Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用
- lxml:python 的HTML/XML的解析器
- 官网文档:https://lxml.de/
- 使用前,需要安装安 lxml 包
- 功能:
- 1.解析HTML:使用 etree.HTML(text) 将字符串格式的 html 片段解析成 html 文档
- 2.读取xml文件
- 3.etree和XPath 配合使用
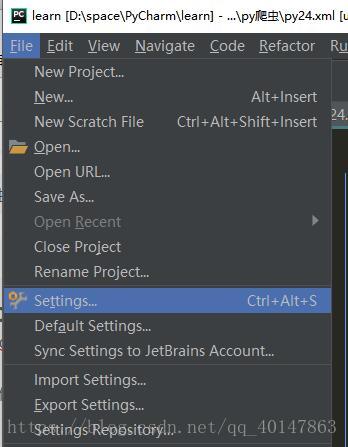
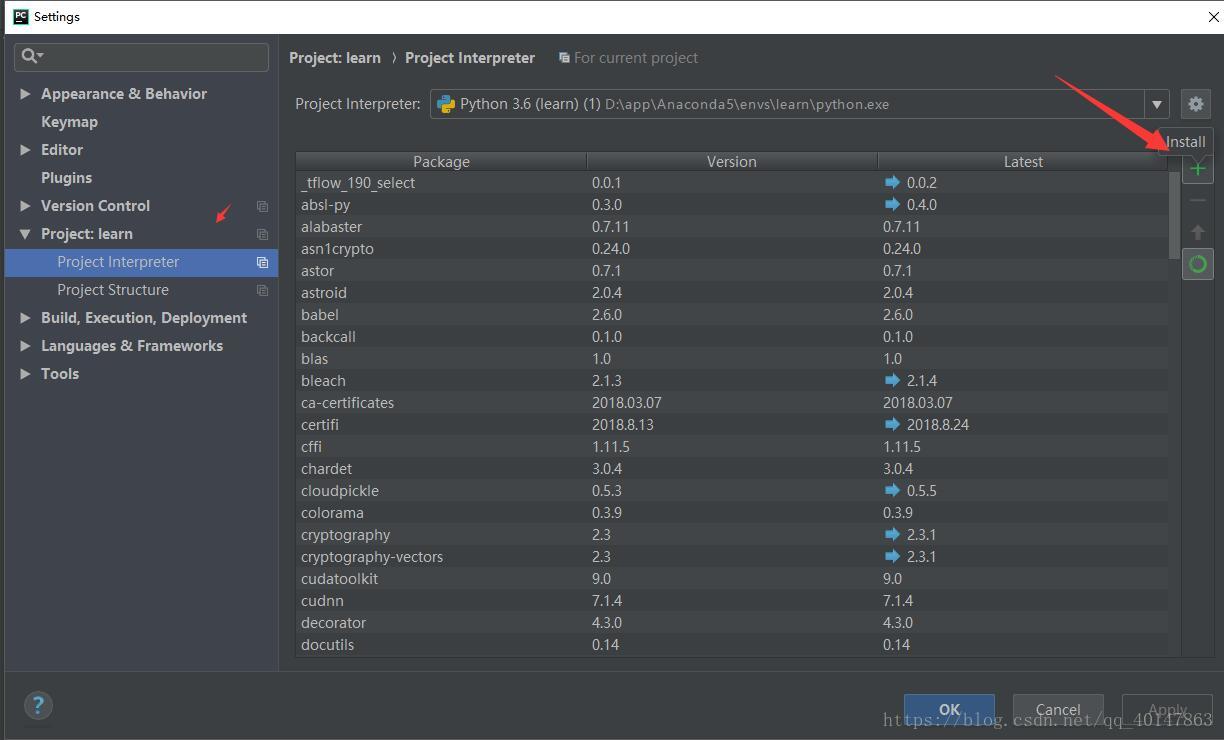
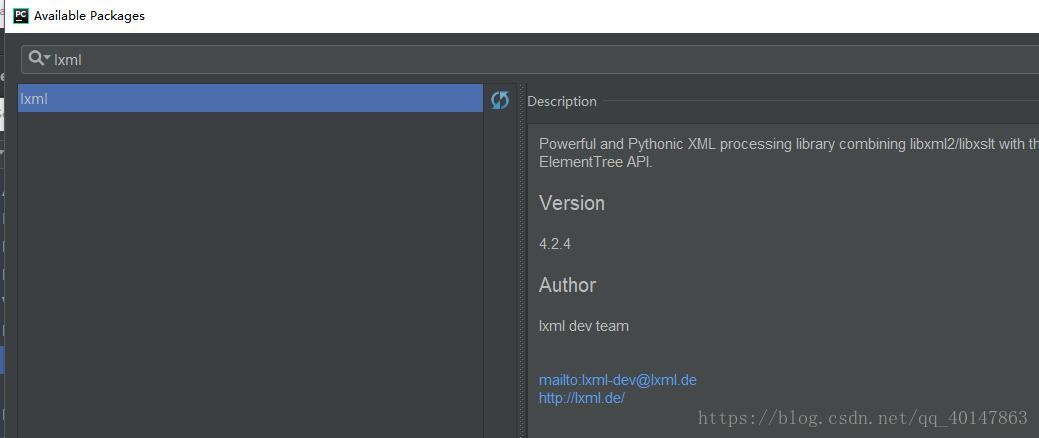
lxml 的安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【lxml】>【install】
- 具体操作截图:
lxml-etree 的使用
- 案例v25文件:https://xpwi.github.io/py/py爬虫/py25etree.py
- 用 lxml 来解析HTML代码
# 先安装lxml
# 用 lxml 来解析HTML代码
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="0.html">item 0 </a></li>
<li class="item-1"><a href="1.html">item 1 </a></li>
<li class="item-2"><a href="2.html">item 2 </a></li>
<li class="item-3"><a href="3.html">item 3 </a></li>
<li class="item-4"><a href="4.html">item 4 </a></li>
<li class="item-5"><a href="5.html">item 5 </a></li>
</ul>
</div>
'''
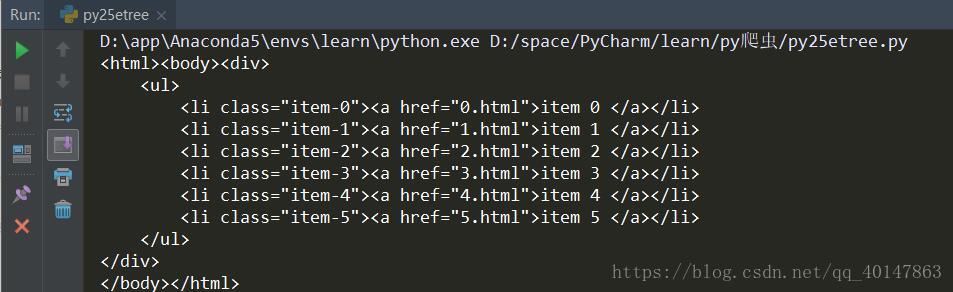
# 利用 etree.HTML 把字符串解析成 HTML 文件
html = etree.HTML(text)
s = etree.tostring(html).decode()
print(s)
运行结果
lxml-etree 的使用
- 案例v26etree2文件:https://xpwi.github.io/py/py爬虫/py26etree2.py
- 读取xml文件:
# lxml-etree读取文件
from lxml import etree
xml = etree.parse("./py24.xml")
sxml = etree.tostring(xml, pretty_print=True)
print(sxml)
运行结果

etree和XPath 配合使用
- 案例v26expath.文件:https://xpwi.github.io/py/py爬虫/py26expath.py
- etree和XPath 配合使用:
# lxml-etree读取文件
from lxml import etree
xml = etree.parse("./py24.xml")
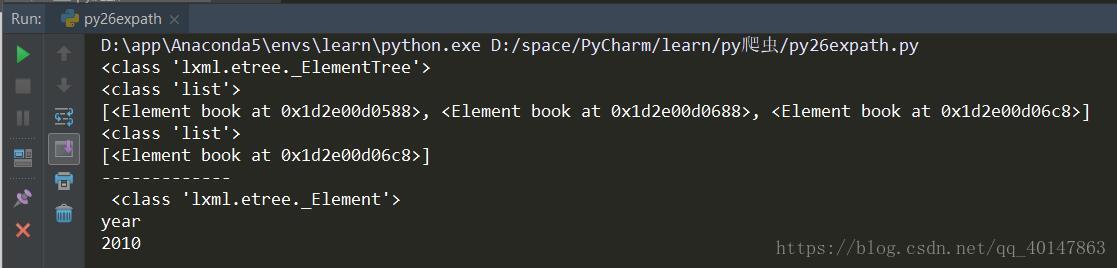
print(type(xml))
# 查找所有 book 节点
rst = xml.xpath('//book')
print(type(rst))
print(rst)
# 查找带有 category 属性值为 sport 的元素
rst2 = xml.xpath('//book[@category="sport"]')
print(type(rst2))
print(rst2)
# 查找带有category属性值为sport的元素的book元素下到的year元素
rst3 = xml.xpath('//book[@category="sport"]/year')
rst3 = rst3[0]
print('-------------\n',type(rst3))
print(rst3.tag)
print(rst3.text)
运行结果
etree和XPath 配合使用结果
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-22-lxml-etree和xpath配合使用的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python爬虫教程-21-xpath
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 Python爬虫教程-21-xpath 什么是 XPath? XPa ...
随机推荐
- js获取窗口宽度、高度
1.获取屏幕的高度和宽度(屏幕分辨率): window.screen.height window.screen.width 2.获取屏幕工作区域的高度和宽度(去掉状态栏): window.screen ...
- python __getattribute__、__getattr__、__setattr__详解
__getattribute__ 官方文档中描述如下: 该方法可以拦截对对象属性的所有访问企图,当属性被访问时,自动调用该方法(只适用于新式类).因此常用于实现一些访问某属性时执行一段代码的特性. 需 ...
- oracle模糊查询提高效率的方法
转载:https://blog.csdn.net/weixiaohuai/article/details/83513957 https://blog.csdn.net/chihen/article/d ...
- VS2010,VS2012,VS2015等的自动提示不能默认选中的功能解决办法
很简单,只需要按 ctrl+alt+space 即可切换. 蛋疼,我到底为什么总会不小心切换过去,而且每次都记不住这个快捷键切换回来...
- DataTable对象
DataTable表示一个内存中的关系数据表,可以独立创建和使用,也可以有其他.NET Framework对象使用,最常见的情况是作为DataSet的成员使用.DataTable对象由DataColu ...
- sencha touch list infinite 属性
sencha touch list 1 默认每一项的高度会自动适应其内容. 2 当每一个 item 的高度都相同且不变时, 设置 itemHeight 为固定值 和 variableHeights 为 ...
- jQuery validate 设置失去焦点就校验
<script type="text/javascript"> $(function(){ var flag = $("#addForm").val ...
- 009-MailUtils工具类模板
版本一:JavaMail的一个工具类 package ${enclosing_package}; import java.security.GeneralSecurityException; impo ...
- clojure学习笔记(一)
下载地址 需要安装xmind打开 http://pan.baidu.com/s/1dDxKj1B
- Windows命令计算MD5与SHA1/256值
certutil -hashfile file MD5 certutil -hashfile file SHA1 certutil -hashfile file SHA256 示例如下: