服务质量分析:腾讯会议&腾讯云Elasticsearch玩出了怎样的新操作?
导语 | 腾讯会议于2019年12月底上线,两个月内日活突破1000万,被广泛应用于疫情防控会议、远程办公、师生远程授课等场景,为疫情期间的复工复产提供了重要的远程沟通工具。上线100天内,腾讯会议快速迭代20个版本,满足不断增长的用户需求,多次登顶APP STROE中国区免费榜总榜No.1。
极速增长的会议需求,让腾讯会议服务质量分析系统经受着巨大的考验。为了向全网用户提供高效稳定的服务,以及对重要的大型会议进行保障护航。在充分讨论调研了大量方案后,腾讯会议服务质量分析团队与腾讯云Elasticsearch(下文简称“ES”)团队展开合作,积极探索云端服务质量数据分析引擎架构的更多可能。
一、数据极速增长,业务稳定面临挑战
伴随爆发增长的用户需求,腾讯会议的日活也在不断地刷新着历史记录。
从1月29日起,为了应对疫情下远程办公的需求,腾讯会议每天都在进行资源扩容,日均扩容云主机接近1.5万台,8天总共扩容超过10万台云主机,共涉及超百万核的计算资源投入。
在会议中,偶尔存在会议实时音视频卡顿、音视频不同步等会议质量问题,造成上述问题的可能因素比较多,当前运行的网络有丢包或连接不稳定的情况就是其中一种。
为了帮助运营团队快速精准地定位分析问题,需要大量运行时的会议质量数据支撑,如网络相关的入网类型、码率、丢包率、网络切换、ip切换等数据,以及客户端相关的CPU使用率、内存使用率、操作系统版本、产品版本等数据信息。
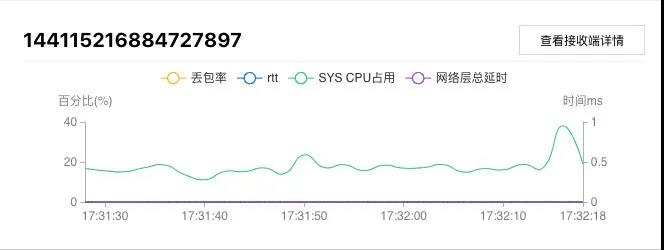
因会议是一个多用户参与交互的过程,定位问题不仅需要涉及到单个用户的情况,也要从房间的维度洞察各个用户之间的联系。通过腾讯会议客户端实时上报的会议质量信息,运营团队可以快速地对单用户、单房间的视频会议质量情况有直观的了解,为分析问题提供了数据支撑。
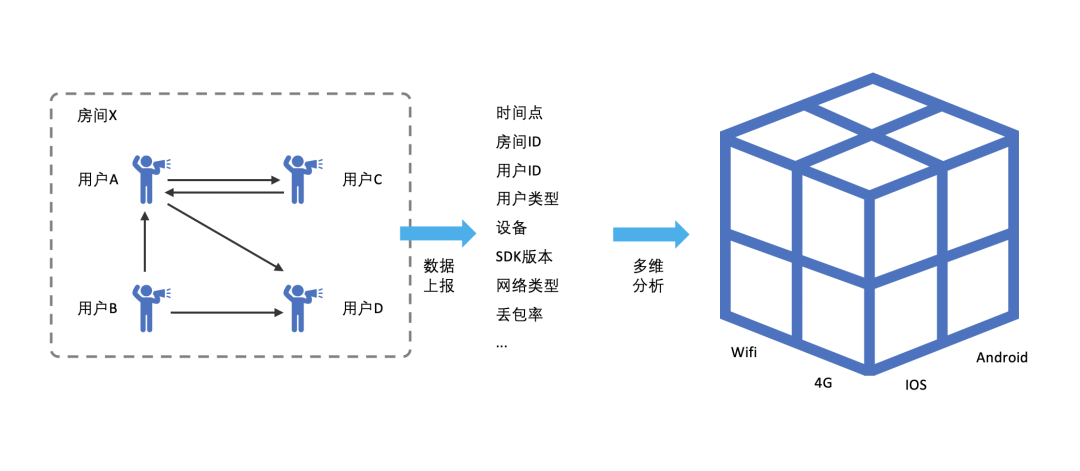
除了数据的实时上报,另一方面,借助多维分析,我们还可以在实时数据中挖掘出异常情况。如某个地区大面的卡顿,某个版本出现特定的问题等。通过dashboard或数据报表的形式,帮助运营团队及时掌控全局情况,快速发现潜在问题。
快速增长的用户数以及不断刷新纪录的同时在线房间数,让腾讯会议服务质量分析系统经受高压力,给运营团队及时排查用户问题带来了巨大的挑战。深究根本原因,是因为服务质量分析系统在如此高压力、高吞吐的场景下,写入性能严重不足导致。由于系统最关键的部分,是一个基于lucene自研的搜索引擎,扩容能力比较差,依赖于研发团队针对业务的优化。在数据量暴涨的背景下,不能进行快速扩容以满足需求。
二、选型ES及技术考量
为了保证全网腾讯会议用户都能高效稳定地进行会议沟通,保证运营团队能对用户会议中的卡顿等问题及时进行排查,以及对重要的大型会议进行保障护航。在充分讨论调研了大量方案后,腾讯会议服务质量分析团队决定从原来的自研服务质量数据分析系统,紧急迁移至使用腾讯云ES作为数据分析引擎的架构上。
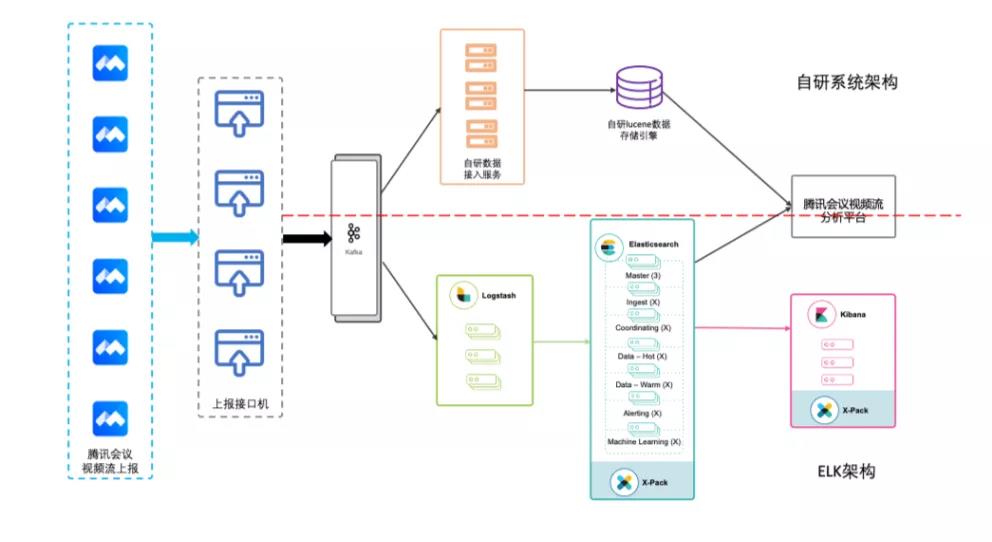
新老架构对比图
在进行架构方案选型的过程中,主要从以下几个方面进行了考虑:
1. 高性能
腾讯会议服务质量数据上报至ES的流量,峰值高达1000+w/s。在如此高吞吐的极限写入场景下,能持续稳定地提供数据读写服务,确实是一个挑战。在腾讯内部,也存在着类似腾讯会议这样的大批量、大吞吐写入场景,在使用过程中,业务部门经常会发现写入性能不高,且CPU使用率不稳定的问题,资源利用率严重不足。
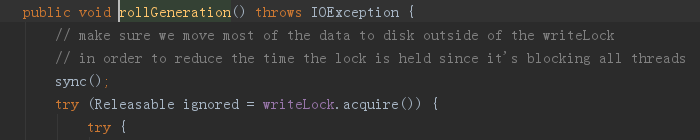
腾讯云ES内核团队对类似的高压力写入场景进行了追踪及分析,并在同样的场景下进行了多个方案的压力测试,发现ES单节点的压力写入测试与lucene基准的写压力测试有较大的差距。通过对调用火焰图进行分析并对比测试translog的一些调优参数,最终定位发现translog文件的rollGeneration操作与flush操作有互斥,两个操作互相频繁的加锁干扰,一次rollGeneration操作的平均耗时达到了570ms,在高压力写入场景下,频繁的rollGeneration会严重影响写入性能。
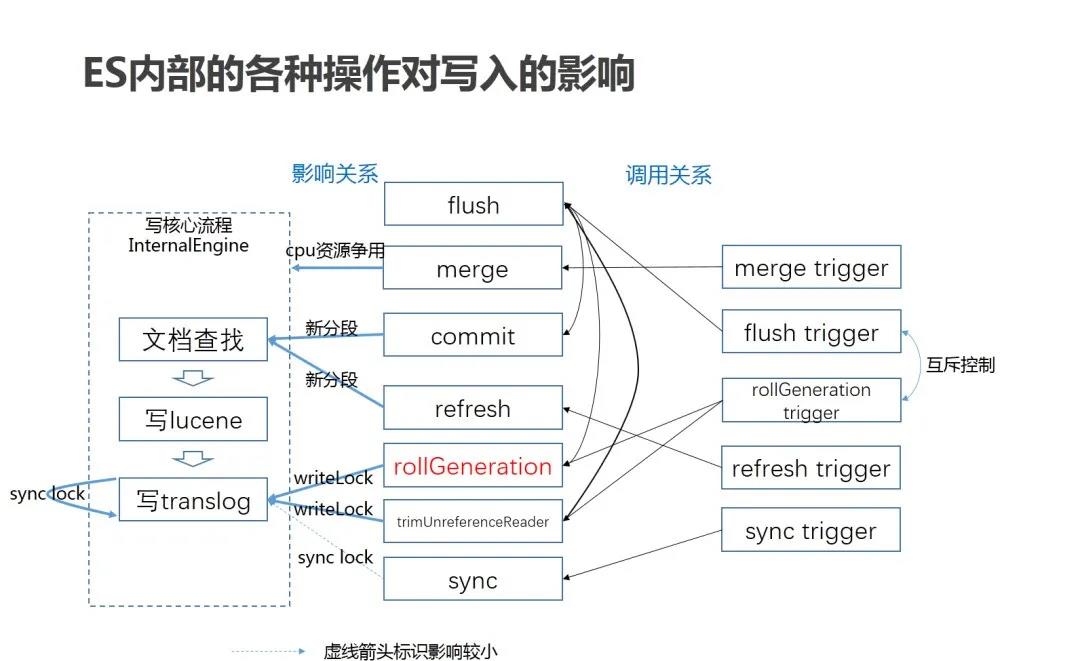
在与社区进行了大量的讨论及压测之后,最终确定了优化方案:采用rollGeneration的过程中,在关闭原translog文件之前,先执行一次flush,巧妙地避免了操作的互斥。这个方案对流程的改造最轻量优雅,且优化后的写入性能提高了20%以上。这部分优化的代码经腾讯内部的业务验证后,最终整理提交回馈给了社区。由于这个优化在ES写入的所有场景下均适用,且对性能的提升非常显著,Elastic的创始人对该PR高度赞扬,并给腾讯云总裁发来了公开感谢信。
腾讯云ES在社区开源的内核之上,根据云上的内外部业务的场景案例积累,做了大量的内核优化。除了上面介绍的translog的优化,还有带“_id”的写入操作剪枝优化、查询计划优化等等,满足了客户在性能方面的需要,并积极将一些通用的优化提交至社区,截至目前为止,腾讯云提交的pr约有50+被合并到了主干。
2.扩容能力
在疫情期间,继续沿用原有的架构很难满足快速扩容的需求,导致服务质量数据上报写入慢,数据大量堆积在队列中。腾讯云ES有着完善的分布式设计,单个集群支持扩容至数百甚至上千个节点。有可靠完备的选主算法逻辑以及sharding路由策略做保障。数据分片支持数据冗余,防止由于硬件故障导致的数据丢失,并提升集群的读性能。同时,数据可以按索引维度设置数据分片及副本数目,可以根据业务特点更灵活地设置合理的数值,降低了数据存储的成本。
腾讯云ES依托于腾讯云CVM进行构建,资源池充足,仅在疫情刚开始的一个月内就扩容了3W核,集群弹性伸缩的便利性得到了验证。扩容节点数目及变更节点配置等均为自动化功能,支持控制台及API一键操作,扩容过程平滑,不影响业务读写。
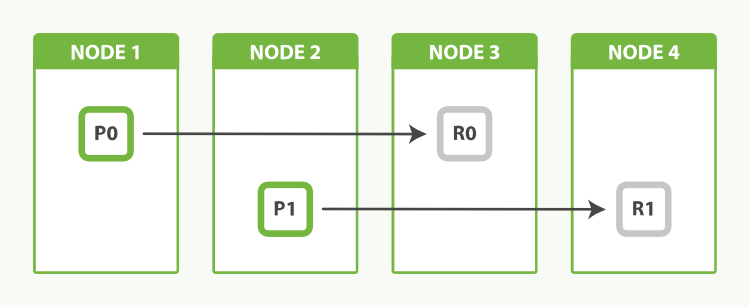
在集群扩容的场景中,相信很多业务都遇到过使用ES进行扩容后,大量新写入数据有读写热点,都堆积到新加入的节点上,导致节点被打挂,影响整个集群的写入性能。随着数据的增长,腾讯会议业务也扩容至千级节点的规模,那么上面的问题在腾讯云ES中是如何解决的呢?
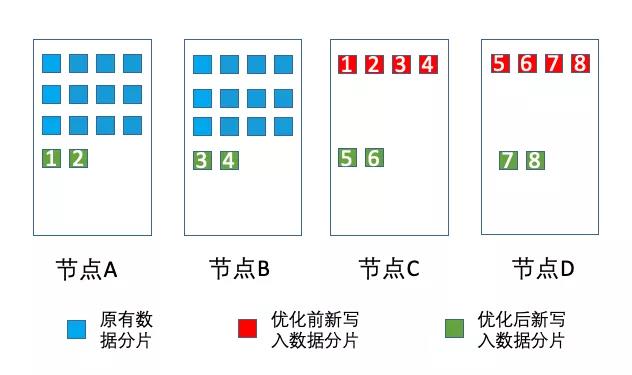
社区开源版本的ES,在shard分配的时候,会优先考虑各个节点上已有的shard数量,目的是尽量保持各个节点的shard和数据的均衡。当集群数据在各节点之间已经处于balance状态时,这时候增加新节点。由于新节点上面的shard数最少,就会造成上面的问题,新写入的数据都分配在新的节点上,造成新的节点压力过高而宕机。
为了帮助客户解决上述问题,腾讯云ES内核团队在原有allocationDecider责任链基础上,开发了一个新的decider分配算法,将一个index的所有分片,尽量平均地分配在各个节点上,使得新写入数据的读写流量被均匀分担,避免了新写入数据的访问热点。
3. 稳定性
腾讯会议服务质量分析系统,从2月份进行ES架构的方案切换开始,写入吞吐从5w/s不断攀升,现已达到100w+/s。业务的突发增长有时候来的很突然,并不能在前期做有效的评估。社区中的很多用户也遇到过类似的问题,由于没有预估到业务突发的增长,并且在业务层没有做好服务降级等机制,导致突发的写入查询流量打崩了整个集群,使ES服务甚至整个业务长时间不可用。那么,在类似腾讯会议这样的场景中,是怎样解决ES突增写入查询流量的问题的呢?
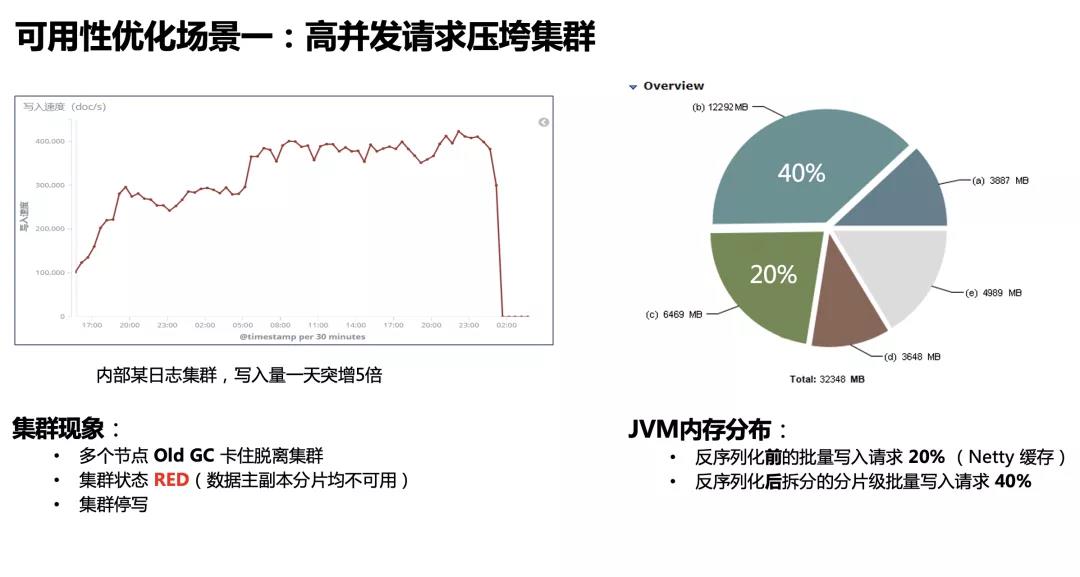
例如早期我们内部一个日志集群,写入量一天突增 5 倍,集群多个节点 Old GC 卡住脱离集群,集群 RED,写入停止,这个痛点确实有点痛。我们对挂掉的节点做了内存分析,发现大部分内存是被反序列化前后的写入请求占用。我们来看看这些写入请求是堆积在什么位置。
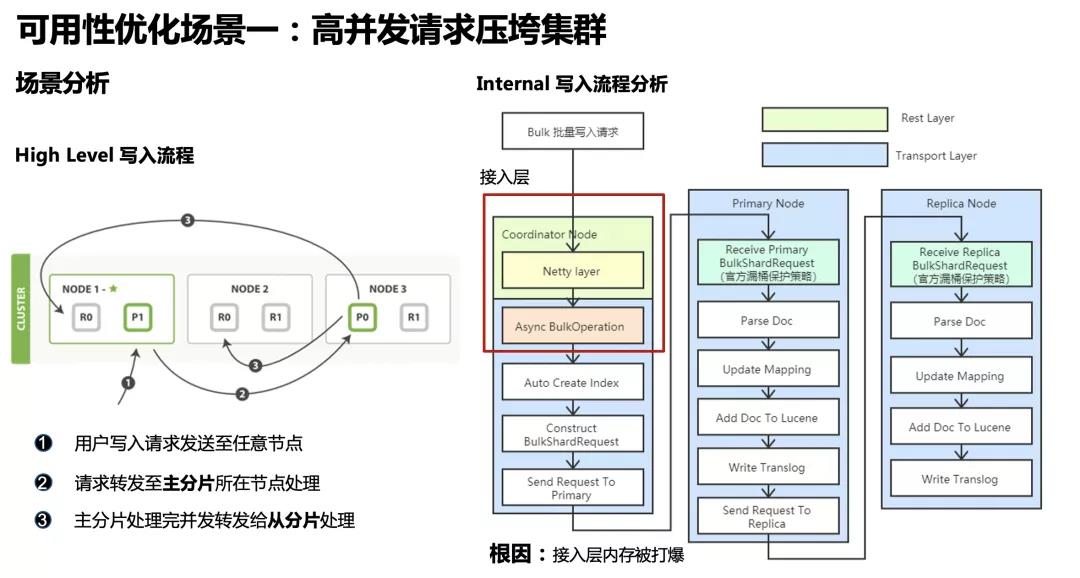
ES high level 的写入流程,用户的写入请求先到达其中一个数据节点,我们称之为数据节点。然后由该协调节点将请求转发给主分片所在节点进行写入,主分片写入完毕再由主分片转发给从分片写入,最后返回给客户端写入结果。右边是更细节的写入流程,而我们从堆栈中看到的写入请求堆积的位置就是在红色框中的接入层,节点挂掉的根因是协调节点的接入层内存被打爆。
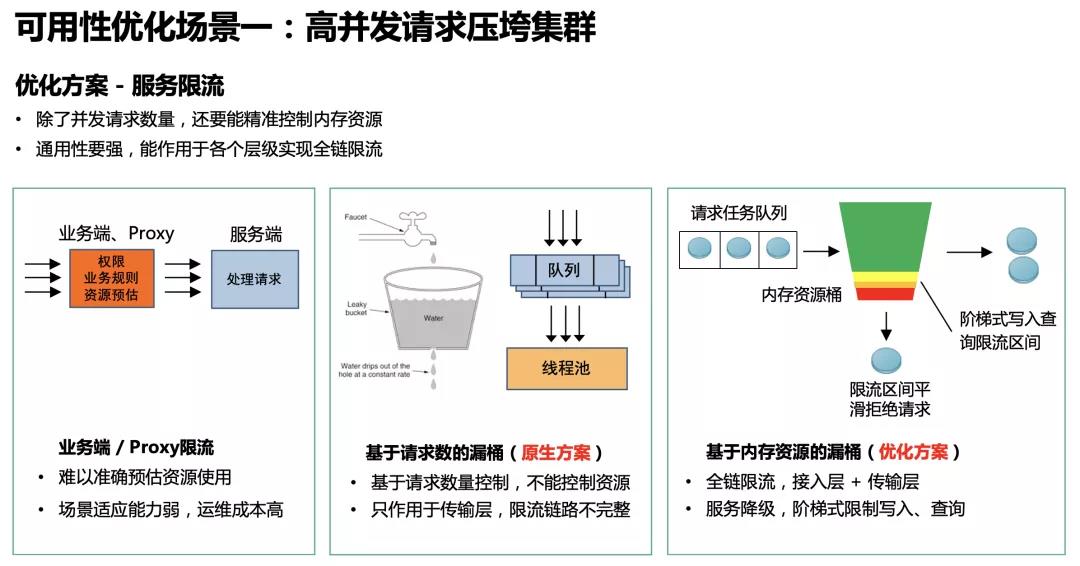
针对这种高并发场景,我们的优化方案是服务限流。除了要能控制并发请求数量,还要能精准地控制内存资源,因为内存资源不足是主要的矛盾。另外通用性要强,能作用于各个层级实现全链限流。
在很多数据库使用场景,会采用从业务端或者独立的 proxy 层配置相关的业务规则的限流方案,通过资源预估等方式进行限流。这种方式适应能力弱,运维成本高,而且业务端很难准确预估资源消耗。
ES原生版本本身有限流策略,是基于请求数的漏桶策略,通过队列加线程池的方式实现。线程池大小决定了处理并发度,处理不完放到队列,队列放不下则拒绝请求。但是单纯地基于请求数的限流不能控制资源使用量,而且只作用于分片级子请求的传输层,对于我们前面分析的接入层无法起到有效的保护作用。原生版本也有内存熔断策略,但是在协调节点接入层并没有做限制。
我们的优化方案是基于内存资源的漏桶策略。我们将节点 JVM 内存作为漏桶的资源,当内存资源足够的时候,请求可以正常处理;当内存使用量到达一定阈值的时候分区间阶梯式平滑限流。例如上图中浅黄色的区间限制写入,深黄色的区间限制查询,底部红色部分作为预留 buffer,预留给处理中的请求、merge 等操作,以保证节点内存的安全性。
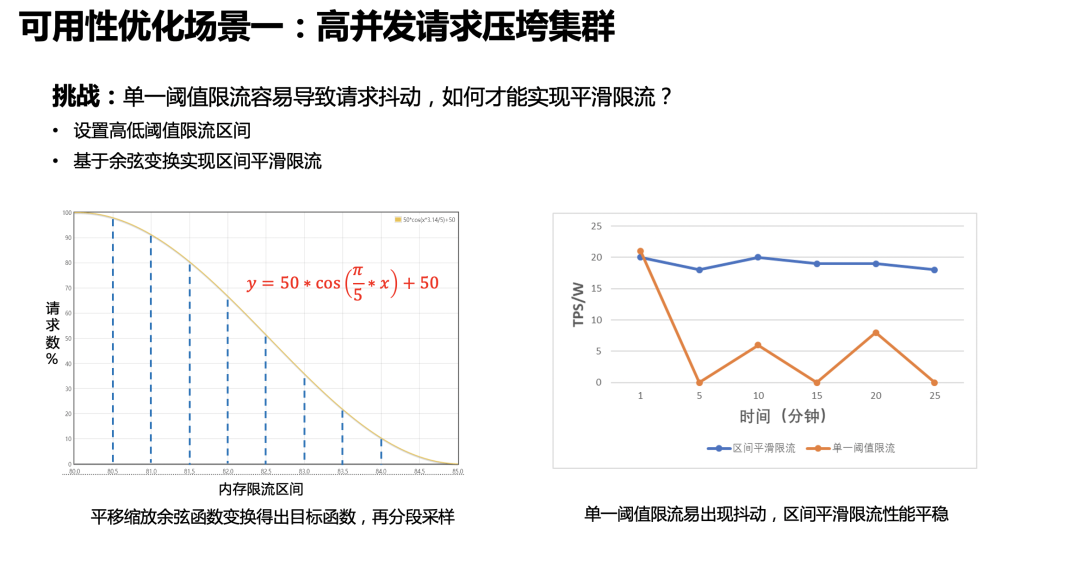
限流方案里面有一个挑战是:我们如何才能实现平滑限流?因为采用单一的阈值限流很容易出现请求抖动,例如请求一上来把内存打上去马上触发限流,而放开一点点请求又会涌进来把内存打上去。我们的方案是设置了高低限流阈值区间,在这个区间中,基于余弦变换实现请求数和内存资源之间的平滑限流。当内存资源足够的时候,请求通过率 100%,当内存到达限流区间逐步上升的时候,请求通过率随之逐步下降。而当内存使用量下降的时候,请求通过率也会逐步上升,不会一把放开。通过实际测试,平滑的区间限流能在高压力下保持稳定的写入性能。
我们基于内存资源的区间平滑限流策略是对原生版本基于请求数漏桶策略的有效补充,并且作用范围更广,覆盖协调节点、数据节点的接入层和传输层,并不会替代原生的限流方案。
4. 易用性
用户数暴增,留给系统验证切换的时间非常短,这要求我们必须使用一种简单快速的解决方案。需要在一周之内输出适用方案,并进行线上数据的切换。如原架构使用kafka队列做数据的投递,由自研的消息接入服务进行消息的接入、清洗并最终写入自研的服务质量数据存储分析服务。由于时间紧迫,新的方案需要尽量保留原有架构的大部分基础设施,并做尽量少的代码开发改动。
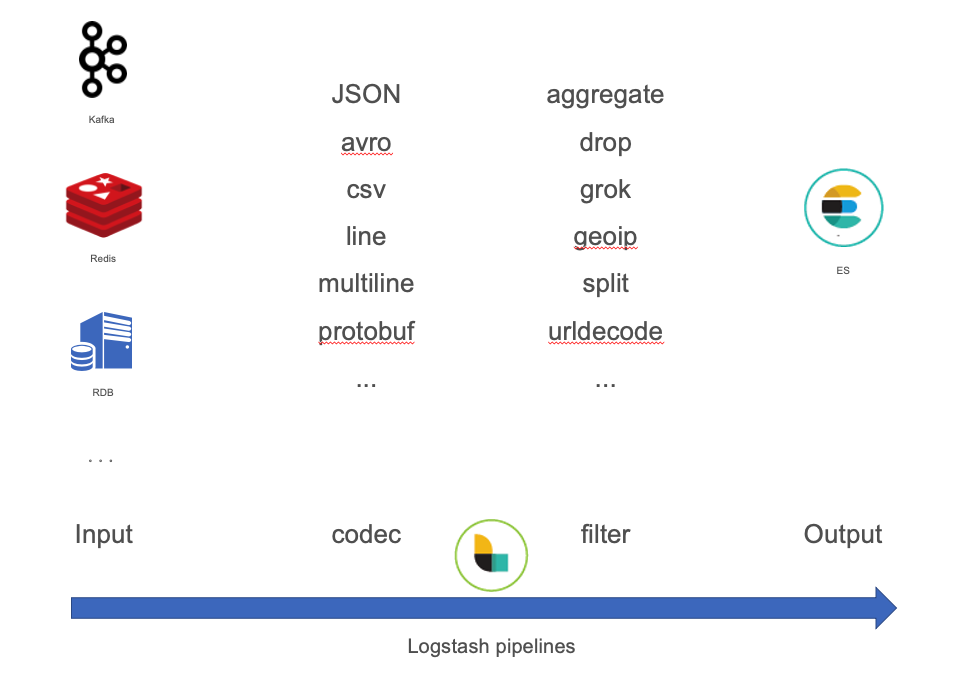
在这方面,ES的社区生态做得非常完备。从采集端、收集端到存储都有一整套解决方案。通过logstash的易用性和强大的生态插件,可以快速替代原有的自研数据接入组件,进行数据的清洗转换等ETL过程。如原有架构中使用的kafka,在logstash中就已经包含了相应的input插件。并且有大量数据格式的解析插件支持,对于数据的一些解析、过滤、清洗等操作可以直接在logstash的pipeline中进行简单的配置即可,基本上是0开发量。
丰富的各语言SDK,方便快速的对服务质量分析平台前后台进行快速切换,实际从代码修改到上线完成只用了一天的时间。同时,ES社区也比较活跃,国内有10万+的开发者参与其中,问题都可以比较快地得到回复和解决。在此,也特别感谢ES的研发团队及一线运维团队,在疫情期间,对腾讯会议进行了7*24小时的支持,并对于使用ES的一些疑难问题给出了大量的解决方案。
三、腾讯云ES高可用架构为业务提供高效稳定的读写能力
在腾讯会议服务质量数据分析系统全部切换至ELK架构之后,达成了100w+/s的数据写入性能要求,数据从入队列到可被搜索到的延迟时间从小时级别缩短至了秒级,保证了业务数据同步的实时性要求以及运营分析系统的查询延迟要求。
截止到目前,腾讯会议集群随着业务的增长已平滑扩展至数百节点,百万核数规模,满足了业务数据增长下的扩容需求。
并且,得益于内核稳定性方向的大量优化,腾讯云ES的服务稳定性上达到了99.99%,保证了万亿级别数据量高压力使用场景下的服务稳定性,为腾讯会议的运营分析及问题排查保驾护航。
腾讯会议的普及与腾讯云ES在数据搜索查询、高并发、弹性扩展以及安全领域的技术能力密切相关。腾讯云ES在腾讯会议质量服务上的成功实践,也为视频会议这个细分行业领域提供了一个优秀的范例,拓展了行业解决方案的思路。
未来,腾讯云ES仍将不断迭代,针对用户需求,不推打磨技术和产品,持续输出稳定可靠的Elasticsearch服务。
参考资料:
[1] Elasticsearch Service免费体验馆:
https://cloud.tencent.com/act/free/personal/bigdata?from=12847#pproduct
服务质量分析:腾讯会议&腾讯云Elasticsearch玩出了怎样的新操作?的更多相关文章
- 揭秘日活千万腾讯会议全量云原生化上TKE技术实践
腾讯会议,一款联合国都Pick的线上会议解决方案,提供完美会议品质和灵活协作空间,广泛应用在政府.医疗.教育.企业等各个行业.大家从文章8天扩容100万核,腾讯会议是如何做到的?都知道腾讯会议背后的计 ...
- 腾讯会议大规模使用Kubernetes的技术实践
腾讯会议,一款提供灵活协作的线上会议解决方案.其中大量的模块是有状态服务,在使用Kubernetes为其进行容器化部署时,Pod升级需保持共享内存.长连接服务.升级时只容忍ms级抖动,需提供大规模分批 ...
- Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 讯飞科大 语音云.docx \Atitit 代码托管与虚拟主机.docx \Atitit 企业文化 每日心灵 鸡汤 值班 发布.docx \Atitit 几大研发体系对比 Stage-Gat
Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 ...
- 腾讯云Elasticsearch集群规划及性能优化实践
一.引言 随着腾讯云 Elasticsearch 云产品功能越来越丰富,ES 用户越来越多,云上的集群规模也越来越大.我们在日常运维工作中也经常会遇到一些由于前期集群规划不到位,导致后期业务增长集群 ...
- 腾讯混合云存储 TStor 系列再添新成员,并行存储一体机正式发布
最近国内某大型互联网公司依靠其数据优势成功上市,可见数据的重要性,而数据和存储密不可分,您真的知道自己需要更高性能存储吗? 在当今数据爆发式增长的时代,数据已经成为很多行业最重要的资源,没有之一. 数 ...
- Flutter第1天--初始分析+Dart方言+Canvas简绘 - 云+社区
Flutter第1天--初始分析+Dart方言+Canvas简绘 - 云+社区 - 腾讯云 https://cloud.tencent.com/developer/article/1378974
- 30分钟全方位了解阿里云Elasticsearch
摘要:阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据搜 ...
- 30分钟全方位了解阿里云Elasticsearch(附公开课完整视频)
摘要: 阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据 ...
- 可能是全网首个支持阿里云Elasticsearch Xapck鉴权的Skywalking
可能是全网首个支持阿里云Elasticsearch Xapck鉴权的Skywalking 对Skywalking有兴趣的同学参见:年轻人的第一个APM-Skywalking 之前在搭建Skywalki ...
随机推荐
- ubuntu镜像源切换
换源准备: 换源之前明确使用平台,X86架构.ARM架构的源,ubuntu18.04和unbuntu16.04等源均不同,切忌病急乱投医,看到一个源复制过来添加后没用. 分析一条源: deb http ...
- SpringBoot项目jar包启动脚本
startup.bat @echo off set path=X:\xxxxxxx\Java\JDK\jre\bin START "项目名" "%path%\java&q ...
- 从 Tapable 中得到的启发
Tapable Why Tapable 前端开发中 Webpack 本质上是基于事件流的运行机制,它的工作流程是将特定的任务分发到指定的事件钩子中去完成.而实现这一切的核心就是 tapable,Web ...
- SQL注入之Boolean型盲注
什么是Boolean型注入 Boolean型的注入意思就是页面返回的结果是Boolean型的,通过构造SQL判断语句,查看页面的返回结果是否报错,页面返回是否正常等来判断哪些SQL判断条件时成立的,通 ...
- git和github入门指南(6)
6.交作业的流程 以下内容是螺钉课堂在线就业班提交作业的要求,非螺钉课堂在线就业班学员不用学习 螺钉课堂作业全程采用git管理,希望在日常使用中,加深对git和github的理解 具体流程: 1.注册 ...
- 关于 charset 的几种编码方式
经常遇到charset=gb2312.charset=iso-8859-1.charset=utf-8这几种编码方式,它们有什么不同,看下面的图 编码方式 含义 charset=iso-8859-1 ...
- Windows高DPI系列控件(一) - 饼图
目录 一.醉一醉 二.效果展示 三.高DPI适配 1.高DPI框架运作 2.适配高DPI 3.适配饼图 四.相关文章 原文链接:Windos高DPI系列控件(一) - 饼图 一.醉一醉 眨眼功夫,20 ...
- 一个ACE 架构的 C++ Timer
.h #ifndef _Timer_Task_ #define _Timer_Task_ #pragma once #include <ace/Task.h> #include <a ...
- python数据结构(一)
collections --容器数据类型,collections模块包含了除内置类型list,dict和tuple以外的其他容器数据类型. Counter 作为一个容器可以追踪相同的值增加了多少次 # ...
- NLP(一)
“自然语言处理”(Natural Language Processing 简称 NLP)包含所有用计算机对自然语言进行的操作. 自然语言工具包(NLTK) 语言处理任务与相应 NLTK 模块以及功能描 ...