《Git学习指南》学习笔记(一)
第二章 入门
git的安装
在Linux下,git的安装很简单。以我的系统Deepin/Ubuntu为例,只需在终端敲入sudo apt-get install git即可。其他Linux发行版可尝试yum install git-core。
第一个Git项目
初学时,建议使用一个新创建的目录来进行测试。
创建版本库
版本库可以存储项目及其历时数据。我们可以用init来进行创建。
首先我们新建一个空目录gittest,然后新建两个文本文件,如a.txt和b.txt,内容任意,然后使用init来创建版本库:
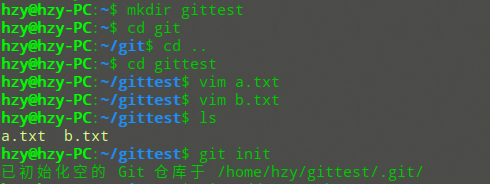
观察文件夹,可以发现已经多了一个名为.git的隐藏文件:

这样就说明你的版本库已经创建成功。
首次提交
刚刚仅仅是把版本库创建了,那我的两个文件如何添加到版本库中去呢?此时需要使用两个命令:add和commit,每次提交git都会为其生成一个散列值,这也是git对所有版本进行区分的一个键值。

如图,已经成功提交了刚刚创建的a和b两个文件。
检查状态
git如何检查版本库文件的状态呢?
首先我们来把a.txt删除,然后新建一个c.txt,最后查看状态:

status命令用于显示自上次提交以来所有发生的修改。c.txt文件被标为未跟踪状态,是因为它还没有被add进版本库。
使用diff命令可以显示每个被修改的行,但在终端上看可能会显得比较晦涩难懂:
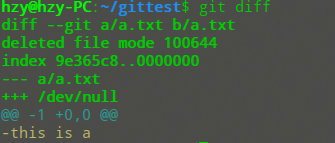
因此还是建议使用图形化工具如kdiff3来查看。这里请大家自行查找。
提交修改
我们修改b.txt文件内容,希望将更改加入到版本库中,对希望删除的文件使用rm命令,操作之后同样也需要执行add命令,然后查看状态:

最后,别忘了commit:

显示历史
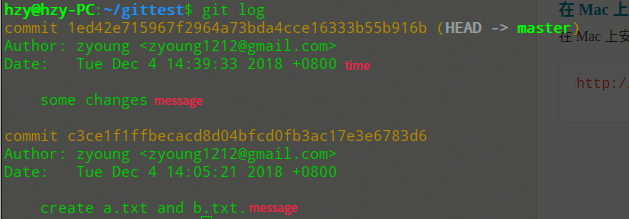
既然我们已经修改过文件了,那如何查看历史记录呢?
log命令即可按照时间降序来显示历史记录:
Git的协作功能
克隆版本库
为了模拟团队开发协作,我们另新建一个文件夹,代表第二位开发者在自己的PC上进行团队开发:

此时,gittest2中已经有一份和gittest项目一模一样的拷贝。
从另一版本库中获取修改
现在,我们假设开发者A对gittest项目进行了修改:
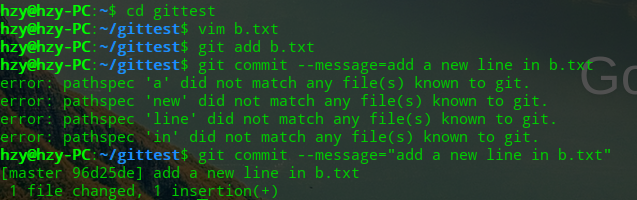
此时,开发者B也对项目进行了修改:

这样,两位开发者都在各自的PC上对项目进行了修改、提交。由于开发者B克隆的A的项目,因此B的项目中存储了原版本库的路径。接下来,我们使用pull命令将开发者B克隆的项目进行同步,取回最新的提交:
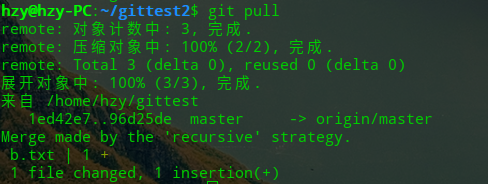
可以发现,开发者B的项目中的b.txt文件得到了同步,和A的一模一样了。这个过程中,B使用pull从原版本库中取回了新的修改,将它们与克隆体中的本地修改进行对比,然后在工作区中合并了两边的修改,创建了一次新的提交,这就叫合并(merge)。
从任意版本库中取回修改
在进行pull时,默认是从原版本库中进行获取。当指定参数时,便能实现从任意版本库中获取。
现在,我们将克隆体中的修改pull到原版本库:

创建共享版本库
push命令可以将提交传送给其他版本库。但是,push命令只适用于那些没有开发者在上面开展具体工作的版本库。最好是创建一个不带工作区的版本库,称为裸版本库(bare reppository)。

裸版本库就是充当开发者们传递提交的汇聚点,以便其他人可以从中拉回他们所做的修改。
用push命令上载修改
修改~/gittest/b.txt文件,然后进行提交,最后push操作:

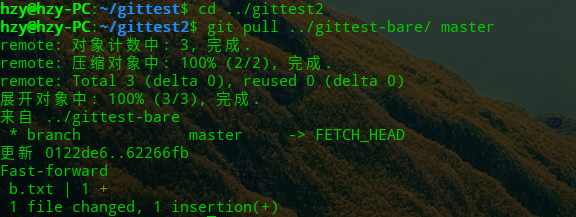
Pull命令:取回修改
现在,clone仓库也想获取相应的修改,执行以下命令即可:
《Git学习指南》学习笔记(一)的更多相关文章
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据技术之_16_Scala学习_01_Scala 语言概述
第一章 Scala 语言概述1.1 why is Scala 语言?1.2 Scala 语言诞生小故事1.3 Scala 和 Java 以及 jvm 的关系分析图1.4 Scala 语言的特点1.5 ...
- 大数据技术之_16_Scala学习_04_函数式编程-基础+面向对象编程-基础
第五章 函数式编程-基础5.1 函数式编程内容说明5.1.1 函数式编程内容5.1.2 函数式编程授课顺序5.2 函数式编程介绍5.2.1 几个概念的说明5.2.2 方法.函数.函数式编程和面向对象编 ...
随机推荐
- 【题解】洛谷P1074 [NOIP2009TG] 靶形数独(DFS+剪枝)
洛谷P1074:https://www.luogu.org/problemnew/show/P1074 思路 这道题一看就是DFS 打一个分数表方便后面算分 我用x y z数组分别表示行 列 宫 是否 ...
- Vue多个元素展开收起
html: <div class="helpPages_main"> <div class="read" v-for="(item, ...
- el表达式不显示值
1.场景是自己搭建一个ssm的项目,登录页面跳转到首页,首页显示登录用户的信息,用request传递的值,用el表达式在jsp页面中没有显示 2.解决办法 早jsp的代码中添加头<%@ page ...
- Oracle记录类型(record)和%rowtype
Oracle中的记录类型(record)和使用%rowtype定义的数据类型都是一种单行多列的数据结构,可以理解为一个具有多个属性的对象.其中属性名即为列名. 记录类型(record) 记录类型是一种 ...
- iOS:SQL
iOS虽然也有SQL,不过用得少(至少我目前是这样).大数据直接丢给后台,小的用Plist足矣. 再退一步,有FMDB,原生的也用得少了. 下面是之前学SQL时候的笔记. 1.创建 1-1).打开: ...
- 一站式学习Redis 从入门到高可用分布式实践
1:redis 是用c语言来实现的,速度快 持久化 单线程 复杂的数据类型有bitmap和hyperloglog和geo地理信息2:高可用.分布式 v2.8开始支持Redis-Sentinel(哨兵) ...
- CF1066D Boxes Packing(二分答案)
题意描述: 你有$n$个物品,每个物品大小为$a_i$,$m$个盒子,每个盒子的容积为$k$.$Maksim$先生想把物品装入盒子中.对于每个物品,如果能被放入当前的盒子中,则放入当前盒子,否则换一个 ...
- Linux 学习第五天
一.重定向.管道符.通配符 1.重定向.管道符使用 重定向: 命令文件 管道符: 命令A:命令B (管道符 | 别称 “任意门”) 二.常用命令 1.ls /etc | wc -l (查看目录 ...
- JS DOM 1
接触JS也有快一个月了,现在来总结一下看过的书,一本本总结,之后再融会贯通,也许更有助于学习.废话不多说,现在看的是<JavaScript DOM编程艺术>,该书挺薄的,不太会望而生畏,( ...
- 【Hadoop故障处理】在高可用(HA)配置下,8088端口无法访问,resourcemanager进程无法启动问题
[故障背景] 8088网页打不开,因8088是yarn平台的端口,所以我从yarn开始排查,首先到各个机器上使用jps命令查看yarn的各个节点是否启动,发现虽然有nodemanager进程,但是主节 ...