3、计数排序,电影top100
1、计数排序



# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 11:32
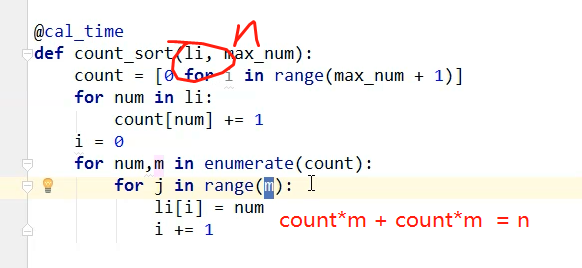
# @Author : Venicid def count_sort(li, max_num):
count = [0 for i in range(max_num + 1)]
for num in li:
count[num] += 1
i = 0
for num, m in enumerate(count):
for j in range(m):
li[i] = num
i += 1 import random
data = []
for i in range(100000):
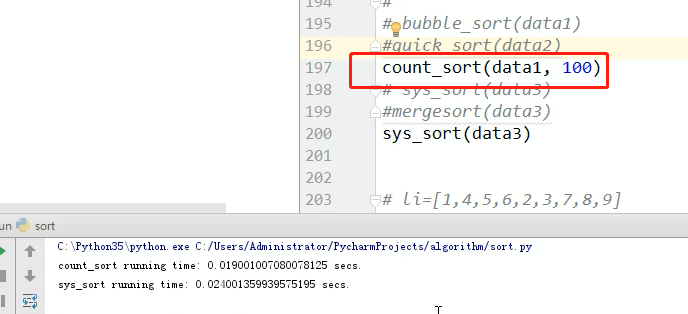
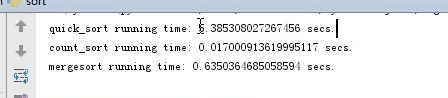
data.append(random.randint(0,100)) count_sort(data, 100)
print(data)
计数排序这么快,为什么不用计数排序呢?因为他是有限制的,你要知道列表中的最大数
如果一下来了一个很大的数,比如10000,那么占的空间就的这么大,
计数排序占用的空间和列表的范围有关系
解决这种问题的方法,可以用桶排序,都放进去可以在进行其他的排序。比如插入排序。
2、TOP10榜单:topk

(1)方式1:思路:插入排序 O(kn)
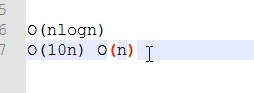







# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 11:59
# @Author : Venicid def insert(li, i):
"""一次insert"""
tmp = li[i]
j = i - 1
while j >= 0 and li[j] > tmp:
li[j + 1] = li[j]
j = j - 1
li[j + 1] = tmp def insert_sort(li):
for i in range(1, len(li)): # 从第二个位置,即下标为1的元素开始向前插入
insert(li,i) def topk(li, k):
top = li[0:k + 1] # top10, 多开辟一个存放,新进来的数据
insert_sort(top)
for i in range(k + 1, len(li)):
top[k] = li[i]
insert(top, k)
return top[:-1] # 去掉最后一个 import random
data = list(range(20))
topk_ = random.shuffle(data)
print(data) print(topk(data, 10))

(2)方式2:堆的应用:nlogk

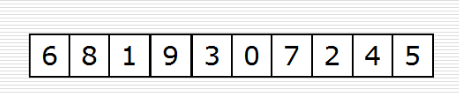
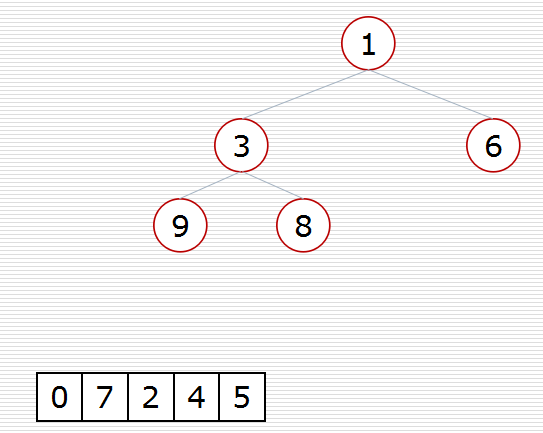
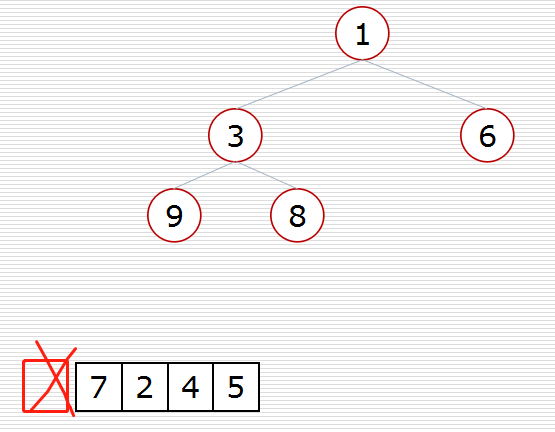
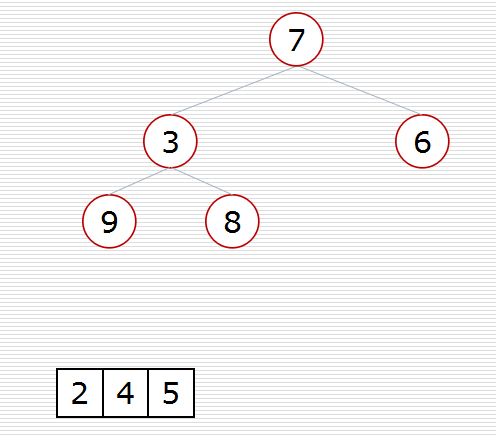
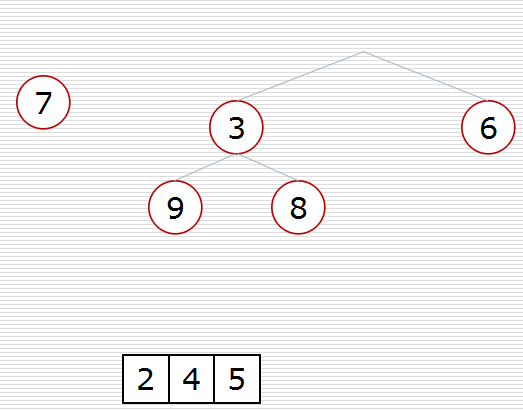
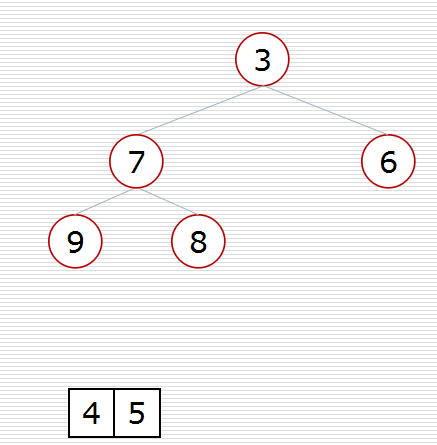
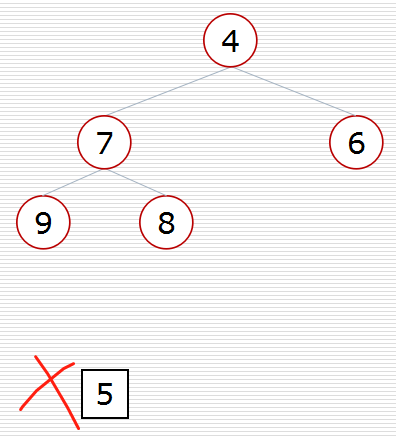
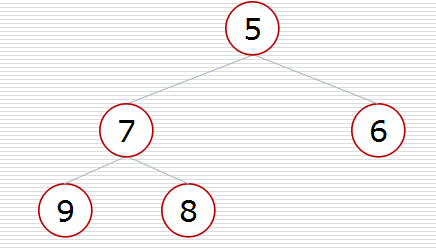
def sift(data, low, high):
"""调整"""
i = low # 父亲的位置
j = 2 * i + 1 # 孩子的位置
tmp = data[i] # 原省长退休
while j <= high: # 孩子在堆里
if j + 1 <= high and data[j] < data[j + 1]: # if右孩子存在且右孩子更大
# if j + 1 <= high and data[j] > data[j + 1]: # if右孩子存在且右孩子更大
j += 1
if data[j] > tmp: # 孩子比最高领导大
# if data[j] < tmp: # 孩子比最高领导大
data[i] = data[j] # 孩子上移一层
i = j # 孩子成为新父亲
j = 2 * i + 1 # 新孩子
else:
break
data[i] = tmp # 省长放到对应的位置上(村民/叶子节点) def topn(li, n):
heap = li[0:n]
# 建堆
for i in range(n // 2 - 1, -1, -1):
sift(heap, i, n - 1) # 遍历
for i in range(n, len(li)):
if li[i] < heap[0]:
# if li[i] > heap[0]:
heap[0] = li[i]
sift(heap, 0, n - 1)
for i in range(n - 1, -1, -1): # i指向堆的最后
heap[0], heap[i] = heap[i], heap[0] # 领导退休,刁民上位
sift(heap, 0, i - 1) # 调整出新领导
return heap import random data = list(range(20))
topk_ = random.shuffle(data)
print(data) print(topn(data, 10))

3、heapq实现堆排序


python官方文档
https://docs.python.org/3/library/index.html



# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 15:07
# @Author : Venicid import heapq
import random h = []
data = list(range(10000))
random.shuffle(data)
# heapq.heappush(h,1) # [1] # 生成小栈堆
for num in data:
heapq.heappush(h, num)
print(h) #[0, 1, 2, 4, 3, 5, 7, 8, 6, 17, # 出数
for i in range(len(h)):
print(heapq.heappop(h)) # top最大 top最小的
print(heapq.nsmallest(10, data))
print(heapq.nlargest(10, data))


3、计数排序,电影top100的更多相关文章
- requests+正则表达式提取猫眼电影top100
#requests+正则表达式提取猫眼电影top100 import requests import re import json from requests.exceptions import Re ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 计数排序(counting-sort)——算法导论(9)
1. 比较排序算法的下界 (1) 比较排序 到目前为止,我们已经介绍了几种能在O(nlgn)时间内排序n个数的算法:归并排序和堆排序达到了最坏情况下的上界:快速排序在平均情况下达到该上界. ...
- 计数排序和桶排序(Java实现)
目录 比较和非比较的区别 计数排序 计数排序适用数据范围 过程分析 桶排序 网络流传桶排序算法勘误 桶排序适用数据范围 过程分析 比较和非比较的区别 常见的快速排序.归并排序.堆排序.冒泡排序等属于比 ...
- CF 375B Maximum Submatrix 2[预处理 计数排序]
B. Maximum Submatrix 2 time limit per test 2 seconds memory limit per test 512 megabytes input stand ...
- 计数排序-java
今天看了一本书,书里有道题,题目很常见,排序,明了点说: 需求:输入:最多有n个正整数,每个数都小于n, n为107 ,没有重复的整数 输出:按升序排列 思路:假设有一组集合 {1,3,5,6,11, ...
- 计数排序 + 线段树优化 --- Codeforces 558E : A Simple Task
E. A Simple Task Problem's Link: http://codeforces.com/problemset/problem/558/E Mean: 给定一个字符串,有q次操作, ...
- 计数排序算法——时间复杂度O(n+k)
计数排序 计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出.它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于 ...
随机推荐
- MySQL案例07:MySQL5.7并发复制隐式bug
我们MySQL线上环境大部分使用的是5.7.18的版本,这个版本已修复了很多bug,但针对主从复制的bug还是有很多的,尤其是一些组复制.并行复制的bug尤为突出,在5.7.19版本有做相应改善和修复 ...
- 《SQL Server 2008从入门到精通》--20180628
数据库基本概念:区.页.行 区:SQL Server中管理空间的基本单位.一个区大小为64KB,是八个物理上连续的页.SQL Server中每MB有16个区.一旦一个区被存储满,SQL Server将 ...
- 固定UIScrollView滑动的方向
固定UIScrollView滑动的方向 一般而言,我们通过这两个参数CGRectMake以及contentSize就可以自动的让UIScrollView只往一个方向滚动.但我遇到过非常奇葩的情况,那就 ...
- IIS6与IIS7中的w3wp工作进程
在IIS6中,每一个网站都有对应的应用程序池,在应用程序池有运行着网站的Application,在默认情况下,所有的网站的应用程序都会分配到默认的应用程序池当中, 当然,我们可以新建一个应用程序池 ...
- zabbix日常监控项java(四又分之一)
因zabbix自带监控JMX的模板通用性差的问题,需要我们自己新建一个属于自己的模板,于是本文就出现了.... 大部分都是参考网上其他博主的文档,在此作为梳理.总结:以方便自己日后使用查询.
- [EffectiveC++]item43:学习处理模板化基类内的名称
- python3: 字符串和文本(2)
6. 字符串忽略大小写的搜索替换 >>> text = 'UPPER PYTHON, lower python, Mixed Python' >>> re.find ...
- RabbitMQ学习以及与Spring的集成(三)
本文介绍RabbitMQ与Spring的简单集成以及消息的发送和接收. 在RabbitMQ的Spring配置文件中,首先需要增加命名空间. xmlns:rabbit="http://www. ...
- 前端面试总结——http、html和浏览器篇
1.http和https https的SSL加密是在传输层实现的. (1)http和https的基本概念 http: 超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和 ...
- 【[HNOI2016]序列】
莫队好题啊 莫队来做这个题的难点就是考虑如何在\(O(1)\)时间内由\([l,r]\)转移到\([l,r+1]\) 显然加入\(r+1\)这个数之后会和之前所有的位置都产生一个区间,就是要去快速求出 ...