Hive笔记之导出查询结果
一、导出到本地
导出查询结果到本地:
INSERT OVERWRITE LOCAL DIRECTORY "/tmp/hive-result/t_visit_video"
SELECT * FROM t_visit_video ;
导出到的本地路径不必已经存在,会自动创建父目录,导出的查询结果会是一个文件夹,文件夹下存放着本次查询的结果,如果结果集比较大的话会分块存放。
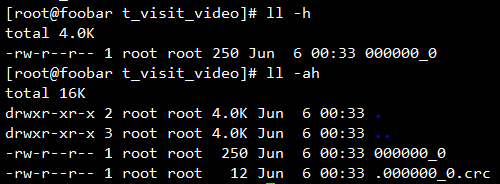
每个数据块还会有一个CRC校验文件,此文件为隐藏文件,用于校验此块的数据有效性。
但是当查看导出的数据文件时发现悲剧了,列与列之间好像是没有东西分隔啊:
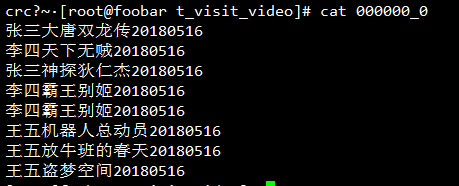
其实是有东西分隔的,这个字符就是^A,只不过这是一个不可见字符,这个字符在vim中可见,使用vim编辑一下它(或者使用cat -A):

看到了,列与列之间确实是有一个^A分隔符的。
如果不希望使用^A作为分隔符,可以在导出数据的时候使用ROW FORMAT DELIMITED FIELDS TERMINITED BY ","来指定列与列之间的分隔符,来重新导出一下:
INSERT OVERWRITE LOCAL DIRECTORY "/tmp/hive-result/t_visit_video_002"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
SELECT * FROM t_visit_video ;
再查看一下导出的本地文件,发现列与列之间的分隔符是逗号了:
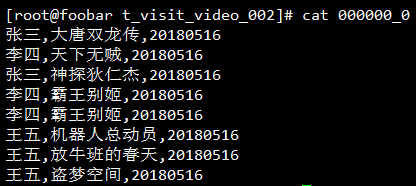
也许你会认为自己已经得到了CSV格式,如果这样的话就踩坑了,因为它并不符合CSV的RFC4180。简单地来证明一下,在上面的表插入一行巨多逗号然后重新导出:
INSERT INTO t_visit_video PARTITION (day="20180604") SELECT "foo,foo,foo", "bar,bar,bar";
INSERT OVERWRITE LOCAL DIRECTORY "/tmp/hive-result/t_visit_video_003"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
SELECT * FROM t_visit_video ;
查看导出结果:
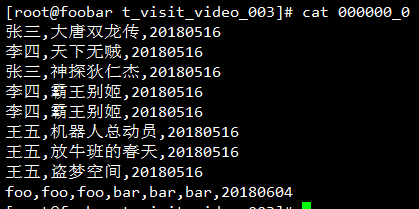
注意看最后一行,如果按照CSV的格式去解析的话最后得到的结果一定是错的,一定要确保所指定的列分隔符不包含在列数据中出现,这是在导出数据指定分隔时需要注意的一个坑。
Hive导出数据时指定分隔符的语法长的令人发指,说实话我是记不住的,这里可以耍个小聪明,可以先将数据按照默认的分隔符^A导出,然后使用tr将^A替换为想要的分隔符:
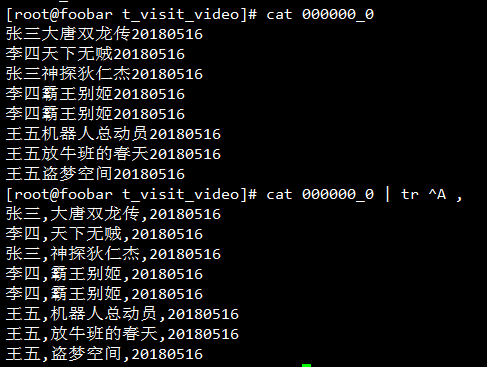
注意这个^V是先按Ctrl+V,告诉终端我下一个字符要输入一个特殊字符,然后按CTRL+A打出。
注:使用默认分隔符导出的Hive查询结果在程序中处理的时候使用split("\x01")或者split("\001")来切分列。
二、导出到HDFS
导出到HDFS跟导出到本地差不多,只是没有LOCAL,加LOCAL后面的是本地路径,否则的话就是HDFS路径:
INSERT OVERWRITE DIRECTORY "/test/hive-export/t_visit_video"
SELECT * FROM t_visit_video;
查看HDFS上导出的目录:
[root@foobar ~]# hadoop fs -ls /test/hive-export/t_visit_video
Found 1 items
-rwxr-xr-x 1 root supergroup 283 2018-06-08 00:04 /test/hive-export/t_visit_video/000000_0
和导出到本地一样,只不过是位置换到了HDFS而已。
同样的,导出到HDFS也可以指定列分隔符:
INSERT OVERWRITE DIRECTORY "/test/hive-export/t_visit_video_002"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
SELECT * FROM t_visit_video;
查看列分隔符是否设置正确:
[root@foobar ~]# hadoop fs -ls /test/hive-export/t_visit_video_002
Found 1 items
-rwxr-xr-x 1 root supergroup 283 2018-06-08 00:12 /test/hive-export/t_visit_video_002/000000_0
[root@foobar ~]# hadoop fs -cat /test/hive-export/t_visit_video_002/000000_0
张三,大唐双龙传,20180516
李四,天下无贼,20180516
张三,神探狄仁杰,20180516
李四,霸王别姬,20180516
李四,霸王别姬,20180516
王五,机器人总动员,20180516
王五,放牛班的春天,20180516
王五,盗梦空间,20180516
foo,foo,foo,bar,bar,bar,20180604
三、导出到其它Hive表
导出到其它表的语法和导出到目录类似,只是目的地变成了表名,如果目标表是个分区表的话还要指定所要插入的分区。
下面是一个简单的例子,先复制一份表结构,然后将其中一个分区的数据拷贝一份:
CREATE TABLE t_visit_video_20180516 LIKE t_visit_video;
INSERT OVERWRITE TABLE t_visit_video_copy PARTITION (day="20180516")
SELECT * FROM t_visit_video WHERE day="20180516";
同样的,这里可以使用INTO表示追加到指定的分区,也可以使用OVERWRITE表示覆盖指定分区。
上面的方式适用于表已经存在的情况,如果想使用一个新表来保存查询结果但是又不想手动创建的话,可以让其自动创建表结构:
CREATE TABLE t_visit_video_20180516 AS SELECT * FROM t_visit_video WHERE day='20180516';
这种方法常用于将查询结果集导出为临时表时使用。
四、定时查询并备份结果集
hive -e可以用来指定一些命令,hive -f可以用来指定一个脚本文件,可以将导出脚本的逻辑写个小脚本,借助于crontab定时执行此脚本,即可实现对Hive表查询并备份。
下面是一个小小的例子,定时将hive表前一天的张三看过的电影导出到某个目录下,同时记录操作日志:
#! /bin/bash day=`date '+%Y%m%d' -d 'day ago'`
if [ $1 ]; then
day=$1
fi
hive="/opt/hive/apache-hive-2.3.3-bin/bin/hive"
dest_dir="/tmp/hive-result/t_visit_video_$day"
log_file="`dirname $0`/backup.log" echo "[`date '+%F %T'`] $day begin bakcup" >> $log_file
hive -e "INSERT OVERWRITE LOCAL DIRECTORY '$dest_dir' SELECT * FROM test_003.t_visit_video WHERE day='$day' AND username='张三'"
echo "[`date '+%F %T'`] $day begin end" >> $log_file
将上面的脚本加入到crontab即可实现定时导出查询结果:
0 1 * * * /root/hive/backup/backup.sh
.
Hive笔记之导出查询结果的更多相关文章
- 笔记-mysql 导出查询结果
语法: The SELECT ... INTO OUTFILE 'file_name' [options] form of SELECT writes the selected rows to a f ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 【转】Impala导出查询结果到文件
[转载出处]http://blog.csdn.net/jobschen/article/details/68942574 想用impala-shell 命令行中将查询的结果导出到本地文件,想当然的以为 ...
- OpenSceneGraph 笔记--如何导出三角形数据
OpenSceneGraph 笔记--如何导出三角形数据 转载:http://blog.csdn.net/pizi0475/article/details/5384389 在OpenSceneGrap ...
- 导出查询结果到excle
实现功能 输入查询结果 点击导出查询结果 导出到excle表.
- MVC学习笔记---MVC导出excel(数据量大,非常耗时的,异步导出)
要在ASP.NET MVC站点上做excel导出功能,但是要导出的excel文件比较大,有几十M,所以导出比较费时,为了不影响对界面的其它操作,我就采用异步的方式,后台开辟一个线程将excel导出到指 ...
- SQL查询(笔记2——实体查询)
SQL查询(笔记2——实体查询) 二.实体查询 如果查询返回了某个数据表的全部数据列,且该数据表有对应的持久化类映射,我们就把查询结果转换成实体查询.将查询结果转换成实体,可以使用SQLQuery提供 ...
- MyBatis:学习笔记(3)——关联查询
MyBatis:学习笔记(3)--关联查询 关联查询 理解联结 SQL最强大的功能之一在于我们可以在数据查询的执行中可以使用联结,来将多个表中的数据作为整体进行筛选. 模拟一个简单的在线商品购物系统, ...
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
随机推荐
- QObject 源代码阅读
我们进入 qt/src 文件夹.你可能对这里的目录名时曾相识,因为几乎这里的所有文件夹名都对应着 Qt 的模块的名字:gui,network,multimedia等等.我们从最核心的 QtCore 开 ...
- ACM数论之旅13---容斥原理(一切都是命运石之门的选择(=゚ω゚)ノ)
容斥原理我初中就听老师说过了,不知道你们有没有听过(/≧▽≦)/ 百度百科说: 在计数时,必须注意没有重复,没有遗漏. 为了使重叠部分不被重复计算,人们研究出一种新的计数方法. 这种方法的基本思想是: ...
- 【Java并发编程】之七:使用synchronized获取互斥锁的几点说明
在并发编程中,多线程同时并发访问的资源叫做临界资源,当多个线程同时访问对象并要求操作相同资源时,分割了原子操作就有可能出现数据的不一致或数据不完整的情况,为避免这种情况的发生,我们会采取同步机制,以确 ...
- mysql内外连接
更新于2017-12-13,在今天的一个面试里面被问到了left/right outer join,回答上来了.但又问了一下inner join ,一下子记不清inner jion是个什么东西了.这次 ...
- Theme Section HDU - 4763(些许暴力)
题意: 求出最长公共前后缀 不能重叠 而且 这个前后缀 在串的中间也要出现一次 解析: 再明确一次next数组的意思:完全匹配的最长前后缀长度 求一遍next 然后暴力枚举就好了 #include ...
- Little Elephant and Array CodeForces - 220B(莫队)
给一段长为n的序列和m个关于区间的询问,求出每个询问的区间中有多少种数字是 该种数字出现的次数等于该数字 的. #include <iostream> #include <cstdi ...
- 【BZOJ4006】【JLOI2015】管道连接
Description 传送门 Solution 题目要求相同颜色的点必须在一个连通块中,但会有多个颜色同属一个连通块使得解更优的情况. 想一想DP能否行得通:设\(g_i\)表示已考虑颜色状态为\( ...
- 毕业设计预习:VHDL入门知识学习(一) VHDL程序基本结构
VHDL入门知识学习(一) VHDL程序基本结构 简介 VHDL程序基本结构 简介 概念: HDL-Hardware Description Language-硬件描述语言-描述硬件电路的功能.信号连 ...
- 一次lvs迁移记录
需求:从117.119.33.99迁移到122.14.206.125,lvs为dr模式,系统版本为debian7 1.安装lvs和keepalived # aptitude install -y ip ...
- Java之JDBC连接池
数据库连接池 连接池的概述 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时, 从容器中获取连接对象,用户访问完之后 ...