Spark运行模式_local(本地模式)
本地运行模式 (单机)
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.


那么,这些线程都运行在什么进程下呢?
运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
那么,这些执行任务的线程,到底是共享在什么进程中呢?
我们用如下命令提交作业:

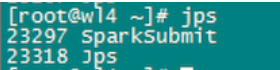
这个SparkSubmit进程又当爹、又当妈,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。(如下图所示:driver的web ui)

这里有个小插曲,因为driver程序在应用程序结束后就会终止,那么如何在web界面看到该应用程序的执行情况呢,需要如此这般:(如下图所示)

转载自:
作者:俺是亮哥
链接:https://www.jianshu.com/p/65a3476757a5
來源:简书
Spark运行模式_local(本地模式)的更多相关文章
- Windows下nodejs 模块配置 全局模式与本地模式的区别
第1步:下载.安装文件 (nodejs的官网http://www.nodejs.org/download/ ) 第2步:安装相关模块环境 打开C:\Program Files\nodejs 目录你会发 ...
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- Hadoop运行模式:本地模式、伪分布模式、完全分布模式
1.本地模式:默认模式 - 不对配置文件进行修改. - 使用本地文件系统,而不是分布式文件系统. - Hadoop不会启动NameNode.DataNode.ResourceManager.NodeM ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- 【node.js】本地模式安装express:'express' 不是内部或外部命令,也不是可运行的程序或批处理文件。
今天闲来无事想起了node.js,因此到网上下载了一个node.js的安装程序进行安装.其中: 安装程序:node-v0.11.13-x64.msi PC系统:Windows 7 自定义安装路径:D: ...
- 55.storm 之 hello word(本地模式)
strom hello word 概述 然后卡一下代码怎么实现的: 编写数据源类:Spout.可以使用两种方式: 继承BaseRichSpout类 实现IRichSpout接口 主要需要实现或重写几个 ...
- hadoop的安装和配置(一)本地模式
博主会用三篇文章来为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 本地模式: 思路走向 |--------------------| | ①:配置Java环境 | | ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
随机推荐
- application/x-www-form-urlencode 和 multiple/form-data
一.概述 在学习ajax的时候,如果用post请求,需要设置如下代码. ajax.setRequestHeader("content-type","application ...
- DevExpress控件使用之多重坐标图形的绘制 z
有时候,基于对一些年份.月份的统计,需要集成多个数值指标进行分析,因此就需要把多种数据放到一个图形里面展现,也成为多重坐标轴,多重坐标轴可以是多个X轴,也可以是Y轴,它们的处理方式类似.本文通过一个例 ...
- Cache及(HttpRuntime.Cache与HttpContext.Current.Cache)
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/avon520/archive/2009/11/25/4872704.aspx .NET中Cache有两种调用方式:Ht ...
- Oracle Update语句
Oracle没有update from语法,可以通过四种写法实现同样的功能: 一.标准update语法(常用.速度可能最慢) 当更新的表示单个或者被更新的字段不需要关联表带过来,此法是最好的选择. u ...
- Native广告月入万刀的全部细节!
一步一步跑Native原生广告: 第一步:跑native前期的准备工作 第二步:阅读大神的Native文档(100多页,英文,建议找一个支持在线翻译功能的app来阅读) 第三步:阅读我的几十条经验总结 ...
- mybatis插入返回主键
useGeneratedKeys="true" keyProperty="id" <insert id="insertReturnPrimar ...
- java中数据类型的范围
前言:最近:本菜鸡在准备pat,可以每次遇到数据类型的时候都得去查找范围,因此本着学习的目的,来总结一下java中的数据类型. 因此我用mindManager做了一个思维图
- 【luogu P4017 最大食物链计数】 题解
题目链接:https://www.luogu.org/problemnew/show/P4017 DAG + DP #include <queue> #include <cstdio ...
- 跨浏览器的事件对象EventUtil
var EventUtil = function(){ /*--addHandler--*/ addHandler:function(element,type,handler){ if(element ...
- TCP Congestion Control
TCP Congestion Control Congestion occurs when total arrival rate from all packet flows exceeds R ove ...