10-hdfs-hdfs搭建
hdfs的优缺点比较:


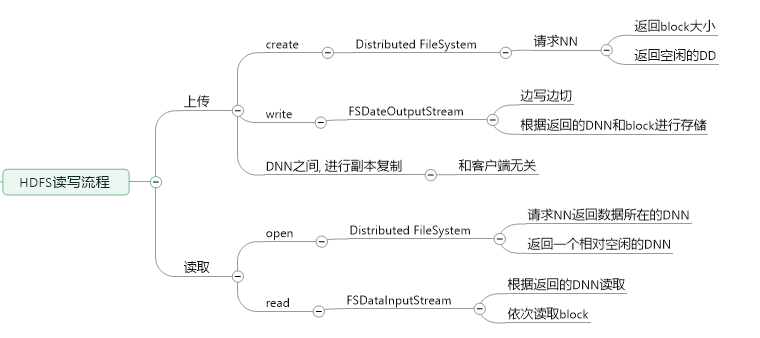
架构图解分析:
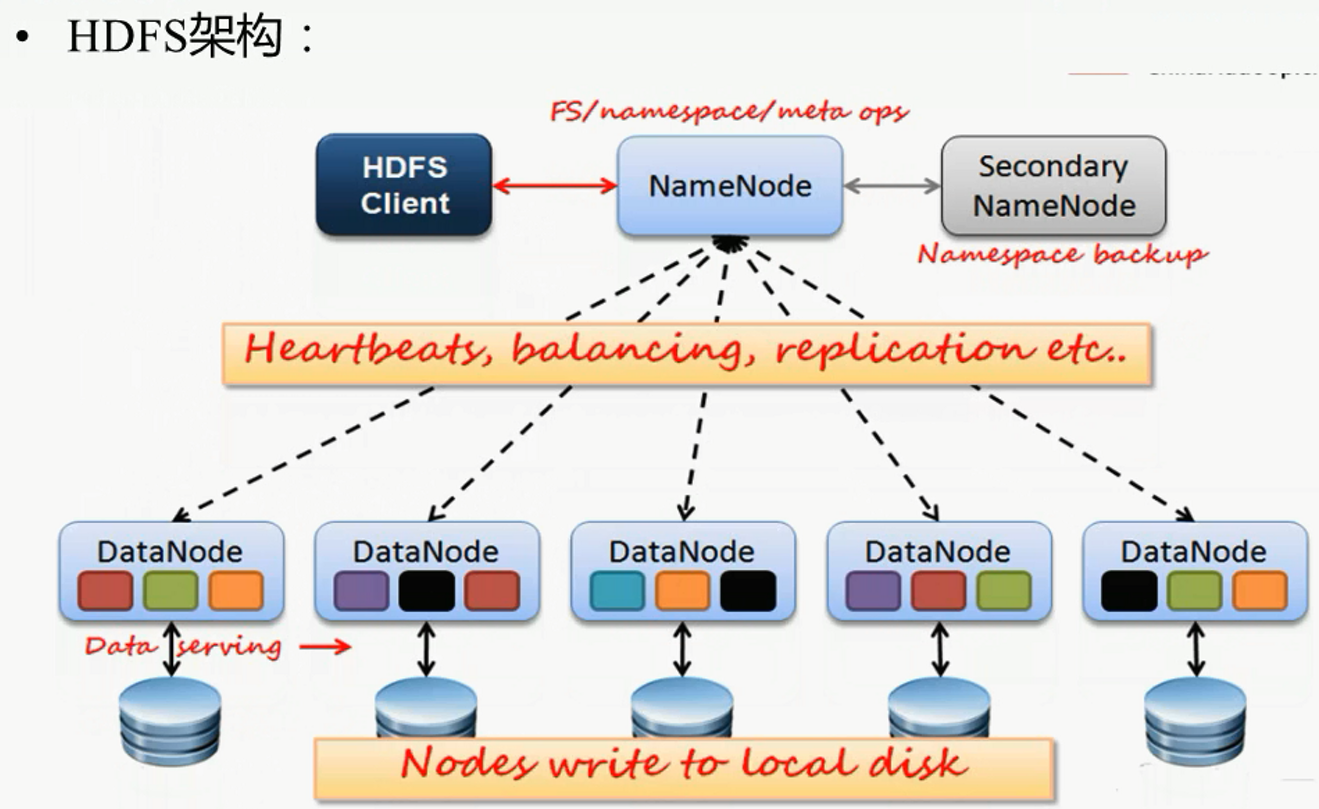
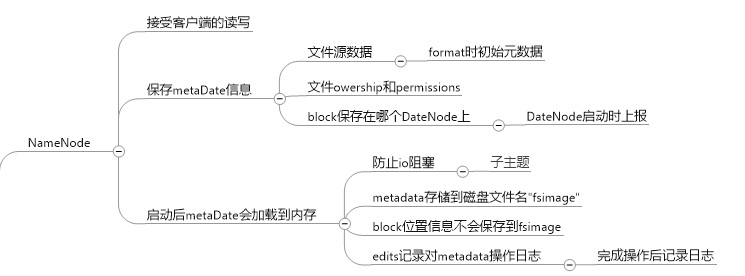
nameNode的主要任务:
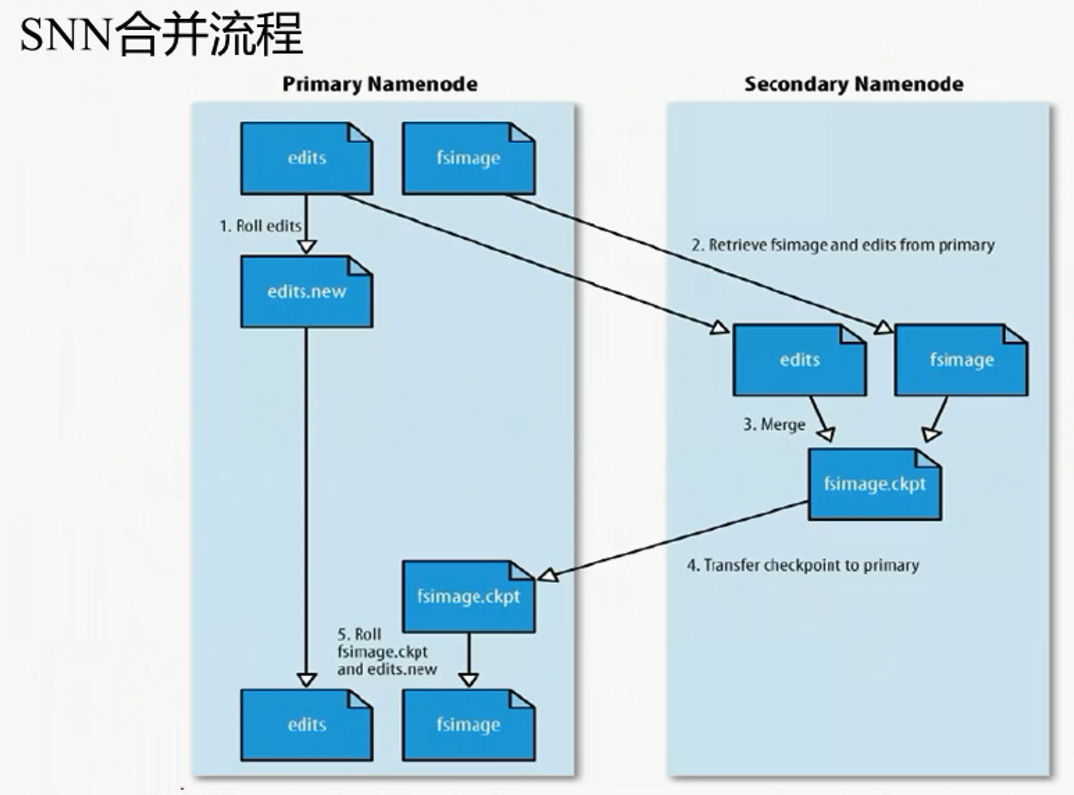
SNameNode的功能: (不是NN的备份, 主要用来合并fsimage)

合并流程:
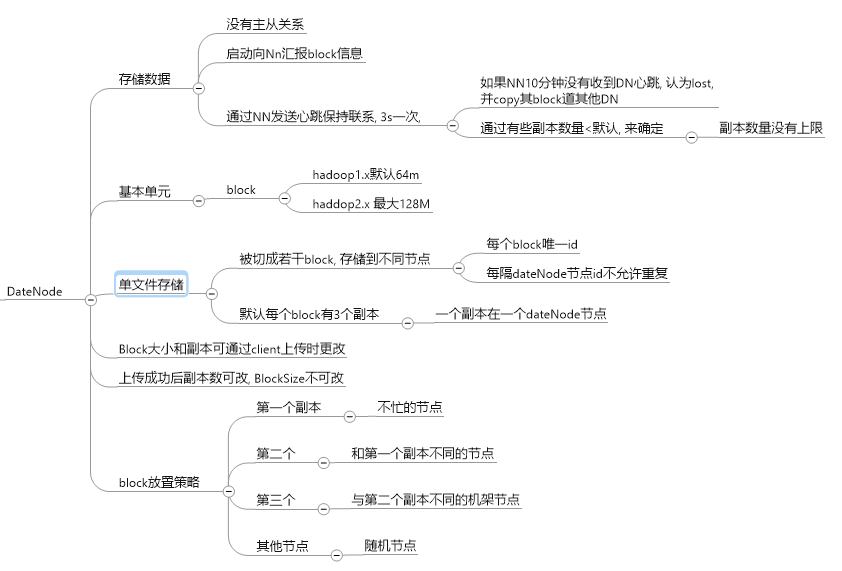
dataNode的主要功能:
HDFS上传文件思想:
hdfs用于一般用于处理离线数据文件, 存储方式为block副本, 集群规划使用完全式分部安装
一台作为NameNode, 3台为DataNode, 其中hdfs-dnn1 为SecondNameNode:
NameNode: 192.168.208.106 wenbronk.hdfs.com
DataNode: 192.168.208.107 hdfs-dnn1
DataNode: 192.168.208.108 hdfs-dnn2
DataNode: 192.168.208.109 hdfs-dnn3
1, 为了方便NameNode直接启动DataNode, 不输入密码, 使用ssh的免密登录
注意: 1. .ssh目录权限必须是700
2 . .ssh/authorized_keys 文件权限必须是600
(nameNode需要远程登陆Dnn中进行开启DNN), 不设置的话每次输入密码
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
生成的公钥和私钥文件在 /root/.ssh 下
将 自己 设置为免密码登录, 将生成的pub文件追加到认证文件下
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys将 NN的公钥放置到DNN中去, (详细可见 ssh 免密码登录 原理)
scp ~/.ssh/id_rsa.pub root@hdfs-dnn1:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_rsa.pub root@hdfs-dnn2:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_dsa.pub root@hdfs-dnn3:/opt/ssh
cat /opt/ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2, 配置4台机器的jdk为1.7版本的, (使用hadoop2.x)
配置好一台机器后, 使用scp拷贝
scp -r jdk1..0_79/ root@hdfs-dnn1:/usr/opt/
scp -r jdk1.7.0_79/ root@hdfs-dnn3:/usr/opt/
之后, source /etc/profile
3, 上传解压hadoop.2.5.1_x64.tar.gz
使用rz上传
使用tar -zxvf had.. 解压
4, 修改配置文件
cd hadoop.2.5./etc/hadoop
hadoop-env.sh
export JAVA_HOME=/usr/opt/jdk1..0_79/
core-site.xml, 配置NN所在的主机和数据传输端口(rpc协议)
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.208.126:9000</value>
</property>
<!--配置缓存目录, 因为fsimage默认在此目录下, 所以更改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
hdfs-site.xml, 配置的为secondNameNode
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdfs-dnn:</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>hdfs-dnn:</value>
</property>
slaves
hdfs-dnn1
hdfs-dnn2
hdfs-dnn3
masters 自己创建, 配置SNN的主机名
hdfs-dnn1
之后, 将整个hadoop文件scp到DNN主机上
5, 配置hadoop的环境变量 /etc/profile
export JAVA_HOME=/usr/opt/jdk1..0_79
export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/usr/opt/hadoop-2.5.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6, 启动
6.1) 格式化NN, 在 HADOOP_HOME/dfs/name/current/ 下生成fsimage文件
hdfs namenode -format
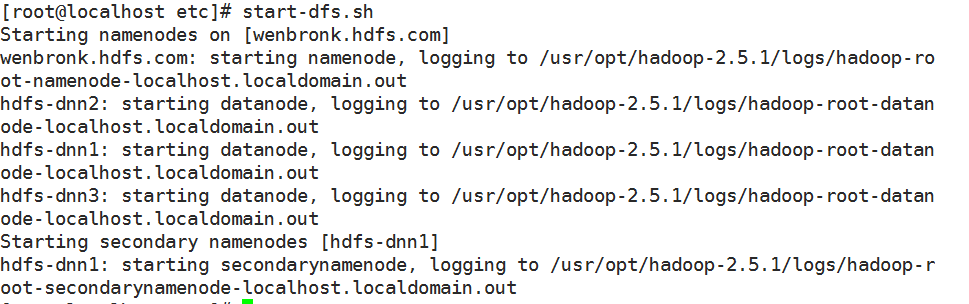
6.2) 启动
start-dfs.sh
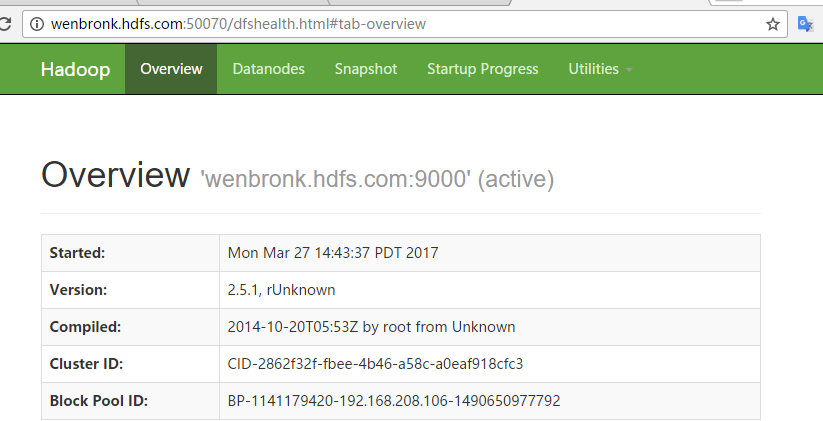
然后通过浏览器可以访问监控页面,
命令行示例:
1) 从本地磁盘拷贝文件
hdfs dfs -put foo.txt foo.txt
hdfs 没有当前目录的概念, 必须从用户的home路径下, /usr/username/foot.txt # 从hdfs拷贝
hdfs dfs -get /user/fred/bar.txt baz.txt
2) 获取用户home目录列表
hdfs dfs -ls
访问根目录, 直接 /
3) 显示hdfs文件 /user/fred/bar.txt
hdfs dfs -cat /user/fred/bar.txt
4), 在用户目录下创建input目录
hdfs dfs -mkdir input
5) , 删除目录
hdfs dfs -rm -r input-old
系列来自尚学堂
10-hdfs-hdfs搭建的更多相关文章
- 10分钟学会搭建Android开发环境 Eclipse: The import android.support cannot be resolved
10分钟学会搭建Android开发环境_隋雨辰 http://v.youku.com/v_show/id_XNTE2OTI5Njg0.html?from=s1.8-1-1.2 The import a ...
- DELPHI 10.2 TOKYO搭建LINUX MYSQL开发环境
DELPHI 10.2 TOKYO搭建LINUX MYSQL开发环境 笔者使用ubuntu64位LINUX 首先必须保证LINUX可以连互联网. 安装MYSQLsudo apt-get update ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
转自:http://www.tuicool.com/articles/mMrQnu7 一 直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flume+Kafka+Storm ...
- [转]flume-ng+Kafka+Storm+HDFS 实时系统搭建
http://blog.csdn.net/weijonathan/article/details/18301321 一直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flu ...
- Hadoop 笔记1 (原理和HDFS分布式搭建)
1. hadoop 是什么 以及解决的问题 (自行百度) 2.基本概念的讲解 1. NodeName master 节点(NN) 主节点 保存了metaData(元数据信息) 包括文件的owener ...
- HDFS环境搭建(单节点配置)
[参考文章]:hadoop集群搭建(hdfs) 1. Hadoop下载 官网下载地址: https://hadoop.apache.org/releases.html,进入官网根据自己需要下载具体的安 ...
- hadoop3自学入门笔记(2)—— HDFS分布式搭建
一些介绍 Hadoop 2和Hadoop 3的端口区别 Hadoop 3 HDFS集群架构 我的集群规划 name ip role 61 192.168.3.61 namenode,datanode ...
- hadoop3.1.0 HDFS快速搭建伪分布式环境
1.环境准备 CenntOS7环境 JDK1.8-并配置好环境变量 下载Hadoop3.1.0二进制包到用户目录下 2.安装Hadoop 1.解压移动 #1.解压tar.gz tar -zxvf ha ...
- Hadoop HDFS环境搭建
1,首先安装JDK,下面如果JDK出现安装错误,可以卸载 卸载 1.卸载用 bin文件安装的JDK方法: 删除/usr/java目录下的所有东西 2.卸载系统自带的jdk版本方法: 查看自带的jdk: ...
随机推荐
- win7 环境安装Python + IDE(vs2010)开发
1.下载python安装文件 python-2.7.10.msi 网址:https://www.python.org/downloads/release/python-2710/ ,根据自己环境,选择 ...
- A River Runs Through It
Our birth is but a sleep and a forgetting: The Soul that rises with us, our life's Star, ...
- 破解Oracle ERP密码
前提:你有apps的数据库账户,想知道某个用户的密码,因为fnd_user中的密码为加密的,所以无法看懂,你可以尝试用下边的方式来查看用户密码. SQL> desc fnd_user; Name ...
- 导出delphi编写的ios程序在xcode下的日志
- Delphi 动态与静态调用DLL(最好的资料)
摘要:本文阐述了 Windows 环境下动态链接库的概念和特点,对静态调用和动态调用两种调用方式作出了比较,并给出了 Delphi 中应用动态链接库的实例. 一.动态链接库的概念 动态链接库( ...
- oauth入门
oauth可以支持跨网站的数据传输.假设一个用户把照片上传到faji网站,然后想登录到beppa网站(照片打印),把faji的上照片打印出来. 她当然可以自己把照片取下来再上传上去,不过比较麻烦. 使 ...
- Regex Golf练习笔记(1)
正则表达式进阶练习:https://alf.nu/RegexGolf (此练习笔记) 正则表达式验证:https://regexr.com/ (1) (2) 注释:每个词的三个字母在后面重复出现了一 ...
- fast powf
测试结果: sum (fast) in clock 1562sum (fast2) in clock 1407sum (fast3) in clock 3156sum in clock 7797Err ...
- 数据库的完整性约束(ForeignKey ,Unique)
文字转自于 海燕.博客 一.介绍 约束条件与数据类型的宽度一样,都是可选参数 作用:用于保证数据的完整性和一致性主要分为: PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录 ...
- django项目中使用项目环境制作脚本 通过终端命令运行脚本文件
在实际的django项目开发中,有时候需要制作一些脚本文件对项目数据进行处理,然后通过终端命令运行脚本. 完整的实现流程如下: 1.在一个应用目录下(app, 必须是在应用目录下,可以专门创建一个应用 ...