Hadoop学习之路(十一)HDFS的读写详解
HDFS的写操作
《HDFS权威指南》图解HDFS写过程
详细文字说明(术语)
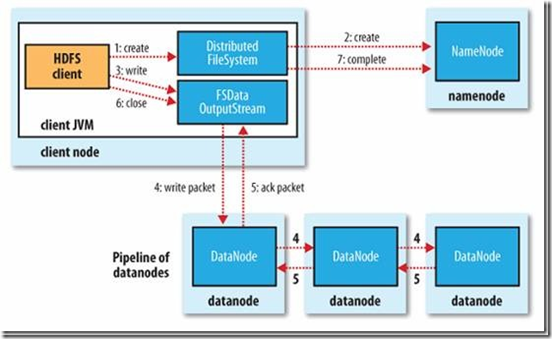
1、使用 HDFS 提供的客户端 Client,向远程的 namenode 发起 RPC 请求
2、namenode 会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会 为文件创建一个记录,否则会让客户端抛出异常;
3、当客户端开始写入文件的时候,客户端会将文件切分成多个 packets,并在内部以数据队列“data queue(数据队列)”的形式管理这些 packets,并向 namenode 申请 blocks,获 取用来存储 replicas 的合适的 datanode 列表,列表的大小根据 namenode 中 replication 的设定而定;
4、开始以 pipeline(管道)的形式将 packet 写入所有的 replicas 中。客户端把 packet 以流的 方式写入第一个 datanode,该 datanode 把该 packet 存储之后,再将其传递给在此 pipeline 中的下一个 datanode,直到最后一个 datanode,这种写数据的方式呈流水线的形式。
5、最后一个 datanode 成功存储之后会返回一个 ack packet(确认队列),在 pipeline 里传递 至客户端,在客户端的开发库内部维护着"ack queue",成功收到 datanode 返回的 ack packet 后会从"data queue"移除相应的 packet。
6、如果传输过程中,有某个 datanode 出现了故障,那么当前的 pipeline 会被关闭,出现故 障的 datanode 会从当前的 pipeline 中移除,剩余的 block 会继续剩下的 datanode 中继续 以 pipeline 的形式传输,同时 namenode 会分配一个新的 datanode,保持 replicas 设定的 数量。
7、客户端完成数据的写入后,会对数据流调用 close()方法,关闭数据流;
8、只要写入了 dfs.replication.min(最小写入成功的副本数)的复本数(默认为 1),写操作 就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication 的默认值为 3),因为 namenode 已经知道文件由哪些块组成,所以它在返回成功前只需 要等待数据块进行最小量的复制。
详细文字说明(口语)
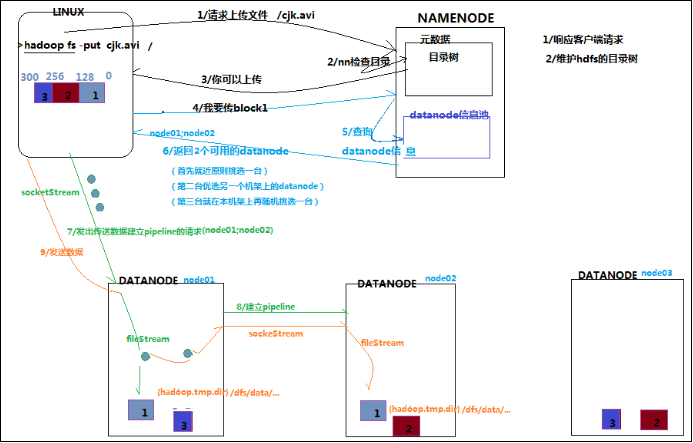
1、客户端发起请求:hadoop fs -put hadoop.tar.gz /
客户端怎么知道请求发给那个节点的哪个进程?
因为客户端会提供一些工具来解析出来你所指定的HDFS集群的主节点是谁,以及端口号等信息,主要是通过URI来确定,
url:hdfs://hadoop1:9000
当前请求会包含一个非常重要的信息: 上传的数据的总大小
2、namenode会响应客户端的这个请求
namenode的职责:
1 管理元数据(抽象目录树结构)
用户上传的那个文件在对应的目录如果存在。那么HDFS集群应该作何处理,不会处理
用户上传的那个文件要存储的目录不存在的话,如果不存在不会创建
2、响应请求
真正的操作:做一系列的校验,
1、校验客户端的请求是否合理
2、校验客户端是否有权限进行上传
3、如果namenode返回给客户端的结果是 通过, 那就是允许上传
namenode会给客户端返回对应的所有的数据块的多个副本的存放节点列表,如:
file1_blk1 hadoop02,hadoop03,hadoop04
file1_blk2 hadoop03,hadoop04,hadoop05
4、客户端在获取到了namenode返回回来的所有数据块的多个副本的存放地的数据之后,就可以按照顺序逐一进行数据块的上传操作
5、对要上传的数据块进行逻辑切片
切片分成两个阶段:
1、规划怎么切
2、真正的切物理切片: 1 和 2
逻辑切片: 1
file1_blk1 : file1:0:128
file1_blk2 : file1:128:256
逻辑切片只是规划了怎么切
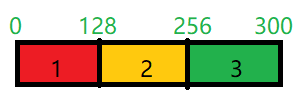
6、开始上传第一个数据块
7、客户端会做一系列准备操作
1、依次发送请求去连接对应的datnaode
pipline : client - node1 - node2 - node3
按照一个个的数据包的形式进行发送的。
每次传输完一个数据包,每个副本节点都会进行校验,依次原路给客户端
2、在客户端会启动一个服务:
用户就是用来等到将来要在这个pipline数据管道上进行传输的数据包的校验信息
客户端就能知道当前从clinet到写node1,2,3三个节点上去的数据是否都写入正确和成功
8、clinet会正式的把这个快中的所有packet都写入到对应的副本节点
1、block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,2.x版本默认是128M;注:这个参数由客户端配置决定;如:System.out.println(conf.get("dfs.blocksize"));//结果是134217728
2、packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
如:System.out.println(conf.get("dfs.write.packet.size"));//结果是65536
3、chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
如:System.out.println(conf.get("io.bytes.per.checksum"));//结果是512
9、clinet进行校验,如果校验通过,表示该数据块写入成功
10、重复7 8 9 三个操作,来继续上传其他的数据块
11、客户端在意识到所有的数据块都写入成功之后,会给namenode发送一个反馈,就是告诉namenode当前客户端上传的数据已经成功。
HDFS读操作
《HDFS权威指南》图解HDFS读过程
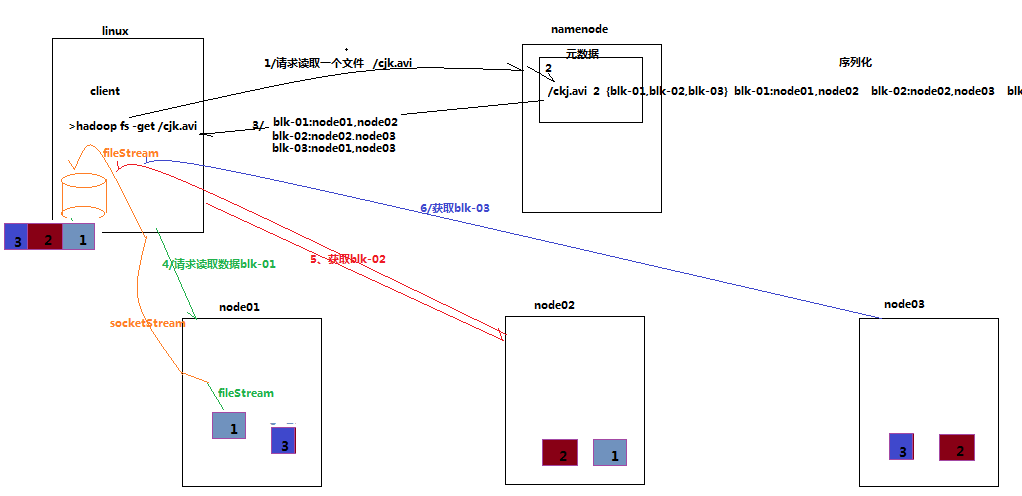
数据读取
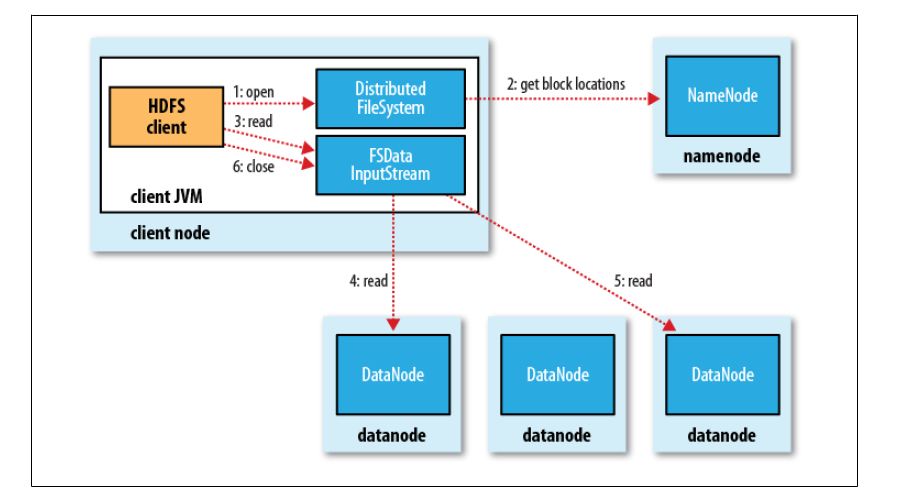
1、客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream。
2、通过RPC 远程调用NameNode ,获得NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置( 主要是各DataNode的地址) 。
3、获得输入流之后,客户端调用read 方法读取数据。选择最近的DataNode 建立连接并读取数据。
4、如果客户端和其中一个DataNode 位于同一机器(比如MapReduce 过程中的mapper 和reducer),那么就会直接从本地读取数据。
5、到达数据块末端,关闭与这个DataNode 的连接,然后重新查找下一个数据块。
6、不断执行第2 - 5 步直到数据全部读完。
7、客户端调用close ,关闭输入流DF S InputStream。
Hadoop学习之路(十一)HDFS的读写详解的更多相关文章
- Hadoop学习之路(8)Yarn资源调度系统详解
文章目录 1.Yarn介绍 2.Yarn架构 2.1 .ResourceManager 2.2 .ApplicationMaster 2.3 .NodeManager 2.4 .Container 2 ...
- Hadoop学习(四) FileSystem Shell命令详解
FileSystem Shell中大多数命令都和unix命令相同,只是两者之间的解释不同,如果你对unix命令有基本的了解,那么对于FileSystem Shell的命令,你将会感到很亲切. appe ...
- Webwork 学习之路【04】Configuration 详解
Webwork做为经典的Web MVC 框架,个人觉得源码中配置文件这部分代码的实现十分考究. 支持自定义自己的配置文件.自定义配置文件读取类.自定义国际化支持. 可以作为参考,单独引入到其他项目中, ...
- robot framework学习笔记之十一--第三方库requests详解
一.安装 Requests 通过pip安装 pip install requests 或者,下载代码后安装: $ git clone git://github.com/kennethreitz/req ...
- Docker学习之路(二)DockerFile详解
Dockerfile是一个镜像的表示,可以通过Dockerfile来描述构建镜像的步骤,并自动构建一个容器 所有的 Dockerfile 命令格式都是: INSTRUCTION arguments 虽 ...
- 性能测试学习之路 (二)jmeter详解(jmeter执行顺序 && 作用域 && 断言 && 事务 &&集合点 )
1 Jmeter 工作区介绍 jmeter工作区分为3个部分:目录树.测试计划编辑区域.菜单栏. 2 Jmeter 执行顺序规则 Jmeter执行顺序规则如下: 配置元件 前置处理器 定时器 采样器s ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
随机推荐
- Recommend ways to overwrite hashCode() in java
Perface In the former chapter, I talk about topics about hashCode, And I will continue to finish the ...
- 基于jQuery的软键盘
基于jQuery的软键盘 前些天写了一个基于基于jQuery的数字键盘,今天给大家带来一个基于jQuery的全字母键盘插件(支持全字母大小写切换,数字输入,退格清除,关闭功能,可调整大小和键盘位置 ...
- java.lang.IllegalStateException: Mapped class was not specified
错误如下:java.lang.IllegalStateException: Mapped class was not specifiedat org.springframework.util.Asse ...
- webapi 后台跳转 后台输出html和script
1.跳转 [HttpGet]public HttpResponseMessage LinkTo(){ HttpResponseMessage resp = new HttpResponseMessag ...
- 用jquery实现带左右按键的轮播图
成品如下: 简单来说就是点击“右”按钮时,转换到右边的下一幅图片,同时上面的小方块颜色也跟着改变,如果已经是最后一幅图片,再点击“右”,则转换到第一幅图片,是直接向左移找到第一幅图的,明天再做一下无缝 ...
- Web 系统架构一般组成
负载层技术 负载分配层,是单指利用软件实现的计算机系统上的狭义负载均衡.它是根据业务形态设计一种架构方式,将来自外部客户端的业务请求分担到每一个可用的业务节点上 . 1.用户终端不只包括类 ...
- 11招教你做好 ERP 系统维护
ERP 维护的具体工作内容主要包括以下几个方面: 例行和突发事件的处理 以管理和技术的手段,维护和发展 ERP 运行环境,如平衡技术先进性/实用风险.目标/成本而进行的IT基础结构(服务器.网络.PC ...
- Android埋点技术分析
1.现有的几种埋点技术的实现原理和优劣分析 (1)代码埋点:将收集数据的代码直接写在需要的地方,当用户点击某个控件或者打开某个页面时调用到该部分代码完成数据的收集. 优势:准确性高,收集数据和发送数据 ...
- Centos 安装Dokuwiki
一.前言 DokuWiki是一个开源wiki引擎程序,运行于PHP环境下.DokuWiki程序小巧而功能强大.灵活,适合中小团队和个人网站知识库的管理. 二.环境 在centos6 下安装apache ...
- 如何在 Azure 中均衡 Linux 虚拟机负载以创建高可用性应用程序
负载均衡通过将传入请求分布到多个虚拟机来提供更高级别的可用性. 本教程介绍了 Azure 负载均衡器的不同组件,这些组件用于分发流量和提供高可用性. 你将学习如何执行以下操作: 创建 Azure 负载 ...