mysql 单表下的字段操作_查询
查询的规律
查询语句限定条件越多,查询范围越小;
1.整个表
Select * From 库名.表名
2.整个表的某字段内
Select id From 库名.表名
3.整个表某字段的范围内
Select * From 库名.表名 Where id<50;
4.整个表某字段的范围内在限定条目数
Select * From 库名.表名 Where id<50 Limit 0,10;
总结:
范围的大小比较关系如下
1.>2.>3.>4.
Select指定表和字段查询范围
指定整个表
*是通配符;
Select * From 库名.表名
指定某几个字段
Select id,name From 库名.表名
Where指定字段查询范围
Where 后面可以添加很多查询条件,常用的查询条件如下,在现实中具体使用哪种看应用场景;
运用关系运算符确定范围查询
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
Example:
Select * From 库名.表名 Where id<50;
In 包含判断查询
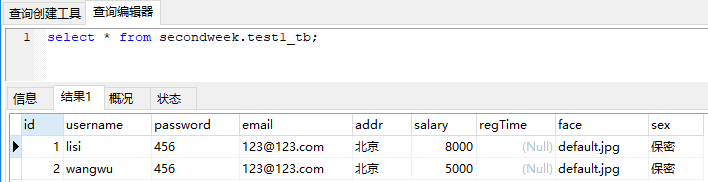
select * from secondweek.test1_tb where id in(1,2);
id not in(1,2)不查括号里面包含的
select * from secondweek.test1_tb where id not in(1,2);
字符串包含 example:
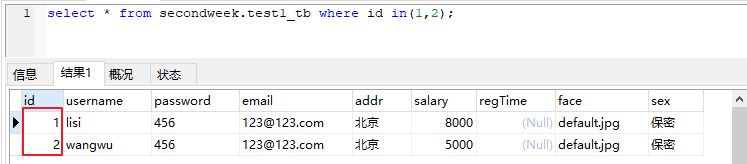
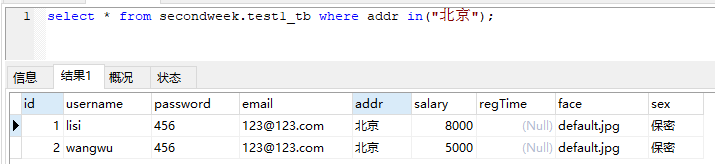
select * from secondweek.test1_tb where addr in("北京");
Between X and Y符合连续数值范围内查询
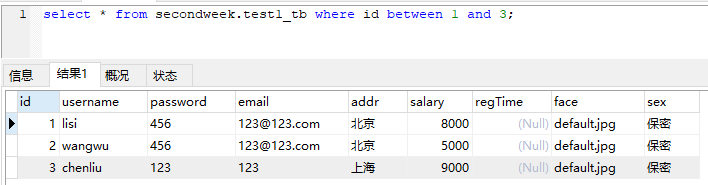
select * from secondweek.test1_tb where id between 1 and 3;
Is NULL 空值判断查询
Mysql列中的空值(NULL)不同于0,也不同于空字符串;
可以使用 Not 关键字;
select * from secondweek.test1_tb where regTime is Null;
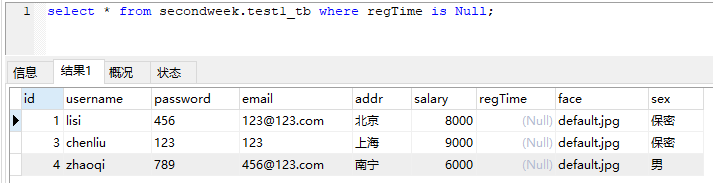
Distinct 去重查询
假设有多个重复,那么他留存唯一的标准是什么?留第一条;
使用distinct命令时需要放在查询条件的开头;
原本表结构:
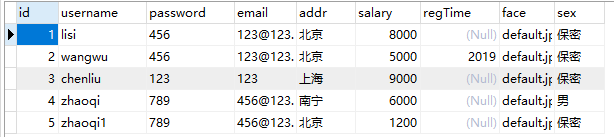
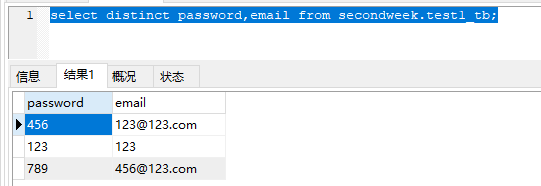
select distinct password,email from secondweek.test1_tb;
去重后的表结构:
如果是使用了多个列字段,就根据一行与一行来比较,不是单个;如果只是单列去重,那么和Group By 字段名;没啥区别;
Group By 单列去重
单字段去重效果好,因为Group By sex, sex列就作为分组标准,男为一组,女为一组,结果就会只显示男、女两组。可以作为单列去重使用;
原表:
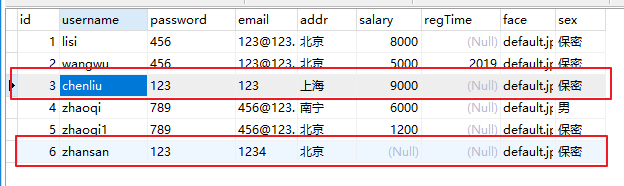
去重后:
select password,email from secondweek.test1_tb Group By password;
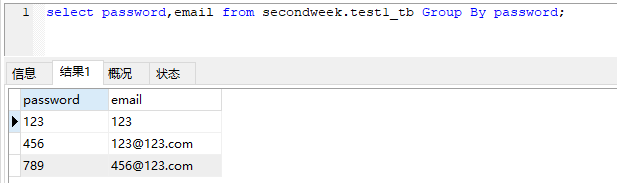
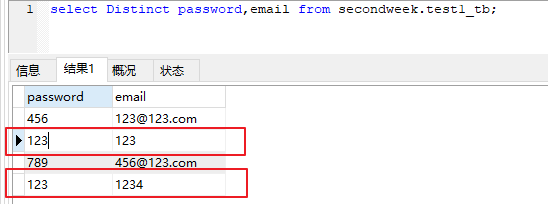
Distinct 去重后:
select Distinct password,email from secondweek.test1_tb;
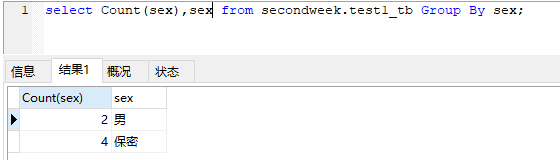
Group By结合聚合统计函数\Having查询
Group By 字段; 这列字段就会被作为分组,不能有重复;分组之后可以求字段中最大、最小、平均值、每组数量...
example:
select Count(sex),sex from secondweek.test1_tb Group By sex;
结合Having 关键字:
Having 和 Where类似都是对查询结果进行过滤用;
区别在于,Having后面可以跟着聚合函数,而Where不能;
Having一般都和Group By一起使用,对分组后的结果进行过滤;
select Avg(salary),sex from secondweek.test1_tb Group By sex having Avg(salary)>=5900;

Like 模糊查询
模糊查询支持使用通配符;常用通配符有
*、%、_、...
% example:
% 百分号通配符可以匹配任意长度的字符,包括空字符串;
# 知道固定头
select * from secondweek.test1_tb where username Like "zhao%";
# 知道固定尾
select * from secondweek.test1_tb where username Like "%qi";

模糊搜索example:
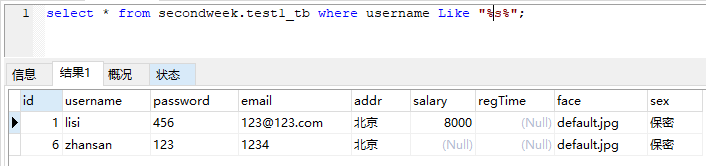
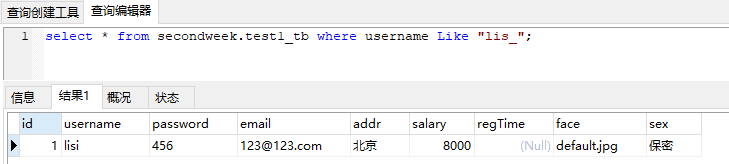
_ 单个字符匹配example:
_下划线通配符只能匹配单个字符,要想匹配多个,就得用多个下划线;
select * from secondweek.test1_tb where username Like "lis_";
And 并列多条件查询
Select * From 库名.表名 Where id<50 and sex=0;
Or 或条件查询
Select * From 库名.表名 Where name="lisi" or sex=0;
Limit 限定查询结果的数量
Select * From 库名.表名 Where id<50 Limit M[,N];
# M 是偏移变量,默认从0开始,如果指定查询结果为 lisi,wangwu,zhaoliu,chenqi, lisi是0,如果M=2,就从zhouliu开始;
# N 是记录数,表示显示出几条数据;
Select * From 库名.表名 Where id<50 Limit 0,10;

复合条件查询
根据应用场景,将上述查询条件语句进行嵌套、并列一起使用,叫做复合条件查询;
# 聚合(统计)函数
> 列举一些常用聚合函数;一般和Order by 结合使用;
- AVG() --- 求某一列平均值
- COUNT() --- 统计总行数
- SUM() --- 计算列总和
- MIN() --- 求某一列的最小值
- MAX() --- 求某一列的最大值
# Order By对查询结果排序
> 先确定以某列为基准进行排列;
可以使用Order By将某列定为基准,然后排序;
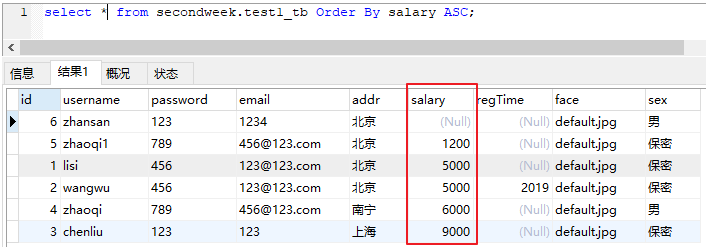
ASC 升序
select * from secondweek.test1_tb Order By salary ASC;
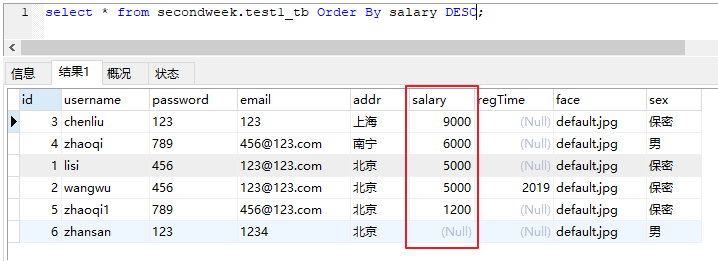
DESC 降序
select * from secondweek.test1_tb Order By salary DESC;
# 查询时使用别名
> as 可以省略;
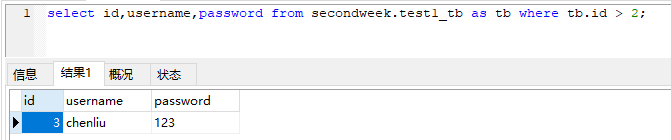
为表取别名
查询时使用表名的别名,可以省略写全称的麻烦,在多表操作的时候需要写多个表名时,有点应用场景;
select id,username,password from secondweek.test1_tb as tb where tb.id > 2;
# or
select id,username,password from secondweek.test1_tb tb where tb.id > 2;
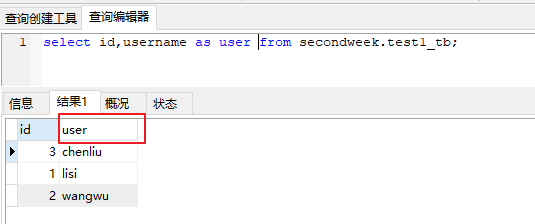
为字段取别名
原本查询出来的列名都是创建时定义好的,查询时可以使用别名展示出来;
表原来结构:

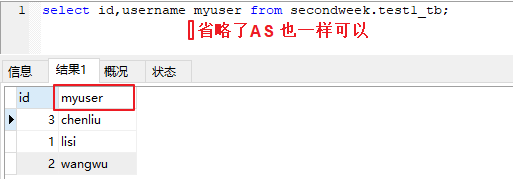
select id,username myuaer,password as ps from secondweek.test1_tb;
修改成别名展示:
mysql 单表下的字段操作_查询的更多相关文章
- mysql 单表下的字段操作
如下只介绍单表的添加.更新.删除.查询表结构操作,查询数据操作范围太大用单独的篇幅来讲解: 查看表结构 desc test_tb; Insert 插入数据 插入 = 添加 为表中指定的字段插入数据 C ...
- MySQL单表多字段模糊查询
今天工作时遇到一个功能问题:就是输入关键字搜索的字段不只一个字段,比如 我输入: 超天才 ,需要检索出 包含这个关键字的 name . company.job等多个字段.在网上查询了一会就找到了答案. ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- MySQL单表数据不超过500万:是经验数值,还是黄金铁律?
今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢? 曾经在中国互联网技术圈广为流传着这么一个 ...
- MySQL单表最大记录数不能超过多少?
MySQL单表最大记录数不能超过多少? 很多人困惑这个问题.其实,MySQL本身并没有对单表最大记录数进行限制,这个数值取决于你的操作系统对单个文件的限制本身. 从性能角度来讲,MySQL单表数据不要 ...
- MySQL单表数据不要超过500万行:是经验数值,还是黄金铁律?
本文阅读时间大约3分钟. 梁桂钊 | 作者 今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢 ...
- MySQL单表最大限制
想把一个项目的数据库导出来,然后倒入到自己熟悉的MySQL数据库中进行运行和调试.导出来后,发现sql文件整整有12G多大,忽然想起来,MySQL好像有个叫做容量限制的神奇特性,但是忘了上限是多少了, ...
随机推荐
- 2020 CCPC Wannafly Winter Camp Day1 C. 染色图
2020 CCPC Wannafly Winter Camp Day1 C. 染色图 定义一张无向图 G=⟨V,E⟩ 是 k 可染色的当且仅当存在函数 f:V↦{1,2,⋯,k} 满足对于 G 中的任 ...
- 2014-2015 ACM-ICPC, NEERC, Southern Subregional Contest 题解(PART)(9/13)
$$2014-2015\ ACM-ICPC,\ NEERC,\ Southern\ Subregional\ Contest$$ A Nasta Rabbara B Colored Blankets ...
- 2015-2016 ACM-ICPC, NEERC, Northern Subregional Contest (9/12)
$$2015-2016\ ACM-ICPC,\ NEERC,\ Northern\ Subregional\ Contest$$ \(A.Alex\ Origami\ Squares\) 签到 //# ...
- 【poj 1961】Period(字符串--KMP 模版题)
题意:给你一个字符串,求这个字符串到第 i 个字符为止的重复子串的个数. 解法:判断重复子串的语句很重要!!if (p && i%(i-p)==0) printf("%d % ...
- 【noi 2.6_9281】技能树(DP)
题意:要求二叉树中每个节点的子节点数为0或2,求有N个节点高度为M的不同的二叉树有多少个(输出 mod 9901 后的结果). 解法:f[i][j]表示高度为i的有j个节点的二叉树个数.同上题一样,把 ...
- P1387 最大正方形 && P1736 创意吃鱼法(DP)
题目描述 在一个n*m的只包含0和1的矩阵里找出一个不包含0的最大正方形,输出边长. 输入输出格式 输入格式: 输入文件第一行为两个整数n,m(1<=n,m<=100),接下来n行,每行m ...
- Pollard_rho算法进行质因素分解
Pollard_rho算法进行质因素分解要依赖于Miller_Rabbin算法判断大素数,没有学过的可以看一下,也可以当成模板来用 讲一下Pollard_rho算法思想: 求n的质因子的基本过程是,先 ...
- CF1475-D. Cleaning the Phone
CF1475-D. Cleaning the Phone 题意: 手机上有很多应用非常占用内存,你要清理内存.对于每个应用\(i\)有以下描述:应用\(i\)占用了\(a_i\)的空间,它的方便度为\ ...
- Python append() 与深拷贝、浅拷贝
在leetcode77中,发现list.append的结果不对.原代码: class Solution: def combine(self, n: int, k: int) -> List[Li ...
- appveyor build failed --
在 https://www.cnblogs.com/lqerio/p/11117498.html 使用了appveyor 进行 hexo 博客的版本控制持续集成. 今天push 到 github的 r ...