【Python】直接赋值,深拷贝和浅拷贝
直接赋值: 对象的引用,也就是给对象起别名
浅拷贝: 拷贝父对象,但是不会拷贝对象的内部的子对象。
深拷贝: 拷贝父对象. 以及其内部的子对象
在之前的文章中,提到可变对象和不可变对象,接下来也是以这两者的区别进行展开
直接赋值
对于可变对象和不可变对象,将一个变量直接赋值给另外一个变量,两者 id 值一致,其实本质上是将变量量绑定到对象的过程.
>>> a=1
>>> b=a
>>> id(a) == id(b)
True
>>> c="string"
>>> d=c
>>> id(c) == id(d)
True
>>> e=[1,2,3]
>>> f=e
>>> id(e)==id(f)
True
关于修改新变量的值,对原有变量会产生的影响,在可变对象和不可变对象 中也做了讲述,这里通过几个例子,重新温习一下
不可变对象
>>> x=1
>>> y=x
>>> id(x)==id(y)
True
>>> id(1)==id(y)
True
>>>>>> id(x)
1500143776
>>> y=y+1
>>> y
2
>>> x
1
>>> id(x)==id(y)
False
>>> id(y)
1500143808
>>> id(x)
1500143776
对于不可变对象,修改赋值后的新变量,不会对原有变量造成任何影响.为什么出现这种现象呢?因为不可变对象一旦创建之后就不允许被改变.后面对 y 进行的操作,其实是重新创建一个对象并绑定的结果:
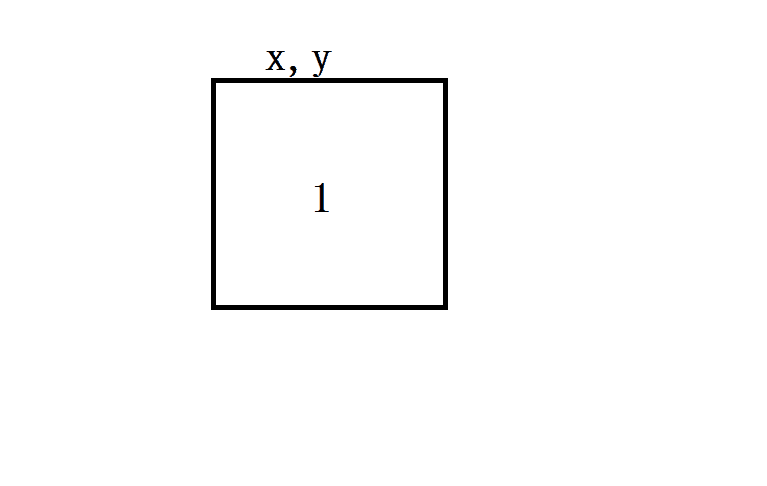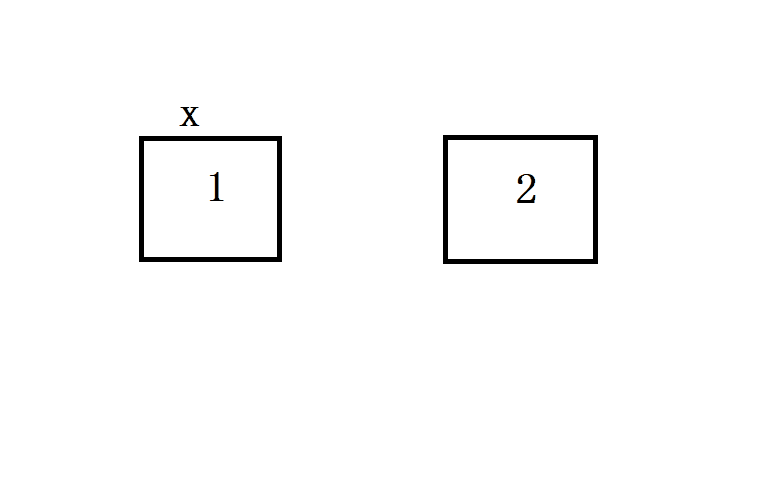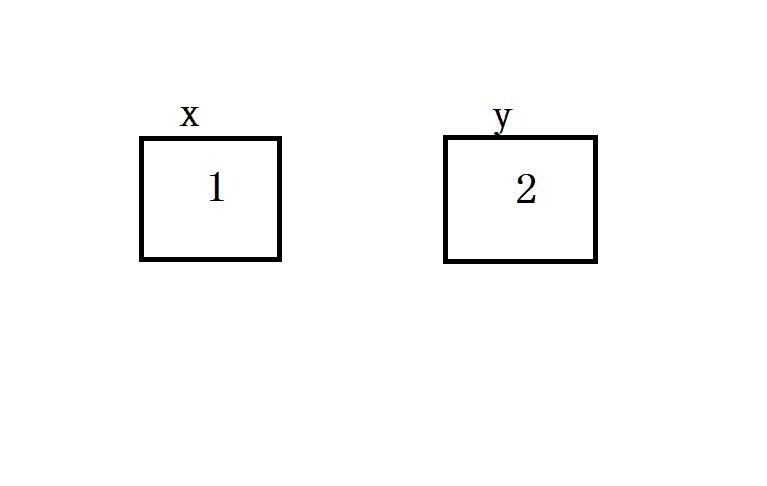
可变对象
>>> m=[1,2,3]
>>> n=m
>>> id(n)==id(m)
True
>>> id(m)
1772066764488
>>> id(n[0])
1772066764656
>>> n[0]=4
>>> n
[4, 2, 3]
>>> m
[4, 2, 3]
>>> id(n)==id(m)
True
>>> id(m)
1772066764488
对于可变对象,修改赋值后的变量,会对原有的变量造成影响,会导致其 value 值的改变,但是其 id 值保持不变
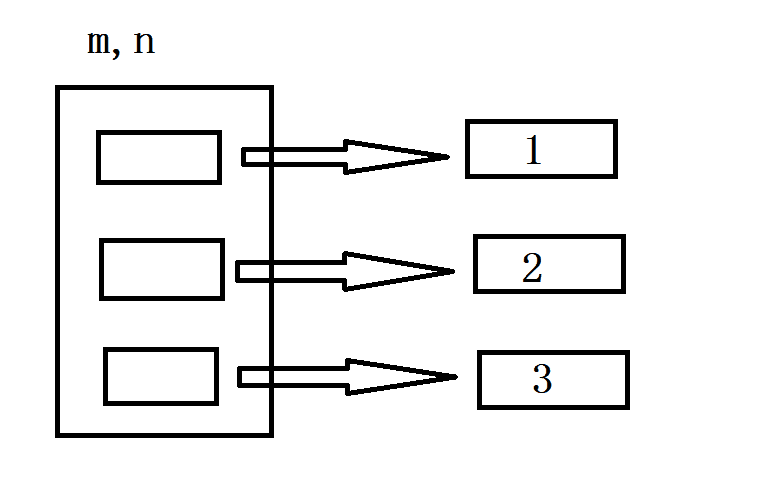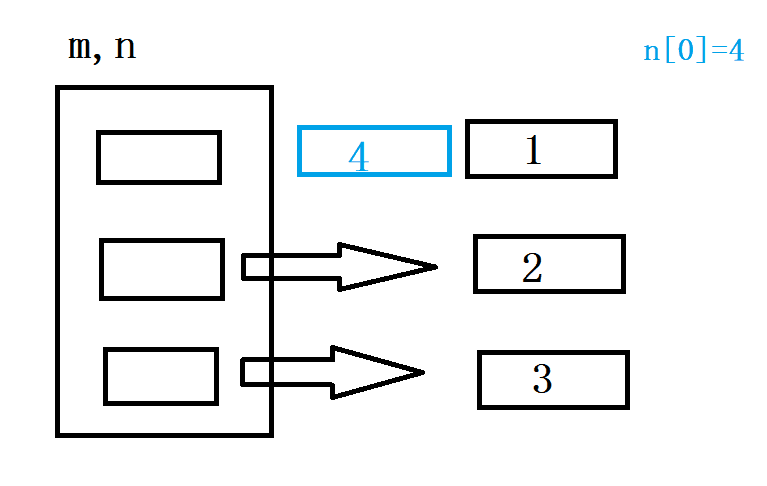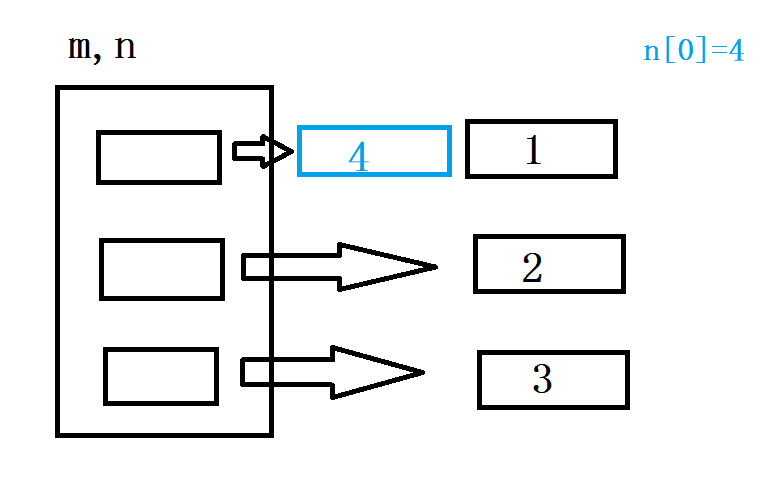
从上图不难看出,这个时候的 id(n[0]) 的值,和未修改前的 id值应该不一样,可以输出看一下
>>>id(n[0])
1772066764752 # 最初没有修改前是 1772066764656
n[0] 修改前后为什么 id 值出现改变呢? 首先需要明确一点 n[0] 绑定的是一个不可变对象,在文章的最初提到,不可变对象一旦创建就不允许修改.显然对 n[0] 进行修改,不能在绑定对象的内存上进行修改,那如何实现重新赋值呢?只能创建一个新的对象 4 ,然后将 n[0] 绑定到新的对象
浅拷贝和深拷贝
先看一下官方文档的定义
The difference between shallow and deep copying is only relevant for compound objects (objects that contain other objects, like lists or
class instances).
A shallow copy constructs a new compound object and then (to the
extent possible) inserts the same objects into it that the
original contains.
A deep copy constructs a new compound object and then, recursively,inserts copies into it of the objects found in the original.
从文档中不难看出,上面提到深拷贝和浅拷贝两者区别在于在复合对象,那接下来也只讨论复合对象.
浅拷贝
注意到官方文档也提到对浅拷贝和深拷贝的定义,从上文中不难看出,浅拷贝构建一个复合对象,然后将原有复合对象包含的对象插入到新的复合对象中
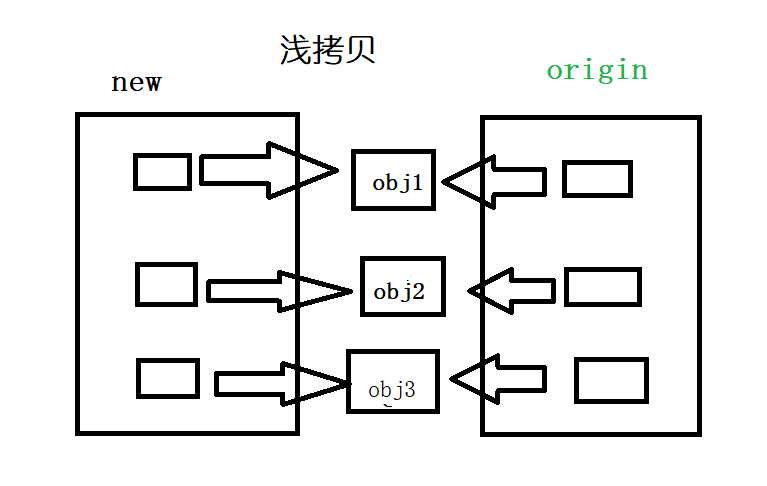
从上图不难看出,浅拷贝后,新复合对象包含的对象(可变或者不可变)的 id 值和原有对象包含的对象的 id 值相同
看一下具体例子:
>>> import copy
>>> a=[1,2,[3,4]]
>>> b=copy.copy(a)
>>> id(b[0])==id(a[0])
True
>>> id(b[2])==id(a[2])
True
>>> id(b[2][0])==id(a[2][0])
True
现在让我们试着修改一下浅拷贝后的 b 的值,在修改前,可以先思考一下,如果修改 b[0] 可能会发生什么?
由于 b[0] = 1,很显然 1 属于不可变对象,那么根据对不可变变量修改的规则,则 b[0] 会绑定到新的变量上,而 a[0] 的由于没有修改,则保持不变,真的是这样吗?让我们验证一下
>>> b[0]=5
>>> b
[5, 2, [3, 4]]
>>> a
[1, 2, [3, 4]]
接下来我们要尝试修改一下 b[2],由于 b[2] 绑定的对象是 list,属于可变对象,按照上面说的可变对象修改的规则,则修改后的 b[2] 的 id 值保持不变,但是其 value 值会发生改变. 同样的让我们通过例子验证一下
>>> id(b[2])
4300618568
>>> b[2][0]=6
>>> id(b[2])
4300618568
>>> b
[5, 2, [6, 4]]
>>> a
[1, 2, [6, 4]]
由于 b[2] 和 a[2] 绑定同一个可变对象,很显然对 b[2] 的修改同样会映射到 a[2] 上
深拷贝
深拷贝构建一个复合对象,然后递归的将原有复合包含的对象的副本插入到新的复合对象中
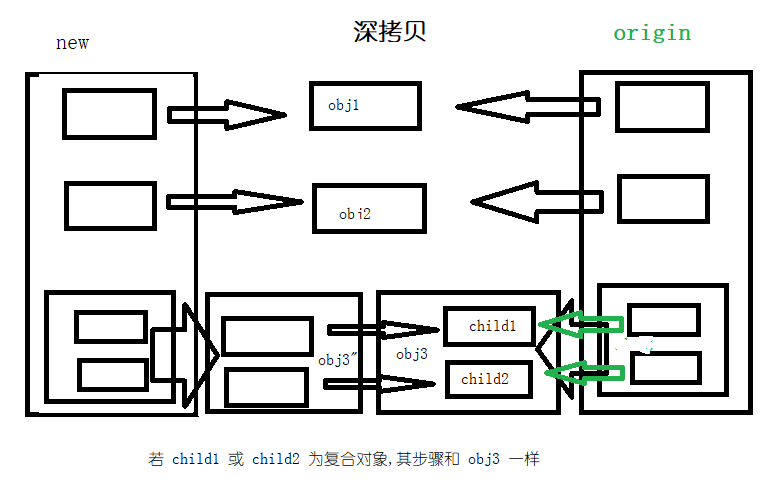
若上图所示,深拷贝后,新的复合对象包含的对象,若对象为不可变对象,则 id 值保持不变,若对象为可变对象,则 id 值发生改变
看一个例子:
>>> import copy
>>> a=[1,2,[3,4]]
>>> b=copy.deepcopy(a)
>>> id(b[0])==id(a[0])
True
>>> id(b[2])==id(a[0])
False
>>> id(b[2][0])==id(a[2][0])
True
接下来让我们修改一下变量 b,这里就不在修改不可变对象 b[0] 和 b[1] 了,因为结果很明显,对 a 不会产生任何影响,我们来修改 b[2],那么修改 b[2] 会对 a[2] 产生影响吗?很明显答案是不会,因为深拷贝就相当于克隆出了一个全新的个体,两者不再有任何关系
>>> b[2][0]=5
>>> b
[1, 2, [5, 4]]
>>> a
[1, 2, [3, 4]]
【Python】直接赋值,深拷贝和浅拷贝的更多相关文章
- **Python中的深拷贝和浅拷贝详解
Python中的深拷贝和浅拷贝详解 这篇文章主要介绍了Python中的深拷贝和浅拷贝详解,本文讲解了变量-对象-引用.可变对象-不可变对象.拷贝等内容. 要说清楚Python中的深浅拷贝,需要 ...
- python中的深拷贝与浅拷贝
深拷贝和浅拷贝 浅拷贝的时候,修改原来的对象,浅拷贝的对象不会发生改变. 1.对象的赋值 对象的赋值实际上是对象之间的引用:当创建一个对象,然后将这个对象赋值给另外一个变量的时候,python并没有拷 ...
- 浅谈python 复制(深拷贝,浅拷贝)
博客参考:点击这里 python中对象的复制以及浅拷贝,深拷贝是存在差异的,这儿我们主要以可变变量来演示,不可变变量则不存在赋值/拷贝上的问题(下文会有解释),具体差异如下文所示 1.赋值: a=[1 ...
- python中的深拷贝和浅拷贝
python的复制,深拷贝和浅拷贝的区别 在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用 一 ...
- 001 说说Python中的深拷贝和浅拷贝
在Python编程中忽略深拷贝和浅拷贝可能会造成未知的风险. 比如我们打算保存一份原始对象的副本作为上一状态的记录,此后修改原始对象数据时,若是副本对象的数据也发生改变,那么这就是一个严重的错误. 注 ...
- Python 对象的深拷贝与浅拷贝 -- (转)
本文内容是在<Python核心编程2>上看到的,感觉很有用便写出来,给大家参考参考! 浅拷贝 首先我们使用两种方式来拷贝对象,一种是切片,另外一种是工厂方法.然后使用id函数来看看它们的标 ...
- Python list的深拷贝和浅拷贝
深拷贝和浅拷贝 列表存储数据,列表拷贝就是数据备份 浅拷贝 优点:占用内存较少 缺点:修改深层数据,会影响原数据 深拷贝 优点:修改数据,互不影响 缺点:占用内存较大 ""&quo ...
- Python赋值语句与深拷贝、浅拷贝的区别
参考:http://stackoverflow.com/questions/17246693/what-exactly-is-the-difference-between-shallow-copy-d ...
- python中的深拷贝和浅拷贝理解
在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用.以下分两个思路来分别理解浅拷贝和深拷贝: 利用切 ...
随机推荐
- 解决Celery 在Windows中搭建和使用的版本
官网:http://docs.celeryproject.org/en/latest/faq.html#does-celery-support-windows 描述如下:表示Celery 4.0版本以 ...
- python实现批量文件重命名
本文实例为大家分享了python批量文件重命名的具体代码,供大家参考,具体内容如下 问题描述 最近遇到朋友求助,如何将大量文件名前面的某些字符删除. 即将图中文件前的编号删除. Python实现 用到 ...
- python模拟网站登陆-滑动验证码
普通滑动验证 以http://admin.emaotai.cn/login.aspx为例这类验证码只需要我们将滑块拖动指定位置,处理起来比较简单.拖动之前需要先将滚动条滚动到指定元素位置. impor ...
- iOS简历书写注意事项
1.个人信息模块 1)简历标题 2)姓名 性别 年龄 电话 邮箱 常驻地 学历 英语能力 工作年限 籍贯 专业 (突出优势) 注意:不要从招聘网站导出简历网站 2.求职意向 1)职位 地点 薪资 ...
- (四)Maven项目工程目录约定
使用maven创建的工程我们称它为maven工程,maven工程具有一定的目录规范,如下: src/main/java 存放项目的.java文件 src/main/resources 存放项目资源文件 ...
- Python里的黄金库,学会了你的工资至少翻一倍
作者:[已重置]链接:https://zhuanlan.zhihu.com/p/26054228来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 阅读本文大概需要5分钟 ...
- 05.DRF-Django REST framework 简介
一.明确REST接口开发的核心任务 分析一下上节的案例,可以发现,在开发REST API接口时,视图中做的最主要有三件事: 将请求的数据(如JSON格式)转换为模型类对象 操作数据库 将模型类对象转换 ...
- linux环境下搭建Jenkins持续集成(Jenkins+git+shell+maven+tomact)
准备环境 jenkins.war包 ,jdk1.8 ,tomact , maven,git 1.Jenkins war包,下载地址https://jenkins.io/zh/download/ ...
- python 函数式编程 高阶函数 装饰器
# -*- coding:gb2312 -*- #coding=utf-8 # 高阶函数 import math def is_sqr(x): y = int(math.sqrt(x)) return ...
- Windwos安装Redis
下载地址:https://github.com/MicrosoftArchive/redis 进入后点击release,下方可看到下载地址,下载mis文件,双击即可安装