Linux Kernel文件系统写I/O流程代码分析(二)bdi_writeback
Linux Kernel文件系统写I/O流程代码分析(二)bdi_writeback
上一篇# Linux Kernel文件系统写I/O流程代码分析(一),我们看到Buffered IO,写操作写入到page cache后就直接返回了,本文主要分析脏页是如何刷盘的。
概述
由于内核page cache的作用,写操作实际被延迟写入。当page cache里的数据被用户写入但是没有刷新到磁盘时,则该page为脏页(块设备page cache机制因为以前机械磁盘以扇区为单位读写,引入了buffer_head,每个4K的page进一步划分成8个buffer,通过buffer_head管理,因此可能只设置了部分buffer head为脏)。
脏页在以下情况下将被回写(write back)到磁盘上:
- 脏页在内存里的时间超过了阈值。
- 系统的内存紧张,低于某个阈值时,必须将所有脏页回写。
- 用户强制要求刷盘,如调用sync()、fsync()、close()等系统调用。
以前的Linux通过pbflush机制管理脏页的回写,但因为其管理了所有的磁盘的page/buffer_head,存在严重的性能瓶颈,因此从Linux 2.6.32开始,脏页回写的工作由bdi_writeback机制负责。bdi_writeback机制为每个磁盘都创建一个线程,专门负责这个磁盘的page cache或者
buffer cache的数据刷新工作,以提高I/O性能。
BDI系统
BDI是backing device info的缩写,它用于描述后端存储(如磁盘)设备相关的信息。相对于内存来说,后端存储的I/O比较慢,因此写盘操作需要通过page cache进行缓存延迟写入。
最初的BDI子系统里,模块启动的时候创建bdi-default进程,然后为每个注册的设备创建flush-x:y(x,y为主次设备号)的进程,用于脏数据的回写。在Linux 3.10.0版本之后,BDI子系统使用workqueue机制代替原来的线程创建,需要回写时,将flush任务提交给workqueue,最终由通用的[kworker]进程负责处理。BDI子系统初始化的代码如下:
static int __init default_bdi_init(void)
{
int err;
bdi_wq = alloc_workqueue("writeback", WQ_MEM_RECLAIM | WQ_FREEZABLE |
WQ_UNBOUND | WQ_SYSFS, 0);
if (!bdi_wq)
return -ENOMEM;
err = bdi_init(&default_backing_dev_info);
if (!err)
bdi_register(&default_backing_dev_info, NULL, "default");
err = bdi_init(&noop_backing_dev_info);
return err;
}
subsys_initcall(default_bdi_init);
设备注册
当执行mount流程时,底层文件系统定义自己的struct backing_dev_info结构并将其注册到BDI子系统,如下是FUSE代码示例:
static int fuse_bdi_init(struct fuse_conn *fc, struct super_block *sb)
{
int err;
fc->bdi.name = "fuse";
fc->bdi.ra_pages = (VM_MAX_READAHEAD * 1024) / PAGE_CACHE_SIZE;
/* fuse does it's own writeback accounting */
fc->bdi.capabilities = BDI_CAP_NO_ACCT_WB | BDI_CAP_STRICTLIMIT;
err = bdi_init(&fc->bdi);
if (err)
return err;
fc->bdi_initialized = 1;
if (sb->s_bdev) {
err = bdi_register(&fc->bdi, NULL, "%u:%u-fuseblk",
MAJOR(fc->dev), MINOR(fc->dev));
} else {
err = bdi_register_dev(&fc->bdi, fc->dev);
}
if (err)
return err;
/*
* /sys/class/bdi/<bdi>/max_ratio
*/
bdi_set_max_ratio(&fc->bdi, 1);
return 0;
}
该函数先通过bdi_init()初始化struct backing_dev_info,然后通过bid_register()将其注册到BDI子系统。
其中bdi_init()会调用bdi_wb_init()初始化struct bdi_writeback:
static void bdi_wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi)
{
memset(wb, 0, sizeof(*wb));
wb->bdi = bdi;
wb->last_old_flush = jiffies;
INIT_LIST_HEAD(&wb->b_dirty);
INIT_LIST_HEAD(&wb->b_io);
INIT_LIST_HEAD(&wb->b_more_io);
spin_lock_init(&wb->list_lock);
INIT_DELAYED_WORK(&wb->dwork, bdi_writeback_workfn);
}
其中初始化了一个默认处理函数为bdi_writeback_workfn的work,用于回写处理。
数据回写
在上一篇的基础上,将图补充了bdi回写的部分,如下所示:
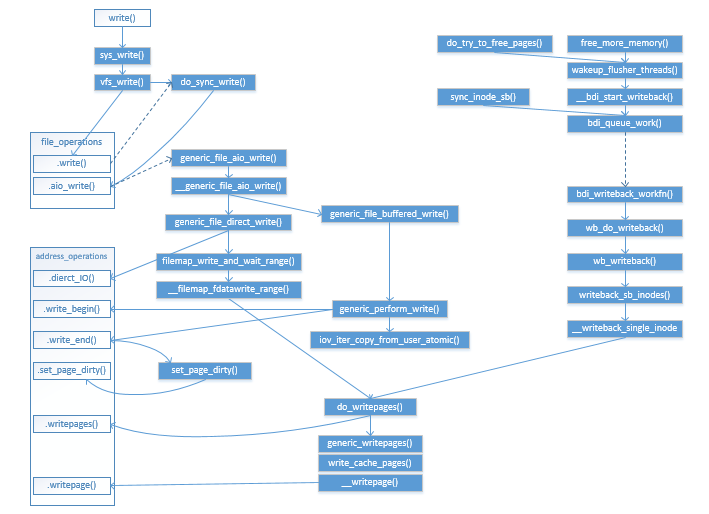
bdi_queue_work
BDI子系统使用workqueue机制进行数据回写,其回写接口为bdi_queue_work()将具体某个bdi的回写请求(wb_writeback_work)挂到bdi_wq上。代码如下:
static void bdi_queue_work(struct backing_dev_info *bdi,
struct wb_writeback_work *work)
{
trace_writeback_queue(bdi, work);
spin_lock_bh(&bdi->wb_lock);
if (!test_bit(BDI_registered, &bdi->state)) {
if (work->done)
complete(work->done);
goto out_unlock;
}
list_add_tail(&work->list, &bdi->work_list);
mod_delayed_work(bdi_wq, &bdi->wb.dwork, 0);
out_unlock:
spin_unlock_bh(&bdi->wb_lock);
}
调用该函数的地方包括:
- sync_inode_sb(): 将该super block上所有的脏inode回写。
- writeback_inodes_sb_nr():回写super block上指定个数脏inode。
- __bdi_start_writeback():定时调用或者需要释放pages或者需要更多内存时调用。
bdi_writeback_workfn
bdi_queue_work()提交了work给bdi_wq上,由对应的bdi处理函数进行处理,默认的函数为bdi_writeback_workfn,其代码如下:
void bdi_writeback_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = container_of(to_delayed_work(work),
struct bdi_writeback, dwork);
struct backing_dev_info *bdi = wb->bdi;
long pages_written;
set_worker_desc("flush-%s", dev_name(bdi->dev));
current->flags |= PF_SWAPWRITE;
if (likely(!current_is_workqueue_rescuer() ||
!test_bit(BDI_registered, &bdi->state))) {
/*
* The normal path. Keep writing back @bdi until its
* work_list is empty. Note that this path is also taken
* if @bdi is shutting down even when we're running off the
* rescuer as work_list needs to be drained.
*/
do {
pages_written = wb_do_writeback(wb);
trace_writeback_pages_written(pages_written);
} while (!list_empty(&bdi->work_list));
} else {
/*
* bdi_wq can't get enough workers and we're running off
* the emergency worker. Don't hog it. Hopefully, 1024 is
* enough for efficient IO.
*/
pages_written = writeback_inodes_wb(&bdi->wb, 1024,
WB_REASON_FORKER_THREAD);
trace_writeback_pages_written(pages_written);
}
if (!list_empty(&bdi->work_list))
mod_delayed_work(bdi_wq, &wb->dwork, 0);
else if (wb_has_dirty_io(wb) && dirty_writeback_interval)
bdi_wakeup_thread_delayed(bdi);
current->flags &= ~PF_SWAPWRITE;
}
首先判断当前workqueue能否获得足够的worker进行处理,如果能则将bdi上所有work全部提交,否则只提交一个work并限制写入1024个pages。
正常情况下通过调用wb_do_writeback函数处理回写。
wb_do_writeback
该函数代码如下,遍历bdi上所有work,通过调用wb_writeback()进行数据写入。
static long wb_do_writeback(struct bdi_writeback *wb)
{
struct backing_dev_info *bdi = wb->bdi;
struct wb_writeback_work *work;
long wrote = 0;
set_bit(BDI_writeback_running, &wb->bdi->state);
while ((work = get_next_work_item(bdi)) != NULL) {
trace_writeback_exec(bdi, work);
wrote += wb_writeback(wb, work);
/*
* Notify the caller of completion if this is a synchronous
* work item, otherwise just free it.
*/
if (work->done)
complete(work->done);
else
kfree(work);
}
/*
* Check for periodic writeback, kupdated() style
*/
wrote += wb_check_old_data_flush(wb);
wrote += wb_check_background_flush(wb);
clear_bit(BDI_writeback_running, &wb->bdi->state);
return wrote;
}
wb_writeback()函数最终调用__writeback_single_inode()将某个inode上脏页刷回。
__writeback_single_inode
__writeback_single_inode()的代码如下,最终通过调用do_writepages()函数写盘:
static int
__writeback_single_inode(struct inode *inode, struct writeback_control *wbc)
{
struct address_space *mapping = inode->i_mapping;
long nr_to_write = wbc->nr_to_write;
unsigned dirty;
int ret;
WARN_ON(!(inode->i_state & I_SYNC));
trace_writeback_single_inode_start(inode, wbc, nr_to_write);
ret = do_writepages(mapping, wbc);
/*
* Make sure to wait on the data before writing out the metadata.
* This is important for filesystems that modify metadata on data
* I/O completion. We don't do it for sync(2) writeback because it has a
* separate, external IO completion path and ->sync_fs for guaranteeing
* inode metadata is written back correctly.
*/
if (wbc->sync_mode == WB_SYNC_ALL && !wbc->for_sync) {
int err = filemap_fdatawait(mapping);
if (ret == 0)
ret = err;
}
/*
* Some filesystems may redirty the inode during the writeback
* due to delalloc, clear dirty metadata flags right before
* write_inode()
*/
spin_lock(&inode->i_lock);
/* Clear I_DIRTY_PAGES if we've written out all dirty pages */
if (!mapping_tagged(mapping, PAGECACHE_TAG_DIRTY))
inode->i_state &= ~I_DIRTY_PAGES;
dirty = inode->i_state & I_DIRTY;
inode->i_state &= ~(I_DIRTY_SYNC | I_DIRTY_DATASYNC);
spin_unlock(&inode->i_lock);
/* Don't write the inode if only I_DIRTY_PAGES was set */
if (dirty & (I_DIRTY_SYNC | I_DIRTY_DATASYNC)) {
int err = write_inode(inode, wbc);
if (ret == 0)
ret = err;
}
trace_writeback_single_inode(inode, wbc, nr_to_write);
return ret;
}
do_writepages
函数do_writepages()在上一篇已经介绍过了,它负责调用底层文件系统的a_ops->writepages将pages写入后端存储。
Linux Kernel文件系统写I/O流程代码分析(二)bdi_writeback的更多相关文章
- Linux Kernel文件系统写I/O流程代码分析(一)
Linux Kernel文件系统写I/O流程代码分析(一) 在Linux VFS机制简析(二)这篇博客上介绍了struct address_space_operations里底层文件系统需要实现的操作 ...
- arm linux kernel 从入口到start_kernel 的代码分析
参考资料: <ARM体系结构与编程> <嵌入式Linux应用开发完全手册> Linux_Memory_Address_Mapping http://www.chinaunix. ...
- Linux内核启动代码分析二之开发板相关驱动程序加载分析
Linux内核启动代码分析二之开发板相关驱动程序加载分析 1 从linux开始启动的函数start_kernel开始分析,该函数位于linux-2.6.22/init/main.c start_ke ...
- Ecshop的购物流程代码分析详细说明
Ecshop的购物流程代码分析详细说明 (2012-07-30 10:41:12) 转载▼ 标签: 购物车 结算中心 商品价格 ecshop ecshop购物流程 杂谈 分类: ECSHOP研究院 同 ...
- Openfire注册流程代码分析
Openfire注册流程代码分析 一.客户端/服务端注册用户流程 经过主机连接消息确认后,客户端共发送俩条XML完成注册过程.服务器返回两条XML. 注:IQ消息节点用于处理用户的注册.好友.分组.获 ...
- Android4.0图库Gallery2代码分析(二) 数据管理和数据加载
Android4.0图库Gallery2代码分析(二) 数据管理和数据加载 2012-09-07 11:19 8152人阅读 评论(12) 收藏 举报 代码分析android相册优化工作 Androi ...
- 《linux 内核全然剖析》 fork.c 代码分析笔记
fork.c 代码分析笔记 verifiy_area long last_pid=0; //全局变量,用来记录眼下最大的pid数值 void verify_area(void * addr,int s ...
- 《linux 内核全然剖析》 sys.c 代码分析
sys.c 代码分析 setregid /* * This is done BSD-style, with no consideration of the saved gid, except * th ...
- SQL注入原理及代码分析(二)
前言 上一篇文章中,对union注入.报错注入.布尔盲注等进行了分析,接下来这篇文章,会对堆叠注入.宽字节注入.cookie注入等进行分析.第一篇文章地址:SQL注入原理及代码分析(一) 如果想要了解 ...
随机推荐
- 项目前端打包工具从 NEJ 切换成 webpack
此文已由作者张磊授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 这里不讨论 NEJ 和 webpack 的优劣,仅从技术角度来探寻一下能否实现,以及实现的代价. 前言 上一篇 ...
- c++分块算法(暴力数据结构)
快要noip了,该写些题解攒攒rp了(逃) 看到题解里那么多线段树啊,树状数组啊,本蒟蒻表示:这都是什么鬼东西? 在所有高级数据结构中,树状数组是码量最小的,跑的也基本是最快的,但理解很难,并且支持的 ...
- python index()函数
python内置index()函数 index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python ...
- Echart自定义y轴刻度信息2
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- API自动化测试 Soap UI工具介绍
一. 建立测试用例 (一) 基本概念 soapUI 中工程的层次结构 项目名称:位于最上层 (BookStoreTest),项目可以包含多个服务的定义. REST 服务定义:服务其实是对多个 ...
- HTTP请求的两种方式get和post的区别
1,get从服务器获取数据:post向服务器发送数据: 2,安全性,get请求的数据会显示在地址栏中,post请求的数据放在http协议的消息体: 3,从提交数据的大小看,http协议本身没有限制数据 ...
- ios 字符串处理:截取字符串、匹配字符串、分隔字符串
1.截取字符串 NSString*string =@"sdfsfsfsAdfsdf";string = [string substringToIndex:7];//截取掉下标7之后 ...
- heap与stack的区别
java 的内存分为两类,一类是栈内存,一类是堆内存.栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这 ...
- leetcode-771-Jewels and Stones(建立哈希表,降低时间复杂度)
题目描述: You're given strings J representing the types of stones that are jewels, and S representing th ...
- flask实战-个人博客-使用类组织配置
使用类组织配置 在实际需求中,我们往往需要不同的配置组合.例如,开发用的配置,测试用的配置,生产环境用的配置.为了能方便地在这些配置中切换,你可以把配置文件升级为包,然后为这些使用场景分别创建不同的配 ...