MVCC(转)
什么是 MVCC
MVCC (Multiversion Concurrency Control) 中文全程叫多版本并发控制,是现代数据库(包括 MySQL、Oracle、PostgreSQL 等)引擎实现中常用的处理读写冲突的手段,目的在于提高数据库高并发场景下的吞吐性能。
如此一来不同的事务在并发过程中,SELECT 操作可以不加锁而是通过 MVCC 机制读取指定的版本历史记录,并通过一些手段保证保证读取的记录值符合事务所处的隔离级别,从而解决并发场景下的读写冲突。
下面举一个多版本读的例子,例如两个事务 A 和 B 按照如下顺序进行更新和读取操作
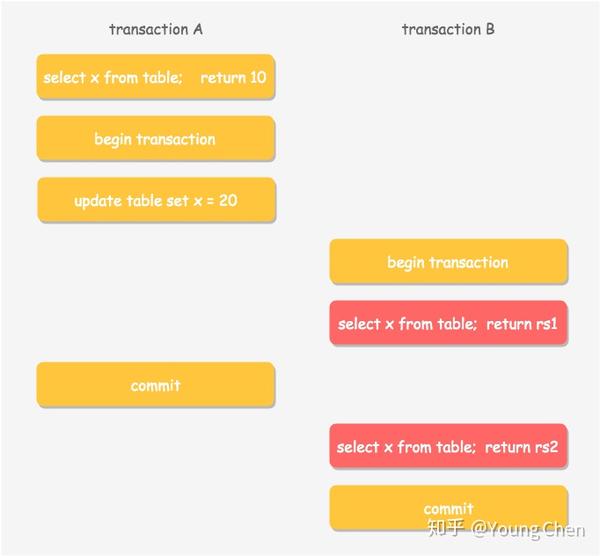
在事务 A 提交前后,事务 B 读取到的 x 的值是什么呢?答案是:事务 B 在不同的隔离级别下,读取到的值不一样。
- 如果事务
B的隔离级别是读未提交(RU),那么两次读取均读取到x的最新值,即20。 - 如果事务
B的隔离级别是读已提交(RC),那么第一次读取到旧值10,第二次因为事务A已经提交,则读取到新值 20。 - 如果事务
B的隔离级别是可重复读或者串行(RR,S),则两次均读到旧值10,不论事务A是否已经提交。
可见在不同的隔离级别下,数据库通过 MVCC 和隔离级别,让事务之间并行操作遵循了某种规则,来保证单个事务内前后数据的一致性。
为什么需要 MVCC
InnoDB 相比 MyISAM 有两大特点,一是支持事务而是支持行级锁,事务的引入带来了一些新的挑战。相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况:
- 更新丢失(
Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题 —— 最后的更新覆盖了其他事务所做的更新。如何避免这个问题呢,最好在一个事务对数据进行更改但还未提交时,其他事务不能访问修改同一个数据。 - 脏读(
Dirty Reads):一个事务正在对一条记录做修改,在这个事务并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些尚未提交的脏数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做 “脏读”。 - 不可重复读(
Non-Repeatable Reads):一个事务在读取某些数据已经发生了改变、或某些记录已经被删除了!这种现象叫做“不可重复读”。 - 幻读(
Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为 “幻读”。
以上是并发事务过程中会存在的问题,解决更新丢失可以交给应用,但是后三者需要数据库提供事务间的隔离机制来解决。实现隔离机制的方法主要有两种:
- 加读写锁
- 一致性快照读,即
MVCC
但本质上,隔离级别是一种在并发性能和并发产生的副作用间的妥协,通常数据库均倾向于采用 Weak Isolation。
InnoDB 中的 MVCC
本文聚焦于 MySQL 中的 MVCC 实现,从 《高性能 MySQL》一书中对 MVCC 的介绍可知:
MySQL中InnoDB引擎支持MVCC- 应对高并发事务,
MVCC比单纯的加行锁更有效, 开销更小 MVCC在读已提交(Read Committed)和可重复读(Repeatable Read)隔离级别下起作用MVCC既可以基于乐观锁又可以基于悲观锁来实现
InnoDB MVCC 实现原理
InnoDB 中 MVCC 的实现方式为:每一行记录都有两个隐藏列:DATA_TRX_ID、DATA_ROLL_PTR(如果没有主键,则还会多一个隐藏的主键列)。

DATA_TRX_ID
记录最近更新这条行记录的事务 ID,大小为 6 个字节
DATA_ROLL_PTR
表示指向该行回滚段(rollback segment)的指针,大小为 7 个字节,InnoDB 便是通过这个指针找到之前版本的数据。该行记录上所有旧版本,在 undo 中都通过链表的形式组织。
DB_ROW_ID
行标识(隐藏单调自增 ID),大小为 6 字节,如果表没有主键,InnoDB 会自动生成一个隐藏主键,因此会出现这个列。另外,每条记录的头信息(record header)里都有一个专门的 bit(deleted_flag)来表示当前记录是否已经被删除。
如何组织 Undo Log 链
关于 Redo Log 和 Undo Log 的相关概念可见之前的文章 InnoDB 中的 redo 和 undo log
上文提到,在多个事务并行操作某行数据的情况下,不同事务对该行数据的 UPDATE 会产生多个版本,然后通过回滚指针组织成一条 Undo Log 链,这节我们通过一个简单的例子来看一下 Undo Log 链是如何组织的,DATA_TRX_ID 和 DATA_ROLL_PTR 两个参数在其中又起到什么样的作用。
还是以上文 MVCC 的例子,事务 A 对值 x 进行更新之后,该行即产生一个新版本和旧版本。假设之前插入该行的事务 ID 为 100,事务 A 的 ID 为 200,该行的隐藏主键为 1。
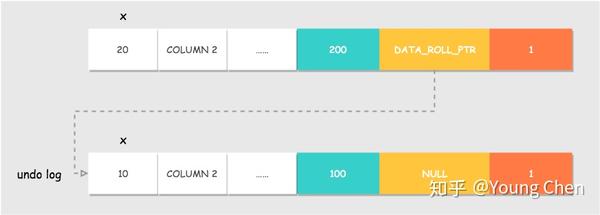
事务 A 的操作过程为:
- 对
DB_ROW_ID = 1的这行记录加排他锁 - 把该行原本的值拷贝到
undo log中,DB_TRX_ID和DB_ROLL_PTR都不动 - 修改该行的值这时产生一个新版本,更新
DATA_TRX_ID为修改记录的事务ID,将DATA_ROLL_PTR指向刚刚拷贝到undo log链中的旧版本记录,这样就能通过DB_ROLL_PTR找到这条记录的历史版本。如果对同一行记录执行连续的UPDATE,Undo Log会组成一个链表,遍历这个链表可以看到这条记录的变迁 - 记录
redo log,包括undo log中的修改
那么 INSERT 和 DELETE 会怎么做呢?其实相比 UPDATE 这二者很简单,INSERT 会产生一条新纪录,它的 DATA_TRX_ID 为当前插入记录的事务 ID;DELETE 某条记录时可看成是一种特殊的 UPDATE,其实是软删,真正执行删除操作会在 commit 时,DATA_TRX_ID 则记录下删除该记录的事务 ID。
如何实现一致性读 —— ReadView
在 RU 隔离级别下,直接读取版本的最新记录就 OK,对于 SERIALIZABLE 隔离级别,则是通过加锁互斥来访问数据,因此不需要 MVCC 的帮助。因此 MVCC 运行在 RC 和 RR 这两个隔离级别下,当 InnoDB 隔离级别设置为二者其一时,在 SELECT 数据时就会用到版本链
核心问题是版本链中哪些版本对当前事务可见?
InnoDB 为了解决这个问题,设计了 ReadView(可读视图)的概念。
RR 下的 ReadView 生成
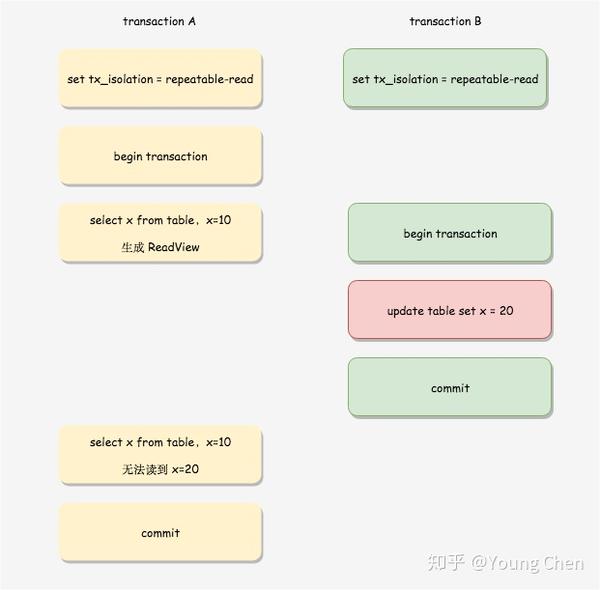
在 RR 隔离级别下,每个事务 touch first read 时(本质上就是执行第一个 SELECT 语句时,后续所有的 SELECT 都是复用这个 ReadView,其它 update, delete, insert 语句和一致性读 snapshot 的建立没有关系),会将当前系统中的所有的活跃事务拷贝到一个列表生成ReadView。
下图中事务 A 第一条 SELECT 语句在事务 B 更新数据前,因此生成的 ReadView 在事务 A 过程中不发生变化,即使事务 B 在事务 A 之前提交,但是事务 A 第二条查询语句依旧无法读到事务 B 的修改。
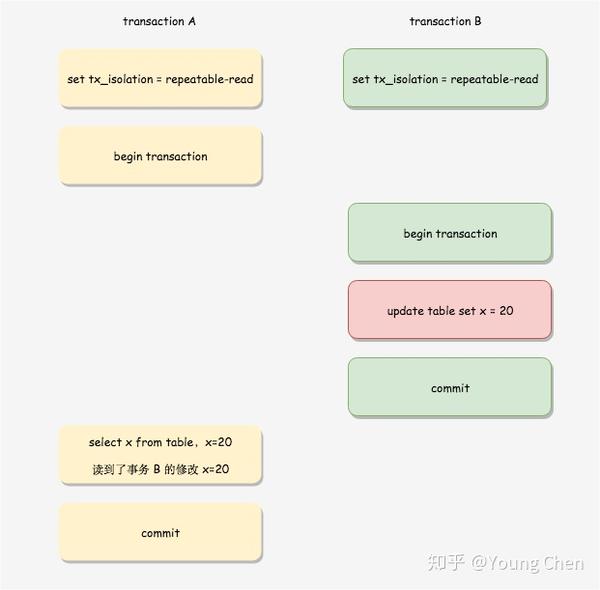
下图中,事务 A 的第一条 SELECT 语句在事务 B 的修改提交之后,因此可以读到事务 B 的修改。但是注意,如果事务 A 的第一条 SELECT 语句查询时,事务 B 还未提交,那么事务 A 也查不到事务 B 的修改。
RC 下的 ReadView 生成
在 RC 隔离级别下,每个 SELECT 语句开始时,都会重新将当前系统中的所有的活跃事务拷贝到一个列表生成 ReadView。二者的区别就在于生成 ReadView 的时间点不同,一个是事务之后第一个 SELECT 语句开始、一个是事务中每条 SELECT 语句开始。
ReadView 中是当前活跃的事务 ID 列表,称之为 m_ids,其中最小值为 up_limit_id,最大值为 low_limit_id,事务 ID 是事务开启时 InnoDB 分配的,其大小决定了事务开启的先后顺序,因此我们可以通过 ID 的大小关系来决定版本记录的可见性,具体判断流程如下:
- 如果被访问版本的
trx_id小于m_ids中的最小值up_limit_id,说明生成该版本的事务在ReadView生成前就已经提交了,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id大于m_ids列表中的最大值low_limit_id,说明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。需要根据Undo Log链找到前一个版本,然后根据该版本的 DB_TRX_ID 重新判断可见性。 - 如果被访问版本的
trx_id属性值在m_ids列表中最大值和最小值之间(包含),那就需要判断一下trx_id的值是不是在m_ids列表中。如果在,说明创建ReadView时生成该版本所属事务还是活跃的,因此该版本不可以被访问,需要查找 Undo Log 链得到上一个版本,然后根据该版本的DB_TRX_ID再从头计算一次可见性;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。 - 此时经过一系列判断我们已经得到了这条记录相对
ReadView来说的可见结果。此时,如果这条记录的delete_flag为true,说明这条记录已被删除,不返回。否则说明此记录可以安全返回给客户端。
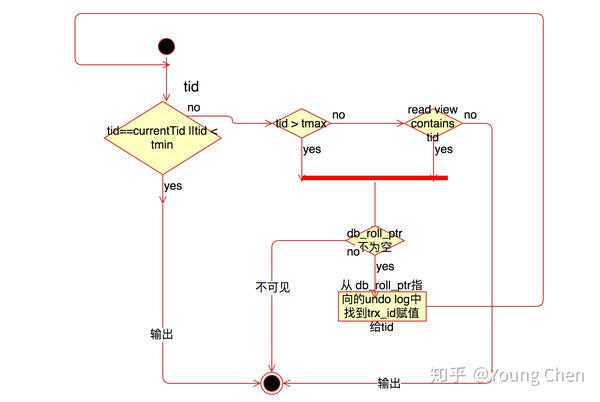
举个例子
RC 下的 MVCC 判断流程
我们现在回看刚刚的查询过程,为什么事务 B 在 RC 隔离级别下,两次查询的 x 值不同。RC 下 ReadView 是在语句粒度上生成的。
当事务 A 未提交时,事务 B 进行查询,假设事务 B 的事务 ID 为 300,此时生成 ReadView 的 m_ids 为 [200,300],而最新版本的 trx_id 为 200,处于 m_ids 中,则该版本记录不可被访问,查询版本链得到上一条记录的 trx_id 为 100,小于 m_ids 的最小值 200,因此可以被访问,此时事务 B 就查询到值 10 而非 20。
待事务 A 提交之后,事务 B 进行查询,此时生成的 ReadView 的 m_ids 为 [300],而最新的版本记录中 trx_id 为 200,小于 m_ids 的最小值 300,因此可以被访问到,此时事务 B 就查询到 20。
RR 下的 MVCC 判断流程
如果在 RR 隔离级别下,为什么事务 B 前后两次均查询到 10 呢?RR 下生成 ReadView 是在事务开始时,m_ids 为 [200,300],后面不发生变化,因此即使事务 A 提交了,trx_id 为 200 的记录依旧处于 m_ids 中,不能被访问,只能访问版本链中的记录 10。
一个争论点
其实并非所有的情况都能套用 MVCC 读的判断流程,特别是针对在事务进行过程中,另一个事务已经提交修改的情况下,这时不论是 RC 还是 RR,直接套用 MVCC 判断都会有问题,例如 RC 下:

事务 A 的 trx_id = 200,事务 B 的 trx_id = 300,且事务 B 修改了数据之后在事务 A 之前提交,此时 RC 下事务 A 读到的数据为事务 B 修改后的值,这是很显然的。下面我们套用下 MVCC 的判断流程,考虑到事务 A 第二次 SELECT 时,m_ids 应该为 [200],此时该行数据最新的版本 DATA_TRX_ID = 300 比 200 大,照理应该不能被访问,但实际上事务 A 选取了这条记录返回。
这里其实应该结合 RC 的本质来看,RC 的本质就是事务中每一条 SELECT 语句均可以看到其他已提交事务对数据的修改,那么只要该事物已经提交其结果就是可见的,与这两个事务开始的先后顺序无关,不完全适用于 MVCC 读。
RR 级别下还是用之前那张图:
这张图的流程中,事务 B 的 trx_id = 300 比事务 A 200 小,且事务 B 先于事务 A 提交,按照 MVCC 的判断流程,事务 A 生成的 ReadView 为 [200],最新版本的行记录 DATA_TRX_ID = 300 比 200 大,照理不能访问到,但是事务 A 实际上读到了事务 B 已经提交的修改。这里还是结合 RR 本质进行解释,RR 的本质是从第一个 SELECT 语句生成 ReadView 开始,任何已经提交过的事务的修改均可见。
总结
RC、RR 两种隔离级别的事务在执行普通的读操作时,通过访问版本链的方法,使得事务间的读写操作得以并发执行,从而提升系统性能。RC、RR 这两个隔离级别的一个很大不同就是生成 ReadView 的时间点不同,RC 在每一次 SELECT 语句前都会生成一个 ReadView,事务期间会更新,因此在其他事务提交前后所得到的 m_ids 列表可能发生变化,使得先前不可见的版本后续又突然可见了。而 RR 只在事务的第一个 SELECT 语句时生成一个 ReadView,事务操作期间不更新。
MVCC(转)的更多相关文章
- MySQL MVCC(多版本并发控制)
概述 为了提高并发MySQL加入了多版本并发控制,它把旧版本记录保存在了共享表空间(undolog),当事务提交之后将重做日志写入磁盘(前提innodb_flush_log_at_trx_commit ...
- Distributed MVCC based cross-row transaction
The algorithm for supporting distributed MVCC based cross-row transactions on top of a distributed k ...
- Hbase0.96 MVCC Lock 知识梳理
HBASE0.96 MVCC 写入的时候 每个Region包含一个Memstore,维护一个MultiVersionConsistencyControl对象 w = mvcc.beginMemstor ...
- MVCC PostgreSQL实现事务和多版本并发控制的精华
原创文章,同步发自作者个人博客,http://www.jasongj.com/sql/mvcc/ PostgreSQL针对ACID的实现机制 事务的实现原理可以解读为RDBMS采取何种技术确保事务的A ...
- bdb mvcc: buffer 何时可以被 看到; mvcc trans何时被移除
# txn.h struct __db_txnregion SH_TAILQ_HEAD(__active) active_txn; SH_TAILQ_HEAD(__mvcc) mvcc_txn; # ...
- Different Approaches for MVCC
https://www.enterprisedb.com/well-known-databases-use-different-approaches-mvcc Well-known Databases ...
- HBase中MVCC的实现机制及应用情况
MVCC(Multi-Version Concurrent Control),即多版本并发控制协议,广泛使用于数据库系统.本文将介绍HBase中对于MVCC的实现及应用情况. MVCC基本原理 在介绍 ...
- 【mysql】关于innodb中MVCC的一些理解
一.MVCC简介 MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代 ...
- lightning mdb 源代码分析(4)—MVCC/COW
本博文将描述MVCC和cow技术以及LMDB中如何使用以及实现这两种技术. COW(Copy On Write): COW技术背后的思想是拖延技术,基本方法是假如有多个调用者需要访问的资源,在其初始化 ...
- 浅谈mysql mvcc
以下为个人理解,如有错误,还望指正!! mysql的大多数事务型存储引擎实现的都不是简单的行级锁,基于提升并发性能的考虑,他们一般都同时实现了多版本并发控制,可以认为MVCC是行级锁的一个变种,但是它 ...
随机推荐
- MeteoInfoLab脚本示例:MODIS AOD
MODIS的气溶胶光学厚度(AOD)产品应用很广,数据可以在Giovanni上下载:http://disc.sci.gsfc.nasa.gov/giovanni/overview/index.html ...
- Jmeter之参数化函数助手__randomstring
1.Tools->函数助手对话框,选择__Random String,2表示随机生成的字符长度:3表示从哪些字符中随机生成:然后点击生成,得到对应的变量: 5中372表示该函数随机生成的字符串, ...
- swoole热启动
通过扫描指定的要扫描的目录,把所有文件找出来,分别md5 连接字符串,最后再md5返回 启动定时器,扫描,当前的加密值和以前一样不管,否则就重启服务,把当前赋值给旧值 . httpServer.php ...
- jdk、eclipse和idea安装
一.jdk下载与环境配置与IDEA 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-213315 ...
- 小程序商城Mall,打造最佳SpringCloudAlibaba最佳实践
背景 由于一路一来看过很多的技术体系,也见证一些技术体系停止维护,想用自己觉得比较好的一套技术体系来做一个分布式微服务系统,包括开发层面,中间件层面和运维层面的技术,作为自己希望的一个技术团队里的技术 ...
- 本地文件r如何上传到github上
来源:http://www.cnblogs.com/shenchanghui/p/7184101.html 来源:http://blog.csdn.net/zamamiro/article/detai ...
- JavaScript监听滚动条的进度条
<style type="text/css"> *{ margin: 0; padding: 0; } .g-box{ width: 100%; height: 400 ...
- vue封装tab切换
vue封装tab切换 预览: 第一种 通过父传子标题,子传父事件 子组件 <template> <div class='app'> <div class="ta ...
- css-设置背景透明度
实现透明的css方法通常有以下3种方式,以下是不透明度都为80%的写法: css3的opacity:x,x 的取值从 0 到 1,如opacity: 0.8 兼容性:IE6.7.8不支持,IE9及以上 ...
- 基于gin的golang web开发:模型验证
Gin除了模型绑定还提供了模型验证功能.你可以给字段指定特定的规则标签,如果一个字段用binding:"required"标签修饰,在绑定时该字段的值为空,那么将返回一个错误.开发 ...