SparkSQL和hive on Spark
SparkSQL简介
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,Shark应运而生,但又因为Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),2014年spark团队停止对Shark的开发,将所有资源放SparkSQL项目上
SparkSQL、Hive on Spark的关系
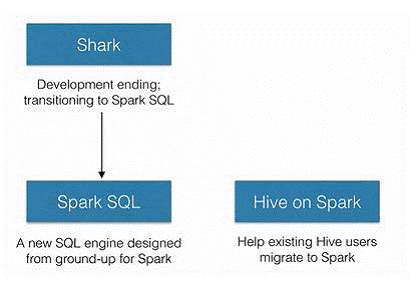
由上图可以看出,SparkSQL之所以要从Shark中孵化出来,初衷就是为了剥离Shark对于Hive的太多依赖。SparkSQL作为Spark生态中独立的一员继续发展,不在受限于Hive,只是兼容Hive;而Hive on Spark是Hive的发展计划,该计划将Spark作为Hive最底层的引擎之一,Hive不在受限于一个引擎(之前只支持map-reduce),可以采用map-reduce、Tez、Spark等计算引擎。
hive on Spark是有Cloudera发起,有Intel、MapR等公司共同参与的开源项目,其目的就是将Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上面进行计算。通过该项目,可以提高Hive查询的性能,同事为已经部署了Hive或者Spark的用户提供了更加灵活地选择,从而进一步提高Hive和Spark的普及率。
hive on Spark和SparkSQL的结构类似,只是SQL引擎不同,但是计算引擎都是spark
sparkSQL通过sqlcontext来进行使用,hive on spark通过hivecontext来使用。sqlcontext和hivecontext都是来自于同一个包,从这个层面上理解,其实hive on spark和sparkSQL并没有太大差别。
结构上来看,Hive on Spark和SparkSQL都是一个翻译曾,将SQL翻译成分布是可以执行的Spark程序。
SQLContext:spark处理结构化数据的入口,允许创建DataFrame以及sql查询。
HiveContext:Spark sql执行引擎,集成hive数据,读取在classpath的hive-site.xml配置文件配置hive。所以ye
SparkSQL组件和运行架构
1-SQLContext:Spark SQL提供SQLContext封装Spark中的所有关系型功能。可以用之前的示例中的现有SparkContext创建SQLContext。
2-DataFrame:DataFrame是一个分布式的,按照命名列的形式组织的数据集合。DataFrame基于R语言中的data frame概念,与关系型数据库中的数据库表类似。通过调用将DataFrame的内容作为行RDD(RDD of Rows)返回的rdd方法,可以将DataFrame转换成RDD。可以通过如下数据源创建DataFrame:已有的RDD、结构化数据文件、JSON数据集、Hive表、外部数据库。
了私语关系型数据库,SparkSQL中的SQL语句也是由Projection、Data source、Filter但部分组成,分别对应于sql查询过程中的Result、Data source和Operation;SQL语句是按照Operation-》Data Source -》Result的次序来描述的。如下所示:

下面对上图中展示的SparkSQL语句的执行顺序进行详细解释:
1-对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
Projection:简单说就是select选择的列的集合,参考:SQL Projection
2-将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3-一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4-计划执行(Execute),按Operation–>Data Source–>Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
SQLContext和HiveContext
当使用SparkSQL时,根据是否要使用Hive,有两个不同的入口。推荐使用入口HiveContext,HiveContext继承自SQLContext。它可以提供HiveQL以及其他依赖于Hive的功能的支持。更为基础的SQLContext则仅仅支持SparlSQL功能的一个子集,子集中去掉了需要依赖Hive的功能。这种分离主要视为那些可能会因为引入Hive的全部依赖而陷入依赖冲突的用户而设计的。因为使用HiveContext的时候不需要事先部署好Hive。如果要把一个Spark SQL链接到部署好的Hive上面,必须将hive-site.xml复制到Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,SparkSQL也可以运行,如果没有部署好Hive,但是还要使用HiveContext的话,那么SparkSQL将会在当前的工作目录中创建出自己的Hive元数据仓库,叫做metastore_db。,如果使用HiveQL中的CREATETABLE语句来创建表,那么这些表将会被放在默认的文件系统中的/user/hive/warehouse目录中,这里默认的文件系统视情况而定,如果配置了hdfs-site.xml那么就会存放在HDFS上面,否则就存放在本地文件系统中。
运行HiveContext的时候hive环境并不是必须,但是需要hive-site.xml配置文件。
SparkSQL和hive on Spark的更多相关文章
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- SparkSQL与Hive on Spark
SparkSQL与Hive on Spark的比较 简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapR ...
- Hive On Spark和SparkSQL
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案.Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL.这是Spark官方Da ...
- Spark SQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- 【Spark篇】---SparkSQL on Hive的配置和使用
一.前述 Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行. 二.具体配置 1.在Spark客户端配置Hive On Spark 在Spark客户端安装包下sp ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- Spark之 使用SparkSql操作Hive的Scala程序实现
依赖 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2 ...
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
随机推荐
- Docker-教你如何通过 Docker 快速搭建各种测试环境
今天给大家分享的主题是,如何通过 Docker 快速搭建各种测试环境,本文列举的,也是作者在工作中经常用到的,其中包括 MySQL.Redis.Elasticsearch.MongoDB 安装步骤,通 ...
- 十年老苹果(A1286)强升Catalina及Win10踩坑记
前言 手头有一台十年老苹果,MacBook Pro,A1286,连视网膜屏都没有,电池也早就衰减以后直接拆掉了(减重). 早些年用得还挺多,后来家里也弄了台式,用得逐渐少了,再后来时不时Windows ...
- day14 参数
目录 一.参数介绍 二.形参与实参的具体使用 2.1位置参数 2.2关键字参数 2.3关键字实参和位置实参混合使用时 2.4默认参数 2.5位置形参和默认形参混用 2.6 可变长度的参数(*与**用法 ...
- 数据可视化之分析篇(六)使用Power BI进行流失客户分析
https://zhuanlan.zhihu.com/p/73358029 为了提升销量,在不断吸引新客户的同时,还要防止老客户离你而去,但每一个顾客不可能永远是你的客户,不可避免的都会经历新客户.活 ...
- redis入门指南(三)—— 事务、过期时间、SORT命令、消息通知与管道
写在前面 学习<redis入门指南>笔记,结合实践,只记录重要,明确,属于新知的相关内容. 事务 1.redis中的事务由一组命令的集合组成,要么都执行,要么都不执行,同时redis的事务 ...
- MVC + EFCore 项目实战 - 数仓管理系统5 – 菜单配置及里程碑划分
上次课程我们完成了需求的梳理. 我们根据梳理的需求把菜单配好,另外我们把项目里程碑也配置在系统中,开发和管理都在系统中,形成无文档化管理. 一.菜单配置 根据我们的归纳图,我们先将菜单配置好. 我们遵 ...
- Ethical Hacking - POST EXPLOITATION(1)
METERPRETER BASICS >help - shows help >background - backgrounds current session >sessions - ...
- python监控服务器应用日志,推送钉钉机器人,实时关注日志异常
生产环境多台服务器上部署了多个应用,日志出现报错时,无法及时反馈到开发人员.部署一个大型的运维监控应用,不但耗资源,而且配置也不简单. 简简单单写个python脚本来监控服务器日志就简单多了,废话不多 ...
- javascript : 对象取值练习
let obj = { "qqq":0, "www":0, "eee":0, "rrr":1, "ttt&qu ...
- STL源码剖析:算法
启 算法,问题之解法也 算法好坏的衡量标准:时间和空间,单位是对数.一次.二次.三次等 算法中处理的数据,输入方式都是左闭又开,类型就迭代器, 如:[first, last) STL中提供了很多算法, ...