【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:【RL系列】Multi-Armed Bandit笔记
本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An Introduction 的课后习题。
第一题为Exercise 2.5 (programming),主要讨论了Recency-Weighted Average算法相较于Sample Average算法的优点所在。练习内容大致为比较这两种算法在收益分布为非平稳分布的情况下的表现情况,主要的评价指标依照Figure 2.2,也就是Average Reward和Optimal Action Rate两个。
先前我们在上一篇文章中讨论的所有情况都是假设收益分布为一个固定的不变的正态分布,比如N(1, 1),这里可以称其为平稳分布(Stationary Distribution)。那么如何制造一个非平稳分布呢?在练习中,已经给出了提示:在每一步的实验中,在实际收益均值上加一个服从标准差差为0.01,均值为0的正态分布的随机数即可,举个例子,N(1 + N(0, 0.01), 1)。那么在原先的Matlab程序中需要做出如下的修改:
% 10-Armed Bandit
K = 10;
AverReward = randn([1 K]);
% Reward for each Action per experiment
% Reward(Action) = normrnd(AverReward(Action) + normrnd(0, 0.01), 1);
学习过程的参数设定为epsilon = 0.1,最终step数设为10000:
第二题为Exercise 2.6,这个问题是关于初值优化的,主要讨论了初值优化后的OAR图像为何会在实验次数较少时出现突然的尖峰,这个问题也被称作Mysterious Spike:
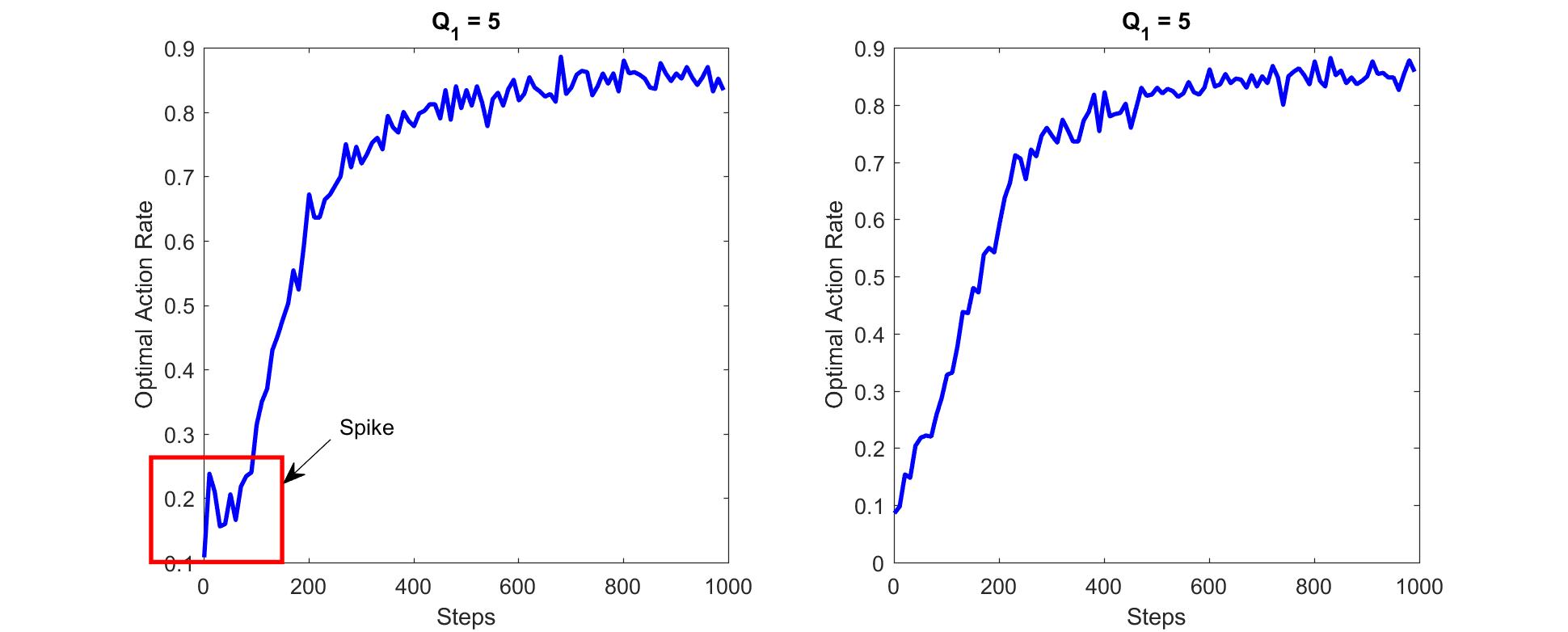
假设我们将初值Q1设为5,最终step数设为1000,epsilon = 0。可以发现左图的greedy策略是直接求解Q值中的最大值所对应的动作,如下将其转化为Matlab
[MAX i] = max(Q);
if(rand(1) < 1 - epsilon)
CurrentA = i;
else
CurrentA = unidrnd(RandK);
end
而右图也同样是将初值设为5,但并未出现Spike现象,给出右图的greedy选择策略:
[MAX i] = max(Q);
if(MAX ~= 5 & rand(1) < 1 - epsilon)
CurrentA = i;
else
CurrentA = unidrnd(RandK);
end
出现Spike现象的原因其实很简单,如果一向量或序列存在两个或两个以上相同的最大值时,计算机在计算最值所在位置的返回值一定是第一个最大值的位置。举个例子(Matlab)
x = [1 2 5 5 5 1]
[MAX n] = max(x); >> MAX = 5
>> n = 3
这个例子中一定不会出现n = 4或n= 5,这就造成了一个问题,我们总是会在有限的步数内不断的去逼近那个真实的收益均值最大值所在的位置。那么在计算Optimal Action Rate时,我们可以举个例子,假设现在是10-Armed Bandit问题,而step数只有不到十次,我们就只看5次的情况吧,假设我们的真实收益最大均值就在向量的第五个位置。
N = 7
K = 10
Reward = [1 2 3 4 5 4.5 3.5 2.5 1.5 0.5];
[MAX i] = max(Reward);
>> MAX = 5
>> i = 5 Q = zeros(1, K) + 5; % First step
[MAXQ i] = max(Q);
>> i = 1
>> Q = [4.6 5 5 5 5 5 5 5 5 5]
>> OAR = 0 % Second step
[MAXQ i] = max(Q);
>> i = 2
>> Q = [4.6 4.7 5 5 5 5 5 5 5 5]
>> OAR = 0 ..... % 5th step
[MAX i] = max(Q);
>> i = 5
>> Q = [4.6 4.7 4.8 4.9 5 5 5 5 5 5]
>> OAR = 0.2
%Notice that here's a Spike!
所以依据上面的推断,我们可以推测出,Spike的发生大概率出现在K次实验内(K为K-Armed中的K),而且Spike的最高值取决于真实的收益均值所在的位置与K值之比,假设其所在位置为第M位,则Spike的值可以估计为M/K。当实验次数大于K时,OAR则会从1/K开始逐步增加。
【RL系列】Multi-Armed Bandit笔记补充(一)的更多相关文章
- 【RL系列】Multi-Armed Bandit笔记补充(二)
本篇的主题是对Upper Conference Bound(UCB)策略进行一个理论上的解释补充,主要探讨UCB方法的由来与相关公式的推导. UCB是一种动作选择策略,主要用来解决epsilon-gr ...
- 【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Int ...
- 【RL系列】Multi-Armed Bandit问题笔记
这是我学习Reinforcement Learning的一篇记录总结,参考了这本介绍RL比较经典的Reinforcement Learning: An Introduction (Drfit) .这本 ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- (zhuan) 一些RL的文献(及笔记)
一些RL的文献(及笔记) copy from: https://zhuanlan.zhihu.com/p/25770890 Introductions Introduction to reinfor ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- STM32 FSMC学习笔记+补充(LCD的FSMC配置)
STM32 FSMC学习笔记+补充(LCD的FSMC配置) STM32 FSMC学习笔记 STM32 FSMC的用法--LCD
- Vue双向绑定的实现原理系列(四):补充指令解析器compile
补充指令解析器compile github源码 补充下HTML节点类型的知识: 元素节点 Node.ELEMENT_NODE(1) 属性节点 Node.ATTRIBUTE_NODE(2) 文本节点 N ...
随机推荐
- 【2017001】IList转DataTable、DataTable转IList
IList转DataTable.DataTable转IList using System; using System.Collections.Generic; using System.Compone ...
- C++笔记008:C++对C的扩展——命名空间 namespace基础
原创笔记,转载请注明出处! 点击[关注],关注也是一种美德~ 第一, 命名空间的意义 命名空间是ANSIC++引入的可以由用户命名的作用域,用来处理程序中常见的同名冲突. 我认识两位叫“A”的朋友,一 ...
- acm--1004
问题描述 再次比赛时间!看到气球在四周漂浮,多么兴奋.但要告诉你一个秘密,评委最喜欢的时间是猜测最流行的问题.比赛结束后,他们会统计每种颜色的气球并找出结果. 今年,他们决定离开这个可爱的工作给你. ...
- hdu 1394 Minimum Inversion Number(逆序数对) : 树状数组 O(nlogn)
http://acm.hdu.edu.cn/showproblem.php?pid=1394 //hdu 题目 Problem Description The inversion number ...
- What is a schema in a MySQL database?
摘自:https://www.quora.com/What-is-a-schema-in-a-MySQL-database What is schema? In MySQL, physically, ...
- Win10英文系统 JDK1.8安装及环境变量配置
前提 今天换新电脑了,需要重新安装一遍JDK.写个随笔记录一下整个过程. 下载 官网上JDK已经出到10了,但是回忆起JDK9都有各种坑(不支持一些软件),决定还是用JDK8. 下载地址: http: ...
- 配置SpringBoot方便的切换jar和war
配置SpringBoot方便的切换jar和war 网上关于如何切换,其实说的很明确,本文主要通过profile进行快速切换已实现在不同场合下,用不同的打包方式. jar到war修改步骤 pom文件修改 ...
- Flask之Flask实例有哪些参数
常用的参数应用实例 from flask import Flask, render_template, url_for, session, request, redirect app = Flask( ...
- thinkphp中的大字母的意思
ThinkPHP 单字母函数 A() 内部实例化控制器 D() 实例化自定义模型类 M() 实例化一个基础模型类 R() 调用某个控制器的操作方法 L() 启用多语言的情况下,设置和获取当前的语言定义 ...
- ASA 5.0/8.0/9.0 杂记
ASA 10.0 之前的版本都是使用odbc方式连接,由于某个项目的需求,无奈学习一下这些老掉牙的技巧. 1.新建 数据源 (不会的话,自行搜索一下) 2.使用 快捷方式 或者 其他方式 执行 C:\ ...