scrapy-splash抓取动态数据例子八
一、介绍
本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息。
给定关键字:个性化;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
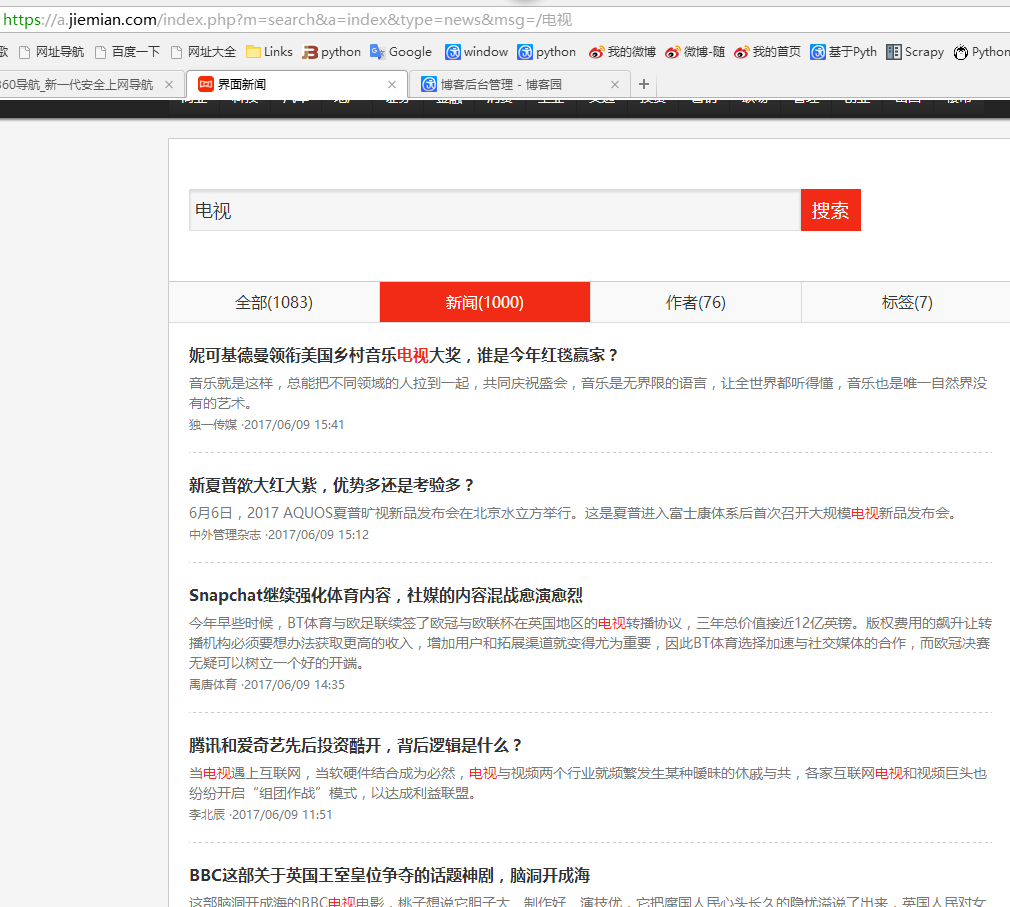
三、数据抓取
针对上面的网站信息,来进行抓取
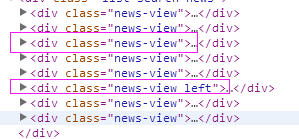
1、首先抓取信息列表
抓取代码:sels = site.xpath('//div[contains(@class,"news-view")]')
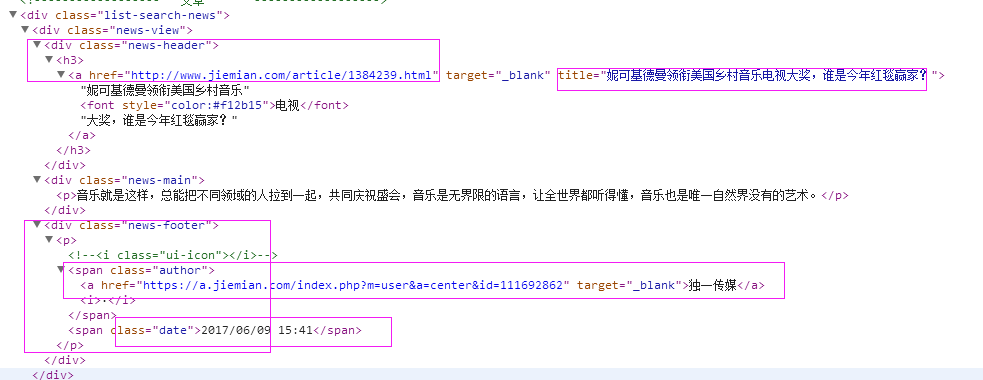
2、抓取标题
抓取代码:title = sel.xpath('.//div[@class="news-header"]/h3/a/@title')[0].extract()
3、抓取链接
抓取代码:it['url'] = sel.xpath('.//div[@class="news-header"]/h3/a/@href')[0].extract()
4、抓取日期
抓取代码:dates = sel.xpath('.//div[@class="news-footer"]/p/span[2]/text()')
5、抓取来源
抓取代码:sources =sel.xpath('.//div[@class="news-footer"]/p/span[1]/a/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class jiemianSpider(Spider):
name = 'jiemian' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_keywords = cf.GetValue("section", "information_keywords")
information_wordlist = information_keywords.split(';')
websearchurl = cf.GetValue("jiemian", "websearchurl")
start_urls = []
for word in information_wordlist:
print websearchurl + word
start_urls.append(websearchurl + word) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText): currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
dt = strDateText.replace('/', '-')
strDate = re.findall(datePattern, dt)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
return False, '' def parse(self, response):
site = Selector(response) sels = site.xpath('//div[contains(@class,"news-view")]')
keyword = response.meta['keyword']
item_list = []
for sel in sels:
dates = sel.xpath('.//div[@class="news-footer"]/p/span[2]/text()')
flag,date =self.date_isValid(dates[0].extract())
title = sel.xpath('.//div[@class="news-header"]/h3/a/@title')[0].extract()
if flag and title.find(keyword)>-1:
it = SplashTestItem()
it['title'] = title
it['url'] = sel.xpath('.//div[@class="news-header"]/h3/a/@href')[0].extract()
it['date'] = date
it['keyword'] = keyword
sources =sel.xpath('.//div[@class="news-footer"]/p/span[1]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
item_list.append(it)
return item_list
scrapy-splash抓取动态数据例子八的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
- scrapy-splash抓取动态数据例子十五
一.介绍 本例子用scrapy-splash爬取电视之家(http://www.tvhome.com/news/)网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信 ...
随机推荐
- python字符编码与解码 unicode,str
解释以下几个问题: (1)python2中str和unicode是两种字符串类型,与字符编码方式是什么关系? (2)str和unicode是怎么相互转换的? (3)'\x...':'\u...', ' ...
- Linux下源码安装jdk
1.到官网下载 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- mybatis 报错: Invalid bound statement (not found)
错误: org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): test.dao.Produc ...
- SpringBoot学习:读取yml和properties文件的内容
一.在SpringBoot实现属性注入: 1).添加pom依赖jar包: <!-- 支持 @ConfigurationProperties 注解 --> <!-- https://m ...
- 【转载】关于Android RecyclerView的那些开源LayoutManager
原文地址:http://blog.coderclock.com/2017/03/26/android/%E5%85%B3%E4%BA%8EAndroid%20RecyclerView%E7%9A%84 ...
- eclipse 查看jdk源码
eclipse中引入jdk源码的设置: 设置: 1.点 "window"-> "Preferences" -> "Java" ...
- 洛谷P2278 [HNOI2003] 操作系统
题目传送门 分析:题目中提到了优先级,很显然这题要用优先队列+模拟.题目中很多细节需要注意,还是在代码中解释吧,这里我用的是手打的堆. Code: #include<bits/stdc++.h& ...
- 2017广西邀请赛 Query on A Tree (可持续化字典树)
Query on A Tree 时间限制: 8 Sec 内存限制: 512 MB提交: 15 解决: 3[提交][状态][讨论版] 题目描述 Monkey A lives on a tree. H ...
- Aizu 2784 Similarity of Subtrees(树哈希)
Similarity of Subtrees Define the depth of a node in a rooted tree by applying the following rules r ...
- Visual Studio Xamarin提示Bonjour backend初始化失败
Visual Studio Xamarin提示Bonjour backend初始化失败 错误信息:The Bonjour backend failed to initialize, automatic ...