向堆外缓冲区时,该字段才会被赋值),但是由于以下两个原因,我们不能直接获取到它:
- 该字段的修饰符是 private,且没有提供 public 的 API 用以获取该字段的值;
- 该字段名在不同平台的JDK实现里并不一定相同(实际上确实是不同的)。
如果我们自己来设计,我们就需要这样一个方法,它能够获取一个堆外缓冲区的地址,如下这个函数的原型就是符合需求的
public static long getVboBufferAddress(ByteBuffer directByteBuffer)
如果不考虑跨平台,借助于Unsafe::objectFieldOffset方法,在 Oracle JDK 上可以做如下实现,来获取堆外缓冲区的地址:
public static long getVboBufferAddress1(ByteBuffer directByteBuffer) throws NoSuchFieldException {Field address = Buffer.class.getDeclaredField("address");long addressOffset = UNSAFE.objectFieldOffset(address);long addr = UNSAFE.getLong(directByteBuffer, addressOffset);return addr;}
这里的 UNSAFE 是 sun.misc.Unsafe 类的实例,预备知识里已经有相关说明。
如果要考虑跨平台 ,则因为直接堆外缓冲区地址对应的字段名在不同平台的不同,就无法使用 Unsafe类的 objectFieldOffset 的方法来获取字段偏移量了。
于是需要另辟蹊径,来获取该字段在对象中的偏移量,这可以采用如下步骤来做到:
先使用 JNI 提供的 的 NewDirectByteBuffer 函数,在指定地址处获取一块容量为0的直接堆外直接缓冲区,这里有两点需要理解:
- 该地址是指定的,即该地址值是一个魔法值。
- 之所以容量为0,是因为这块缓冲区并不是要用来存东西,而只是用来帮助我们,来找到那个存储了直接堆外缓冲区地址的字段 (在 Oracle JDK 上是名为address的字段)在对象内存布局中的偏移量。
通过上一步操作,我们现在有了一个 ByteBuffer 对象;
对该 ByteBuffer 对象从偏移量为0的地址开始扫描,由于该对象内部肯定有一个long型字段的值为之前指定的魔法值,因此使用魔法值进行逐个比较,就能找到该字段,同时也就找到了该字段在对象内存布局中的偏移量。
具体实现如下(这里的魔法值,为了方便我自己,直接采用了上面代码中一次运行结果的 addr 的值)
/*** 考虑跨平台的情况** @param directByteBuffer* @return* @throws NoSuchFieldException*/public static long getVboBufferAddress2(ByteBuffer directByteBuffer) throws NoSuchFieldException {long MATIC_ADDRESS = 720519504;ByteBuffer helperBuffer = newDirectByteBuffer(MATIC_ADDRESS, 0);long offset = 0;while (true) {long candidate = UNSAFE.getLong(helperBuffer, offset);if (candidate == MATIC_ADDRESS) {break;} else {offset += 8;}}long addr = UNSAFE.getLong(directByteBuffer, offset);return addr;}
上面代码中的 newDirectByteBuffer 是一个native方法,其实现如下。下面的代码是通过javah命令生成的,网上有许多文章进行了JNI方面的介绍,大家可以搜一下自己试试。
#include "net_scaventz_test_mem_MyMemUtil.h"JNIEXPORT jobject JNICALL Java_net_scaventz_test_mem_MyMemUtil_newDirectByteBuffer(JNIEnv* __env, jclass clazz, jlong address, jlong capacity) {void* addr = (void*)(intptr_t) address;return (*__env)->NewDirectByteBuffer(__env, addr, capacity);}
自己动手写一个 MemoryStack
下面的代码是我为了理解MemoryStack的设计,做的一个简单实现,用来做一些验证。供读者参考和我自己将来复习。
public class MyMemoryStack {private ByteBuffer directByteBuffer;private static ThreadLocal<MyMemoryStack> tls = ThreadLocal.withInitial(MyMemoryStack::new);public MyMemoryStack() {directByteBuffer = ByteBuffer.allocateDirect(64 * 1024);}public static ByteBuffer get() {return tls.get().getDirectByteBuffer();}public ByteBuffer getDirectByteBuffer() {return directByteBuffer;}}
当我们调用LWJGL3 的 glGenBuffers 函数时,便可以像如下这样使用 MyMemoryStack
package net.scaventz.test.mem;import org.lwjgl.opengl.GL15C;import java.nio.ByteBuffer;/*** @author scaventz* @date 2020-10-15*/public class MyOpenGLBinding {public static int glGenBuffers() {try {ByteBuffer directByteBuffer = MyMemoryStack.get();long address = MyMemUtil.getVboBufferAddress2(directByteBuffer);// 下面是 LWJGL3 提供的 API,其最终使用 JNI 调用了 native API,// 由于本文的重点不在这里,所以无需关心它的细节GL15C.nglGenBuffers(1, address);return directByteBuffer.get();} catch (NoSuchFieldException e) {e.printStackTrace();return -1;}}}
package net.scaventz.test.mem;import java.nio.ByteBuffer;/*** @author scaventz* @date 2020-10-15*/public class MyMemoryStack {private ByteBuffer directByteBuffer;private static ThreadLocal<MyMemoryStack> tls = ThreadLocal.withInitial(MyMemoryStack::new);public MyMemoryStack() {directByteBuffer = ByteBuffer.allocateDirect(64 * 1024);}public static ByteBuffer get() {ByteBuffer directByteBuffer = tls.get().getDirectByteBuffer();directByteBuffer.clear();return directByteBuffer;}public ByteBuffer getDirectByteBuffer() {return directByteBuffer;}}
package net.scaventz.test.mem;import sun.misc.Unsafe;import java.lang.reflect.Field;import java.nio.Buffer;import java.nio.ByteBuffer;/*** @author scaventz* @date 2020-10-12*/public class MyMemUtil {private static Unsafe UNSAFE = getUnsafe();static {System.loadLibrary("mydll");}public static native ByteBuffer newDirectByteBuffer(long address, long capacity);/*** 不考虑跨平台的情况** @param directByteBuffer* @return* @throws NoSuchFieldException*/public static long getVboBufferAddress1(ByteBuffer directByteBuffer) throws NoSuchFieldException {Field address = Buffer.class.getDeclaredField("address");long addressOffset = UNSAFE.objectFieldOffset(address);long addr = UNSAFE.getLong(directByteBuffer, addressOffset);return addr;}/*** 考虑跨平台的情况** @param directByteBuffer* @return* @throws NoSuchFieldException*/public static long getVboBufferAddress2(ByteBuffer directByteBuffer) throws NoSuchFieldException {long MAGIC_ADDRESS = 720519504;ByteBuffer helperBuffer = newDirectByteBuffer(MATIC_ADDRESS, 0);long offset = 0;while (true) {long candidate = UNSAFE.getLong(helperBuffer, offset);if (candidate == MAGIC_ADDRESS) {break;} else {offset += 8;}}long addr = UNSAFE.getLong(directByteBuffer, offset);return addr;}private static Unsafe getUnsafe() {try {Field field = Unsafe.class.getDeclaredField("theUnsafe");field.setAccessible(true);Unsafe unsafe = (Unsafe) field.get(null);return unsafe;} catch (Exception e) {return null;}}}
Main函数中,vbo1和vbo2都能正常输出,这表明我们给 nglGenBuffers 传递的 address 值是正确的,MyMemoryStack 如预期正常工作。
总结
MemoryStack 的设计确实相当完美:
- 性能方面,该设计已经做了最大的努力,很难想象现阶段还有更好的方案;
- 对内存的分配和管理做了统一处理,代码结构变得清晰;
- 优雅,完全做到了无GC性能损耗的分配方式,特别是如果你意识到,实际上在原生API中, GLuint vbo 这样一个操作本身就是在执行栈上分配,便更能体会到这种设计的美感;感觉就像用Java在写C,不需要考虑GC了。
当然 MemoryStack 并非适用于所有场景
- 各个JVM实现都有默认的大小限制(-XX:MaxDirectMemorySize)
- 生命周期短,脱离作用域就会被回收
因此如果需要分配较大容量的内存,或者生命周期较长,则应该考虑使用MemoryUtil类的 malloc/free, 它是基于第三方库的,默认使用 jemalloc,我们将在下一篇随笔讨论包括它在内的另外两种策略。
LWJGL3的内存管理,第二篇,栈上分配的更多相关文章
- php7 改为从栈上分配内在的思路
php7的特点是规则上不从堆上分配内存,改为从栈上分配内存, 因为有些场景是从堆上分配内在后,还要手动释放内存,利用栈分配内在快的特点,在有需要的时候,再在堆上分配内在 但是栈上分配的内存,不能返回, ...
- 【LWJGL3】LWJGL3的内存分配设计,第一篇,栈上分配
简介 LWJGL (Lightweight Java Game Library 3),是一个支持OpenGL,OpenAl,Opengl ES,Vulkan等的Java绑定库.<我的世界> ...
- LWJGL3的内存管理,第一篇,基础知识
LWJGL3的内存管理,第一篇,基础知识 为了讨论LWJGL在内存分配方面的设计,我将会分为数篇随笔分开介绍,本篇将主要介绍一些大方向的问题和一些必备的知识. 何为"绑定(binding)& ...
- LWJGL3的内存管理,第三篇,剩下的两种策略
LWJGL3的内存管理,第三篇,剩下的两种策略 上一篇讨论的基于 MemoryStack 类的栈上分配方式,是效率最高的,但是有些情况下无法使用.比如需要分配的内存较大,又或许生命周期较长.这时候就可 ...
- LWJGL3的内存管理
LWJGL3的内存管理 LWJGL3 (Lightweight Java Game Library 3),是一个支持OpenGL,OpenAl,Opengl ES,Vulkan等的Java绑定库.&l ...
- LWJGL3的内存管理,简介及目录
LWJGL3的内存管理,简介及目录 LWJGL3 (Lightweight Java Game Library 3),是一个支持OpenGL,OpenAl,Opengl ES,Vulkan等的Java ...
- JVM内存管理——总结篇
JVM内存管理--总结篇 自动内存管理--总结篇 内存划分及作用 常见问题 内存划分及作用 程序计数器 线程私有.字节码行号指示器. 执行Java方法,计数器记录的是字节码指令地址:执行本地(Nati ...
- Java对象栈上分配
转自 https://blog.csdn.net/o9109003234/article/details/101365108 在学习Java的过程中,很多喜欢说new出来的对象分配一定在对上: 其实不 ...
- JVM之对象分配:栈上分配 & TLAB分配
1. Java对象分配流程 2. 栈上分配 2.1 本质:Java虚拟机提供的一项优化技术 2.2 基本思想: 将线程私有的对象打散分配在栈上 2.3 优点: 2.3.1 可以在函数调用结束后自行销毁 ...
随机推荐
- django rest_framework serializer的ManyRelatedField 和 SlugRelatedField使用
class BlogListSerializer(serializers.Serializer): id = serializers.IntegerField() user = BlogUserInf ...
- 我竟在arm汇编除法算法里找到了leetcode某道题的解法
今天讲讲arm汇编中除法的底层实现.汇编代码本身比较长了,如需参考请直接拉到文末. 下面我直接把arm的除法算法的汇编代码转译成C语言的代码贴出来,并进行解析. 因为篇幅有限,所以在此只解析无符号整型 ...
- 022 01 Android 零基础入门 01 Java基础语法 03 Java运算符 02 算术运算符
022 01 Android 零基础入门 01 Java基础语法 03 Java运算符 02 算术运算符 本文知识点:Java中的算术运算符 算术运算符介绍 算术运算符代码示例 注意字符串连接问题和整 ...
- centos配置WordPress(Apache+mysql+php)
.安装Apache 安装命令:sudo yum install httpd 启动服务:sudo service httpd start 在浏览器输入IP地址,正常应该显示Apache的欢迎页面 如果提 ...
- E: 无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用)
Linux下sudo apt-get install 安装时报错: 解决办法 1. 终端输入 ps -aux ,列出进程.找到含有apt'-get或者wget的进程, 直接sudo k ...
- java安全编码指南之:输入注入injection
目录 简介 SQL注入 java中的SQL注入 使用PreparedStatement XML中的SQL注入 XML注入的java代码 简介 注入问题是安全中一个非常常见的问题,今天我们来探讨一下ja ...
- 技术分享丨华为鲲鹏架构Redis知识二三事
摘要:华为云鲲鹏Redis,业界首个基于自研ARM-Based全栈整合的Redis云服务,支持双机热备的HA架构,提供单机.主备.Proxy集群.Cluster集群实例类型,满足高读写性能场景及弹性变 ...
- 如何win10 上访问虚拟机(linux)上redis方法
上一回linux上安装了redis,but在window上面连接不上/??? 配置了密码,不行, 防火墙端口打开了也不行??? 1. 首先要修改redis 的配置文件,找到bind节点,修改bind的 ...
- CSS字体属性与文本属性
CSS字体属性与文本属性 1. 字体属性 1.1 字体系列font-family p { font-family: "Microsoft Yahei";/*微软雅黑*/ } /*当 ...
- .NetCore 异步编程 - async/await
前言: 这段时间开始用.netcore做公司项目,发现前辈搭的框架通篇运用了异步编程方式,也就是async/await方式,作为一个刚接触的小白,自然不太明白其中原理,最重要的是,这个玩意如果不明白基 ...