Hive 建模
date: 2020-05-24 17:55:00
updated: 2020-06-15 11:19:00
Hive 建模
1. 存储格式
- textFile
- sequenceFile:一种Hadoop API提供的二进制文件,使用方便、可分割、可压缩。将数据以<key,value>的形式序列化到文件中。序列化和反序列化使用Hadoop 的标准的Writable 接口实现。key为空,用value 存放实际的值, 这样可以避免map 阶段的排序过程。
- rcFile:一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。但是不好用。
- orc:ecFile升级版。常用于Hive、Presto。
- parquet:Parquet和ORC都以列的形式存储数据。面向列的数据存储针对读取繁重的分析工作负载进行了优化。常用于Impala、Drill、Spark、Arrow。
- avro:基于行的格式存储数据。基于行的数据库最适合于大量写入的事务性工作负载。常用于Kafka、Druid。
数据压缩比例上ORC最优,相比textfile节省了50倍磁盘空间,parquet压缩性能也较好
SQL查询速度而言,ORC与parquet性能较好,远超其余存储格式
2. 表的类型
- 全量表:保存用户所有的数据(包括新增与历史数据)
- 增量表:只保留当前新增的数据
- 快照表:按日分区,记录截止数据日期的全量数据
- 切片表:切片表根据基础表,往往只反映某一个维度的相应数据。其表结构与基础表结构相同,但数据往往只有某一维度,或者某一个事实条件的数据
- 拉链表:记录一个事物从开始,一直到当前状态的所有变化的信息
3. 数据仓库、数据建模
3.1 数据仓库目标
- 访问性能:能够快速查询所需的数据,减少数据I/O。
- 数据成本:减少不必要的数据冗余,实现计算结果数据复用,降低大数据系统中的存储成本和计算成本。
- 使用效率:改善用户应用体验,提高使用数据的效率。
- 数据质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的、一致的数据访问平台。
比如hive的优点:
- 容量大 hdfs
- 运算能力强 mapreduce
3.2 建模方式
3.2.1 ER实体模型
实体Entity(矩形)、属性Property(椭圆形)、关系Relationship(菱形)
3.2.2 维度建模
维度建模源自数据集市,主要面向分析场景。Ralph Kimball推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表划分为事实表、维度表两种类型
- 事实表
在ER模型中抽象出了有实体、关系、属性三种类别,在现实世界中,每一个操作型事件,基本都是发生在实体之间的,伴随着这种操作事件的发生,会产生可度量的值,而这个过程就产生了一个事实表,存储了每一个可度量的事件。通常是数值类型,且记录数会不断增加,表规模迅速增长。
业务里每一个提交的表单都可以作为一个事实表(一次业务处理流程),表单相关的一些信息作为维度表
- 维度表
维度表一般为单一主键,在ER模型中,实体为客观存在的事务,会带有自己的描述性属性,属性一般为文本性、描述性的,这些描述被称为维度。
比如商品,单一主键:商品ID,属性包括产地、颜色、材质、尺寸、单价等,但并非属性一定是文本,比如单价、尺寸,均为数值型描述性的,日常主要的维度抽象包括:时间维度表、地理区域维度表等。
维度建模通常又分为星型模型和雪花模型。
星型模型:

可以看出,星形模式的维度建模由一个事实表和一组维表成,且具有以下特点:
a. 维表只和事实表关联,维表之间没有关联;
b. 每个维表的主码为单列,且该主码放置在事实表中,作为两边连接的外码;
c. 以事实表为核心,维表围绕核心呈星形分布;
雪花模型:
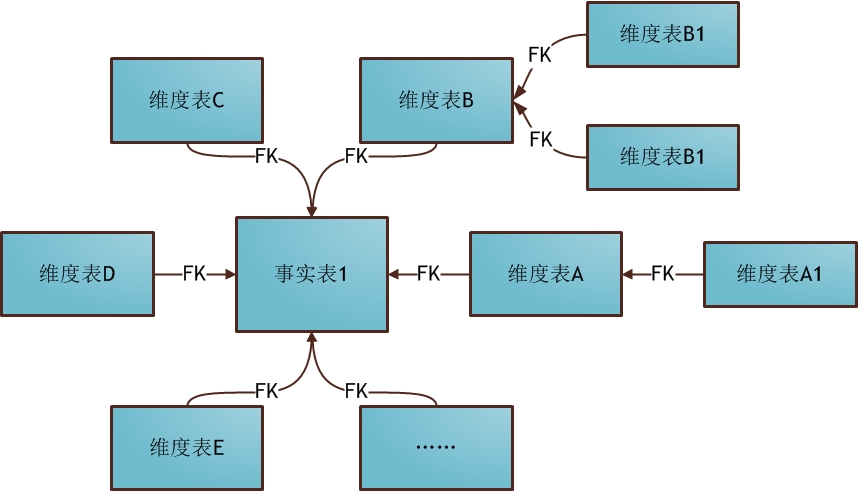
星型模型和雪花模型的主要区别在于对维度表的拆分,对于雪花模型,维度表的设计更加规范,一般符合3NF;而星型模型,一般采用降维的操作,利用冗余来避免模型过于复杂,提高易用性和分析效率。
然而这种模式在实际应用中很少见,因为这样做会导致开发难度增大
雪花、星型模型对比:
1、冗余:雪花模型符合业务逻辑设计,采用3NF设计,有效降低数据冗余;星型模型的维度表设计不符合3NF,反规范化,维度表之间不会直接相关,牺牲部分存储空间。
2、性能:雪花模型由于存在维度间的关联,采用3NF降低冗余,通常在使用过程中,需要连接更多的维度表,导致性能偏低;星型模型反三范式,采用降维的操作将维度整合,以存储空间为代价有效降低维度表连接数,性能较雪花模型高。
3、ETL:雪花模型符合业务ER模型设计原则,在ETL过程中相对简单,但是由于附属模型的限制,ETL任务并行化较低;星型模型在设计维度表时反范式设计,所以在ETL过程中整合业务数据到维度表有一定难度,但由于避免附属维度,可并行化处理。
大数据和传统关系型数据库的计算框架不一样,例如对比mapreduce和oracle,在mapreduce里面,每多一个表的关联,就多一个job。mapreduce的每个任务进来,要申请资源,分配容器,各节点通信等。有可能YARN调度时长大于任务运行时间,例如调度需要5秒才能申请到资源,而表之间的join只需要2秒。hive优化里面,要尽可能减少job任务数,也就是减少表之间的关联,可以用适当的冗余来避免低效的查询方式,这是和oracle等其他关系型数据库不同的地方。
星座模型(星行模型的拓展):

前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
3.2.3 Data Vault模型
3.2.4 Anchor
Hive 建模的更多相关文章
- Hive建模
Hive建模 1.介绍 Hive作为数据仓库,同关系型数据库开发过程类似,都需要先进行建模,所谓建模,就是对表之间指定关系方式.建模在hive中大致分为星型.雪花型和星座型.要对建模深入理解,首先需要 ...
- hive建模方法
转自:https://www.jianshu.com/p/8378b80e4b21 概述数据仓库这个概念是由 Bill Inmon 所提出的,其功能是将组织通过联机事务处理(OLTP)所积累的大量的资 ...
- 使用 Apache Atlas 进行数据治理
本文由 网易云发布. 作者:网易/刘勋(本篇文章仅限知乎内部分享,如需转载,请取得作者同意授权.) 面对海量且持续增加的各式各样的数据对象,你是否有信心知道哪些数据从哪里来以及它如何随时间而变化?采 ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- 使用 Hive 作为 ETL 或 ELT 工具
用来处理数据的 ETL 和 ELT 工具的概述 数据集成和数据管理技术已存在很长一段时间.提取.转换和加载(ETL)数据的工具已经改变了传统的数据库和数据仓库.现在,内存中转换 ETL 工具使得提取. ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 大数据和Hadoop时代的维度建模和Kimball数据集市
小结: 1. Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据.如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪.但是从内部机制看,数据库是以类似的机制工作,在一 ...
- hive拉链表
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成:先分享一下拉链表的用途.什么是拉链表.通过一些小的使用场景来对拉链表做 ...
- [转]Hive开发经验问答式总结
本文转载自:http://www.crazyant.net/1625.html 本文是自己开发Hive经验的总结,希望对大家有所帮助,有问题请留言交流. Hive开发经验思维导图 Hive开发经验总结 ...
随机推荐
- QQ自定义DIY动态名片教程
太极下载地址 :https://ww.lanzous.com/icajtgb 自定义DIY名片模块下载地址: https://ww.lanzous.com/id0965i 第一步,先下载好以上两个链接 ...
- API测试-接口测试基础(1)
由于自己想学习API方面的测试,但是市面上搜不到相关的图书可以系统学习,网上的内容又零零散散,适合有点API开发基础的人去搜索.为了方面新手学习API测试,现在整理了他人的宝贵经验和自己的学习心得,尽 ...
- 阅读源码的利器——Intellij-IDEA-Replace-in-Path-使用技巧
前言 讲讲宇宙排名第二的开发工具-–IDEA的使用技巧. 搜索/替换 技巧 阅读源码的利器 1.Match case: 如果勾选该按钮,搜索时将区分大小写字母. 2.Preserve case ...
- jfinal3连接sqlserver2012 使用generator生成model 将smallint默认为string
修改MetaBuilder的buildColumnMetas方法增加对smallint的判断
- idea模拟前端向后台请求数据输出响应结果
tools-httpClient-Test restful web service 通过上述步骤之后出现如下图 1 表示通过哪种方式请求:2 请求数据的地址头部:3 请求数据的除了头部之后的地址:4, ...
- JDK1.8新特性之(二)--方法引用
在上一篇文章中我们介绍了JDK1.8的新特性有以下几项. 1.Lambda表达式 2.方法引用 3.函数式接口 4.默认方法 5.Stream 6.Optional类 7.Nashorm javasc ...
- Python数据结构与算法之图的最短路径(Dijkstra算法)完整实例
本文实例讲述了Python数据结构与算法之图的最短路径(Dijkstra算法).分享给大家供大家参考,具体如下: # coding:utf-8 # Dijkstra算法--通过边实现松弛 # 指定一个 ...
- visual studio 2015 安装MSDN全称Microsoft Developer Network 安装离线的MSDN
MSDN: 微软向开发人员提供的一套帮助系统,其中包含大量的开发文档,技术文章和示例代码. 这里介绍了vs2015 装离线的MSDN(说明一点是,如果不行,说明你的文件有缺陷,没安装好,之前我用vs2 ...
- HarmonyOS 润和 HiSpark开发套件 免费领!
让人期盼已久的HarmonyOS 2.0终于在9月10日正式上线啦! 这是一件让众多开发者关注的大事件! 相信不少开发者都已经迫不及待的想上手实操了, 为了满足大家的好奇心, 也希望能有更多开发者了解 ...
- 为了省钱,我用1天时间把PHP学了!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 你在通往架构师的路上吗? 程序员这个行业就像是在不断的打怪升级,突破每一阶段的瓶颈期 ...