从一个简单的寻路问题深入Q-learning
这第一篇随笔实际上在我的科学网博客上是首发,我重新拿到博客园再发一次是希望以此作为我学习Q-learning的一个新的开始。以后这边主技术,科学网博客主理论。我也会将科学网那边技术类的文章转过来的。希望大家关注一下:http://blog.sciencenet.cn/home.php?mod=space&uid=3189881&do=blog&id=1116209
本篇文章代码请参考:https://github.com/JinyuGuan/Q-learning-Path-Finding.git
问题描述:
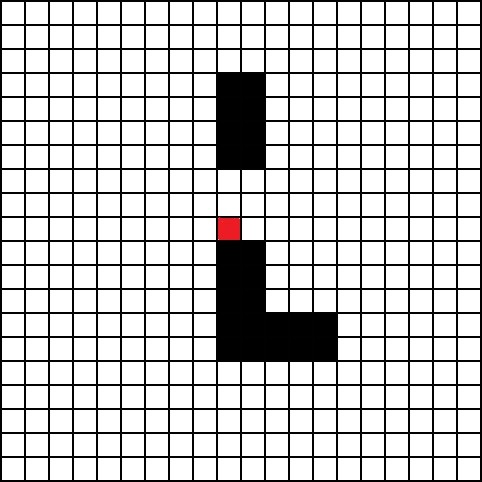
如图所示,宝藏在红色方块处,黑色方块为障碍物。在起点已确定的前提下,找到一条去往红色方块的最近路线(起点可以是图上任意一个方块)。
解决思路:
最核心的思想来源于我的上一篇文章【Q-learning系列】解决“房间问题”的一个通用方法 ,如果可以的话,最好先了解一下。下面我就对从整体上总结一下如何利用Q-learning去解决这么一个简单的寻路问题。
对地图重采样,将482x482的地图简化为一个20x20的矩阵,其中1表示无障碍可通行方块,0表示不可通行方块。
对图中的每一个方格做状态编号。计算PossibleAction矩阵,即每一个状态所对应的动作的可行性的集合。其动作值可行时为1,不可行时为0。总共可行的动作有上下左右四种。
利用PossibleAction矩阵计算奖励矩阵,可通行到红色方块的动作值奖励100,其余可行的动作值奖励为0,不可通行的奖励为-1。
将PossibleAction矩阵和奖励矩阵带入,开始进行Q-learning。
Q-learning结束后计算产生Q-Table,从某一个状态开始,找寻Q-Table中值最大所对应的动作,得到下一个状态,以此循环,最终到达红色方块,即为最短路线。
用20x20的矩阵标记出走过的轨迹,再将其还原为482x482的图片显示出来。
那我们就先上结果吧,这样看着比较直观,左图起点为左上角的方块,坐标为(1, 1),沿着最短路线到达终点,红色方块。右图起点为下方偏右的方块,坐标为(14, 16):


接下来我们再对这个解决思路的实现进行逐条解释,所遇到的问题进行逐个解决。
问题分析与方法实现:
首先是第一条,对地图的重采样。这个很简单,先检测一个格子的像素数,采样点就放在每个格子的中心位置。这里每个格子是由24x24个像素点组成,共有20x20个格子,还有两个2x480个像素点是边框的黑线。对于一个24x24的格子来说,中心位置就是坐标(13, 13),所以在遍历482x482个像素点时,假设每个像素点的坐标为(x, y),中心点坐标(Px, Py)一定满足(mod为取余计算):
二、三两点实际上可以整合到第四点,也就是说PossibleAction矩阵和Reward矩阵(奖励矩阵)可以不进行单独计算,在Q-learning的过程中也可进行赋值,其本质上就是动态Q-Table的计算处理,日后有机会在做展开,这里讨论的依然限制在严格Q-Table的计算中,也就是说Q-Table的size是固定的,状态的数量也是固定的,像对于这个有着20x20个方格学习的实例,有且只有400个状态。显然,Q-Table的size就是400x4,PossibleAction矩阵和奖励矩阵同样也为400x4。
这里必须要讨论的一点就是PossibleAction矩阵和奖励矩阵之间的关系。PossibleAction矩阵的4列表示4种可行的动作,每一行表示当前所处的状态。举个例子,如下给出一个400x4的PossibleAction矩阵:
在这个PossibleAction矩阵中,UDLR分别为up, down, left, right,即为上下左右四个动作。如若当前状态为1,做向上移动的动作,可以表示为PossibleAction(state = 1, action = U) = 0,结果为0表示不可行。如若当前状态为1,做向下移动的动作,PossibleAction(state = 1, action = D) = 1,结果为1表示可行。这里使用图像表示或更为直观,图中清楚的表示出了处于状态1只可向下或向右移动。

奖励矩阵(Reward Matrix)和PossibleAction矩阵的维度相同,且行列意义相同,但矩阵内的值不同。这里我们实行一种最简单的奖励策略。这里我们用R(i, j)表示奖励矩阵中的第i行第j列的元素之值,“i”表示第i个状态,“j”表示动作j。
不难看出,R(state, action) = -1或0的情况与PossibleAction(state, action) = 0或1的情况是有重叠的,且满足前一种情况的state和action是满足后一种情况的state和action的子集。Reward矩阵和PossbleAction矩阵最大的不同点在于,可以到达目标的状态动作的Reward值为100,而对于PossibleAction而言只是一个可行的状态动作而已,值依旧为1。这个区别也是Q-learning中的Q-Table可以收敛的重要依据之一。如果我们使用图示的方法来表述就更为直观了。
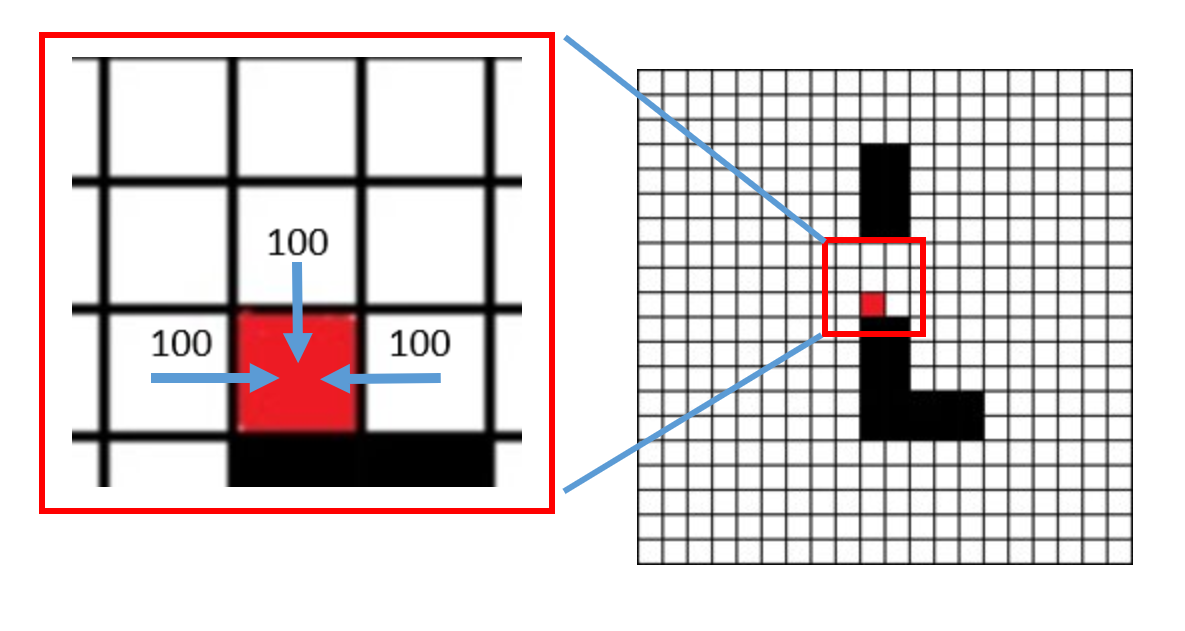
如图所示,只有这三种情况的Reward值可以为100。为什么说这样的奖励策略可以使得所有状态的Q值的最大值收敛于一个最佳的可行的动作上。事实上,这里可以分割为两个问题:
为什么要讨论Q的最大值?
为什么这样可以收敛?
Q-learning的本质:
这就牵涉到了Q-learning的本质机理。我们先来解决第一个问题,解题思路中的第5点提到Q-Table中任意一个状态的所有动作中Q值最大的那个动作就是为了达到目标在当前状态下的最佳选择。所以当状态S的Q最大值收敛于动作A,那么动作A就是处于状态S的最佳选择。当然在理解了第二个问题的原理后,对一个问题也会有更深层的认识。在对第二个问题的解释之前,我们先做一个Q-learning探索者的模拟。模拟过程也是迭代过程的一部分。事实上,Q-learning中的Q-Table计算的迭代过程基本分为四个阶段:
第一阶段,探索者未接触过目标。在这一阶段,探索者的工作是无效的,也就是说无论探索者移动到何处,Q-Table中所有的值都为0。
第二阶段,探索者接触到了目标,但Q-Table中的最大值还未收敛。
第三阶段,目标点周围的状态点的Q值已经收敛完成,但并非所有状态的Q值都收敛了。
第四阶段,所有状态的Q值收敛,Q-learning完成。
我们着重讨论从第二阶段到第三阶段的过程,也就是Q值收敛的过程。迭代中的Q-Table的更新原则如下(在公式中,使用矩阵Q(s, a)表示Q-Table,sf和af表示下个状态动作集):
基于这种Q-Table的刷新原则,在状态S下,新的Q值与之前的Q值没有任何直接的关系,我们姑且将其称之为无记忆刷新策略。接下来,依据无记忆刷新策略,从Q-Table值变化的第一步开始模拟。

第1步,从探索者处于状态S1,选择向下动作。下个状态即为目标状态,我们用St表示目标状态,Q(St, Any Action) = 0,依据无记忆刷新策略,可以得出,Q(S1, D) = R(S1, D) = 100。
第2步,当探索者离开状态St到再次进入状态St之前,Q(S1, All Actions)的最大值都不会变化,但当探索者处于S2,选择向左动作,下个状态即为S1,Q(S1, All Action)的最大值为Q(S1, D),依据无记忆刷新策略并假设gamma=0.8(gamma一定是小于1的),可以有:
第3步,类似的,计算出Q(S3, U) = 64
第4步,当探索者处于S3,选择向左动作,重新回到目标状态St,和第一步类似,可以求得Q(S3, L) = 100
第5步,还是step4,探索者回到目标状态St后,选择向右移动,下个状态即为S3,Q(S3, Actions)的最大值为Q(S3, L) = 100,那么和第二步类似,可以求得Q(St, R) = 80。
第6步,当探索者又处在状态S1,选择向下动作后,下一状态的Q(St, Actions)的最大值就变成了Q(St, R),依据无记忆刷新策略,可以有:
如此从第1步到第6步,我们便完成了一个简单的对Q(S1, D)计算的一次循环过程。重复第1到第6步多次后,Q(S1, D)便可以收敛。如果,探索者的动作选择是完全随机的,第n次刷新的Q(S1, D),Q(St, R)和Q(S3, L)之间一定存在如下关系:
联立上述的三个等式,可以得出:
很显然,Q(S1, D)是一个等比数列,可以求出其通项,已知在Q(S1, D)的初值是100,可得:
当n趋于正无穷时,也就是随着迭代次数的增加,毫无疑问地,Q(S1, D)的值是收敛的。当gamma值为0.8时,可以计算出,Q(S1, D)收敛于277.78,并且这里需要强调一点,状态S1周边的4个状态,比如S2和St都会收敛于状态S1的Q值最大值的0.8倍,以此类推到所有的400个状态,下图给出了每个方格Q峰值的分布图,左图为目标状态坐标(10,10)的情形,右图为目标状态坐标(3, 16)的情形,图中的红框即是目标状态点,图像颜色由黑到白表示出Q峰值由小到大。
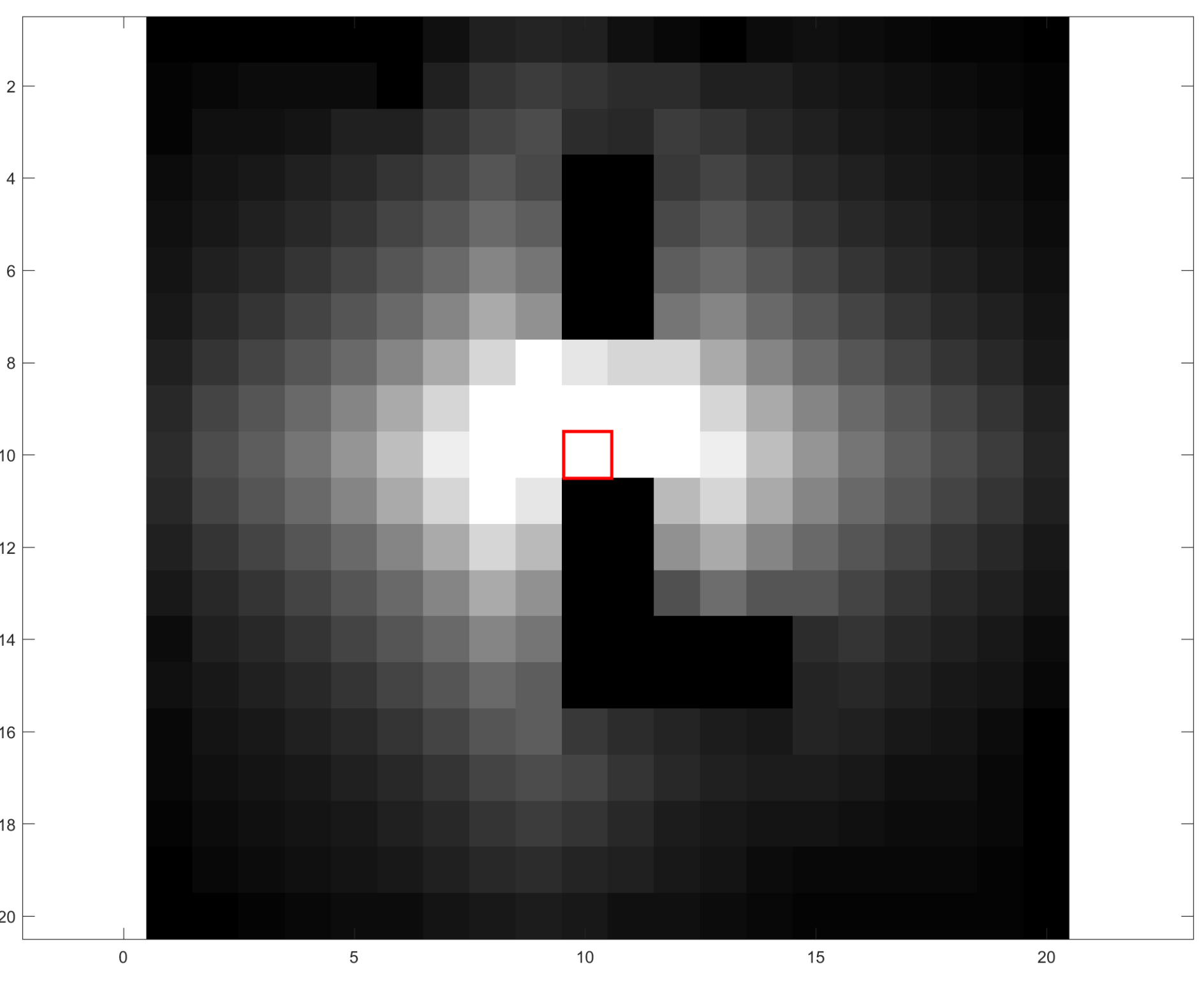
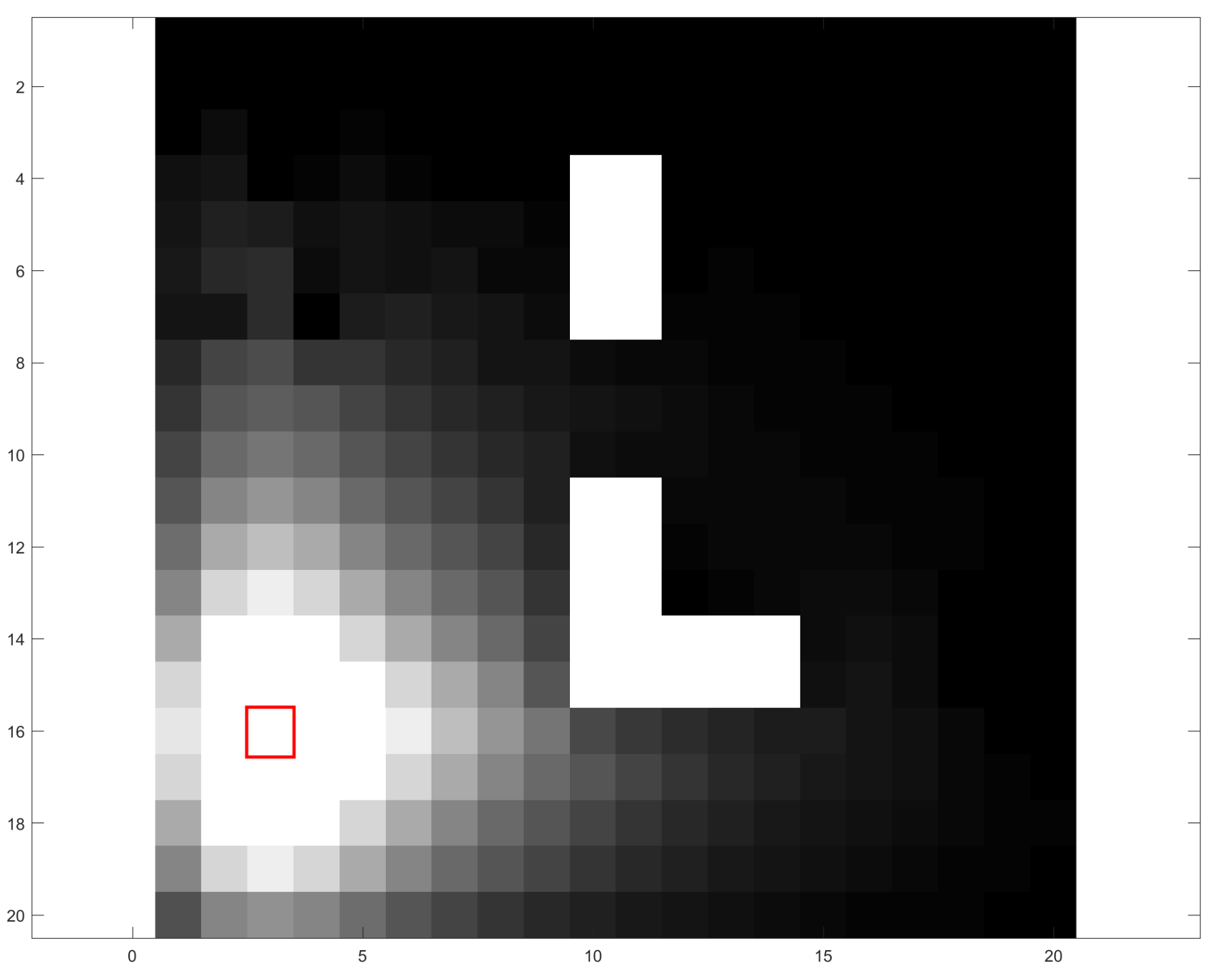
注:左图中的纯黑块和右图中的纯白块为障碍块
这两幅图直观的解释了Q-Table解决寻路问题的终极机理。无论起点在哪,只要沿着比当前状态的Q值高的状态前进,一定会找到目标,而且一定是最近的路线。
本篇使用的是无记忆刷新策略,下一篇文章主要对象依旧是“寻路问题”,将会探讨一下新的Q-Table的刷新策略。
从一个简单的寻路问题深入Q-learning的更多相关文章
- 如何写一个简单的http服务器
最近几天用C++写了一个简单的HTTP服务器,作为学习网络编程和Linux环境编程的练手项目,这篇文章记录我在写一个HTTP服务器过程中遇到的问题和学习到的知识. 服务器的源代码放在Github. H ...
- 理解与模拟一个简单web服务器
先简单说下几个概念,根据自己的理解,不正确请见谅. web服务器 首先要知道什么是web服务器,简单说web服务器就是可以使用HTTP传输协议与客户端进行通信的服务器.最初的web服务器只能用来处理静 ...
- 一个简单的Promise 实现
用了这么长时间的promise,也看了很多关于promise 的文章博客,对promise 算是些了解.但是要更深的理解promise,最好的办法还是自己实现一个. 我大概清楚promise 是对异步 ...
- Linux内核分析第三周学习总结:构造一个简单的Linux系统MenuOS
韩玉琪 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.Linux内 ...
- avalon实现一个简单的带增删改查的成绩单
自从angular问世,一直就有去了解学习angular,一直想用angular去做一个项目,但无奈,大ng是国外产物,ng1.2版本就只兼容到IE8,1.3后的几个版本提升到IE9,据说NG2.0更 ...
- js 排列 组合 的一个简单例子
最近工作项目需要用到js排列组合,于是就写了一个简单的demo. 前几天在网上找到一个写全排列A(n,n)的code感觉还可以,于是贴出来了, 排列的实现方式: 全排列主要用到的是递归和数组的插入 比 ...
- ADF_General JSF系列1_创建一个简单的JSF Application
2015-02-17 Creatd By BaoXinjian
- [Ruby on Rails系列]6、一个简单的暗语生成器与解释器(上)
[0]Ruby on Rails 系列回顾 [Ruby on Rails系列]1.开发环境准备:Vmware和Linux的安装 [Ruby on Rails系列]2.开发环境准备:Ruby on Ra ...
- 使用 ADD-ON SDK 开发 基于 Html JQuery 和 CSS 的 firefox 插件入门教程1: 创建一个简单的 Add-on
[本文转载自http://sixpoint.me/942/implementing-simple-addon/] 实现一个简单的插件 教程的这个部分带你使用 SDK 来实现, 运行并打包一个插件. 这 ...
随机推荐
- jQuery全选反选插件
(function($){ $.fn.check = function(options){ var options = $.extend({ element : "input[name='n ...
- windows 下搭建git服务器,及问题处理。
最近要做一个源码管理服务器,权衡了一下还是git最适合,搭建服务器前看了网上一些windows下搭建git服务器的帖子,感觉还比较简单,没有太多需要配置的地方,于是开始动手. 我选择的是 gitfor ...
- Nginx如何配置静态文件直接访问
其实前面在这篇文章Nginx之动静分离中已经提到过如何配置静态文件直接访问,今天突然再写是因为之前写的不够完善,所以这一篇文章你可以理解为是在前一个基础上的扩展. 之所以下午临时想到这个,是因为之前搭 ...
- 初识Qt文字绘制
1.新建一个Qt Gui应用,项目名称为myDraw,基类选择为QMainWindow,类名设置为MainWindow. 2.在mainwindow.h头文件中添加void paintEvent(QP ...
- Kafka设计解析(十二)Kafka 如何读取offset topic内容 (__consumer_offsets)
转载自 huxihx,原文链接 Kafka 如何读取offset topic内容 (__consumer_offsets) 众所周知,由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka ...
- 两个Integer比较大小需要注意的误区
通过下面的例子,来了解integer比较大小需注意的几点. eg.定义Integer对象a和b,比较两者结果为:a不等于b Integer a = 1; Integer b = 1; if(a==b) ...
- block本质探寻三之block类型
一.oc代码 提示:看本文章之前,最好按顺序来看: //代码 void test1() { ; void(^block1)(void) = ^{ NSLog(@"block1----&quo ...
- Math(初学)
package day01; public class Case12 { public static void main(String[] args) { System.out.println(Mat ...
- jQuery----选择器(重点是层次选择器)
基本选择器 1.id选择器 ---------------------------->根据id来获取,只有一个.---------------------------------------- ...
- dataTable配置项说明
Datatables是一款jquery表格插件.它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能. 官网地址:https://datatables.net/ 中文说明地址:http:/ ...